




先放上pyspark.sql.DataFrame的函数汇总
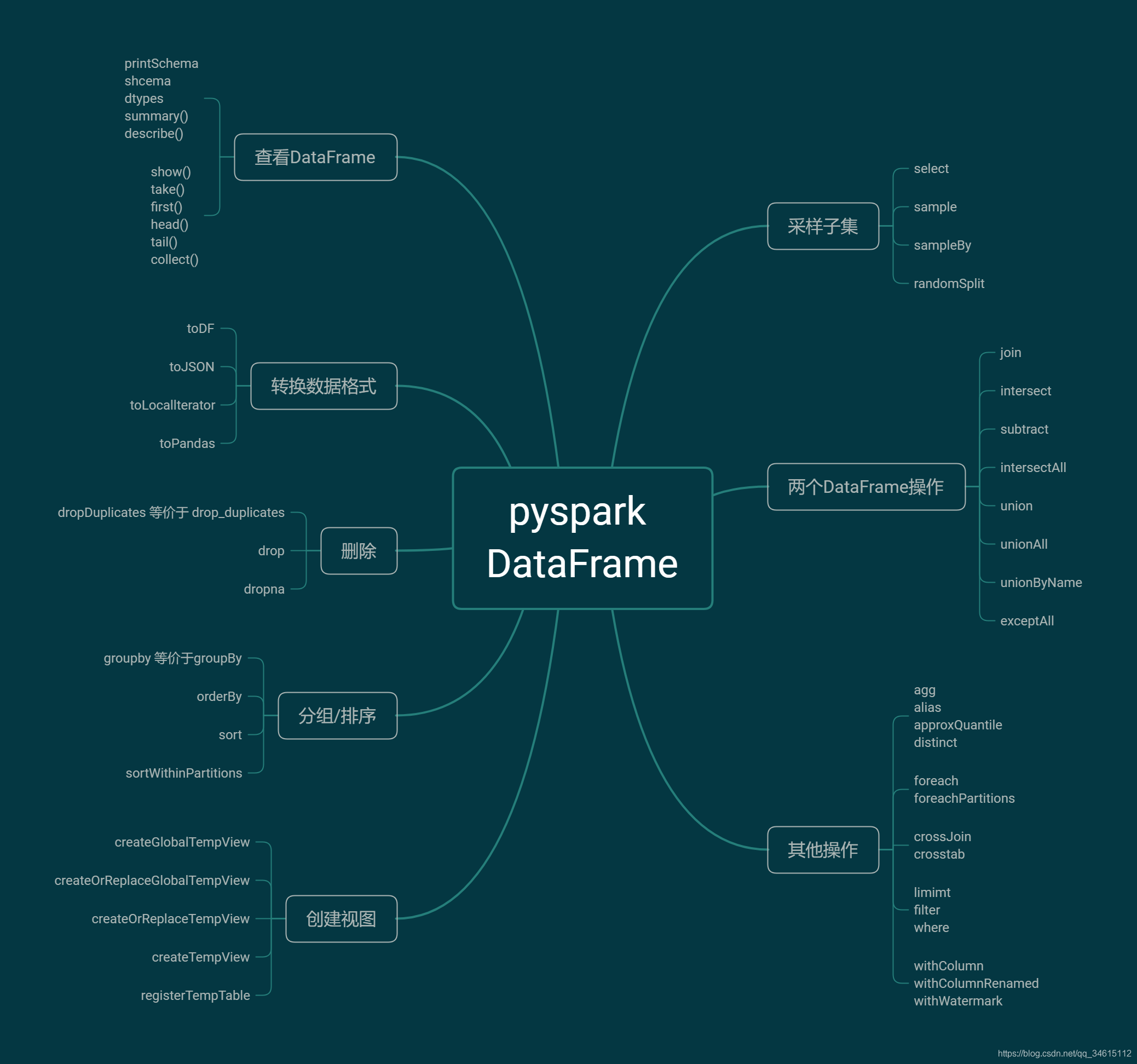
本节来学习pyspark.sql.DataFrame函数。博客中代码基于spark 2.4.4版本。不同版本函数会有不同,详细请参考官方文档。博客案例中用到的数据可以点击此处下载(提取码:2bd5)
from pyspark.sql import SparkSession
spark = SparkSession.Builder().master('local').appName('learnDataFrame').getOrCreate()
从文件中读取数据,创建DataFrame
df = spark.read.csv('../data/data.csv', header='True')
# 查看各个列的数据类型
df.printSchema()
root
|-- _c0: string (nullable = true)
|-- 对手: string (nullable = true)
|-- 胜负: string (nullable = true)
|-- 主客场: string (nullable = true)
|-- 命中: string (nullable = true)
|-- 投篮数: string (nullable = true)
|-- 投篮命中率: string (nullable = true)
|-- 3分命中率: string (nullable = true)
|-- 篮板: string (nullable = true)
|-- 助攻: string (nullable = true)
|-- 得分: string (nullable = true)
from pyspark.sql.types import IntegerType, FloatType
# withColumns: 为DataFrame增加新的列,如果列名存在,则替换已存在的列
df = df.withColumn('命中', df['命中'].cast(IntegerType()))
df = df.withColumn('投篮数', df['投篮数'].cast(IntegerType()))
df = df.withColumn('投篮命中率', df['投篮命中率'].cast(FloatType()))
df = df.withColumn('3分命中率', df['3分命中率'].cast(FloatType()))
df = df.withColumn('篮板', df['篮板'].cast(IntegerType()))
df = df.withColumn('助攻', df['助攻'].cast(IntegerType()))
df = df.withColumn('得分', df['得分'].cast(IntegerType()))
df.printSchema()
root
|-- _c0: string (nullable = true)
|-- 对手: string (nullable = true)
|-- 胜负: string (nullable = true)
|-- 主客场: string (nullable = true)
|-- 命中: integer (nullable = true)
|-- 投篮数: integer (nullable = true)
|-- 投篮命中率: float (nullable = true)
|-- 3分命中率: float (nullable = true)
|-- 篮板: integer (nullable = true)
|-- 助攻: integer (nullable = true)
|-- 得分: integer (nullable = true)
# 打印数据的2行
df.show(2)
+---+----+----+------+----+------+----------+---------+----+----+----+
|_c0|对手|胜负|主客场|命中|投篮数|投篮命中率|3分命中率|篮板|助攻|得分|
+---+----+----+------+----+------+----------+---------+----+----+----+
| 0|勇士| 胜| 客| 10| 23| 0.435| 0.444| 6| 11| 27|
| 1|国王| 胜| 客| 8| 21| 0.381| 0.286| 3| 9| 27|
+---+----+----+------+----+------+----------+---------+----+----+----+
only showing top 2 rows
df.explain
<bound method DataFrame.explain of DataFrame[_c0: string, 对手: string, 胜负: string, 主客场: string, 命中: int, 投篮数: int, 投篮命中率: float, 3分命中率: float, 篮板: int, 助攻: int, 得分: int]>
agg
聚合函数,等价于pandas中的df.groupby().agg()
# 求得分的均值
ans = df.agg({
'得分': 'mean'}).collect()
ans
[Row(avg(得分)=32.04)]
alias
返回带有别名集的新DataFrame。
df2 = df.alias('df1')
approxQuantile
计算DataFrame的数字列的近似分位数
quantile_25 = df.approxQuantile('得分', (0.25, ), 0.01)
quantile_25
[27.0]
df.coalesce(numPartitions=1)
DataFrame[_c0: string, 对手: string, 胜负: string, 主客场: string, 命中: int, 投篮数: int, 投篮命中率: float, 3分命中率: float, 篮板: int, 助攻: int, 得分: int]
# 查看DataFrame所有的列名
df.columns
['_c0', '对手', '胜负', '主客场', '命中', '投篮数', '投篮命中率', '3分命中率', '篮板', '助攻', '得分']
corr(col1, col2, method=None)
计算两个数值型列的相关性,目前仅支持persion相关系数。
# 计算3分命中率 和 得分的相关性
df.corr('3分命中率', '得分')
0.776918459184134
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7457
7457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









