




本节来学习pyspark.sql中的Grouped_Data类型的函数。博客中代码基于spark 2.4.4版本。不同版本函数会有不同,详细请参考官方文档。博客案例中用到的数据可以点击此处下载(提取码:h6gg)
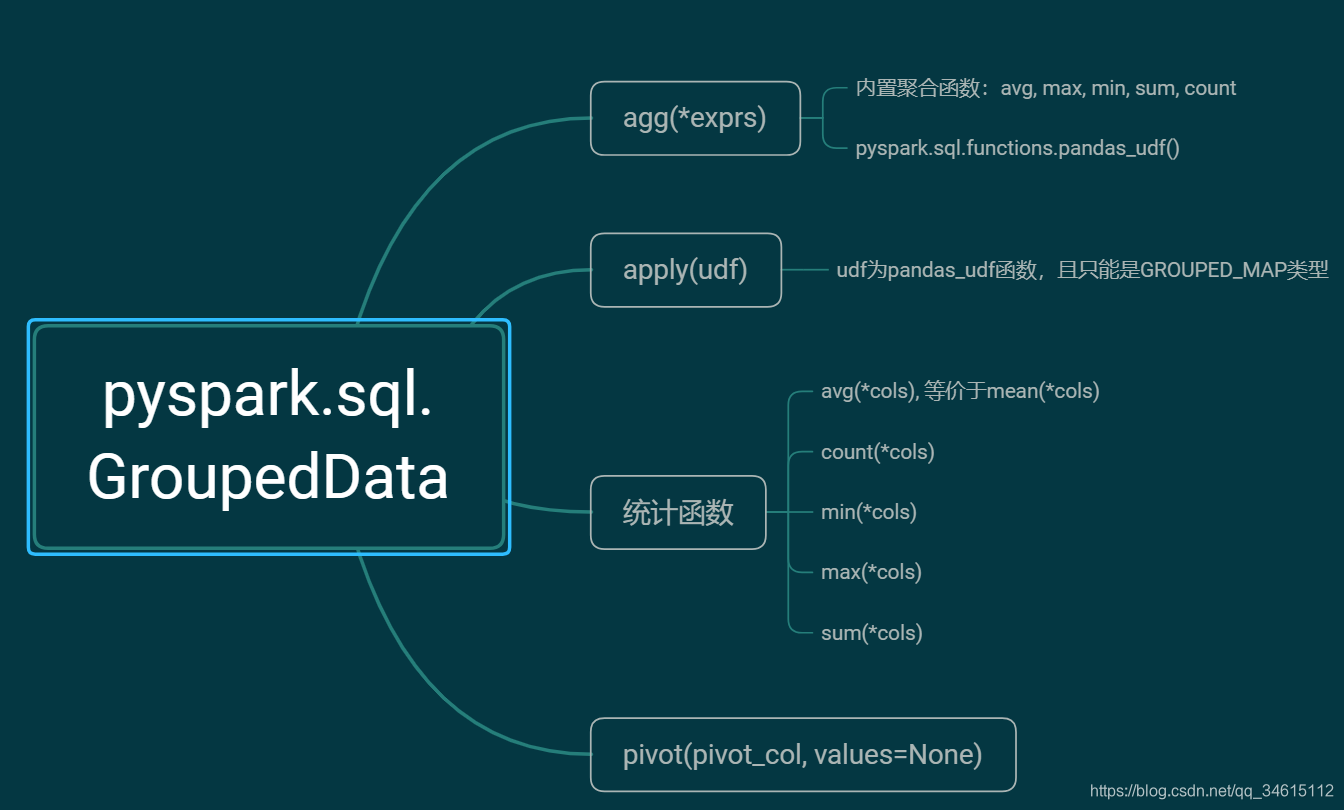
GroupedData(jgd,df)
是由DataFrame.groupBy()创建的一组在DataFrame上聚合的方法
from pyspark.sql import SparkSession
import pyspark.sql.types as typ
spark = SparkSession.Builder().master('local').appName('GroupedData').getOrCreate()
input_types = [('Opponent', typ.StringType()),
('WinOrLose', typ.StringType()),
('HomeAndAway', typ.StringType()),
('Hit', typ.IntegerType()),
('Shots', typ.IntegerType()),
('FieldGoalPercentage', typ.FloatType()),
('3PointShooting', typ.FloatType()),
('Backboard', typ.IntegerType()),
('Assist', typ.IntegerType()),
('Score',</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









