







一、为什么需要traits
首先看一下如下例子:
template<class T>
class test
{
public:
static T a;
};
template<class M>
void show()
{
cout << typeid(M::a).name() << endl;
}
int main()
{
show<test<int>>();
show<test<string>>();
show<test<short>>();
system("pause");
}
结果如下:

在show函数中想要得到得到模板M的模板参数类型,可以使用这样的方法,但是这种方法并不能够定义一个同样的变量。那如何才能实现定义同样的变量呢?那就是使用traits机制。利用traits机制的改版如下:
template<class T>
class test
{
public:
typedef T value_type;//在所有show函数可能用到的模板中,都加上这个定义
static T a;
};
template<class M>
void show()
{
M::value_type a;//这样,show就能根据模板的不同,甚至同一个模板的不同定义,而定义不同的变量。
cout << typeid(a).name() << endl;
}
int main()
{
//同上
...
}
结果如下

其实traits就是为了解决模板函数中如何利用模板参数本身的一些信息,比如上面的例子中,就想利用模板参数M的模板参数T来定义变量。
而这种情境在泛化编程中经常遇到。
二、迭代器的作用
在书中,有这样一句话:STL的中心思想在于——将数据容器和算法分开,彼此独立设计,最后再以一帖胶着剂将他们撮合在一起。
其中数据容器,个人理解是数据结构,也就是比如线性的数组,链表等,关联式的树,堆等。可以使用模板类来设计。
算法则可以使用模板函数来设计。
==问题是=:如何让不止一个数据结构都适用同一个算法的模板函数呢。
举例来说:我设计了一个查找算法模板函数,如下:
template<class T>
? find(?, ?){...}
输入参数和返回参数我使用?来表示,因为按逻辑输入参数应该是两个,就是查找的范围,而范围用一头一尾可以表示。但是这个头和尾我该如何去表达呢?比如数组和双向链表的头和尾可以用指针来表示。但是哈希表也可以用指针来表示嘛?明显不行的,如图所示:
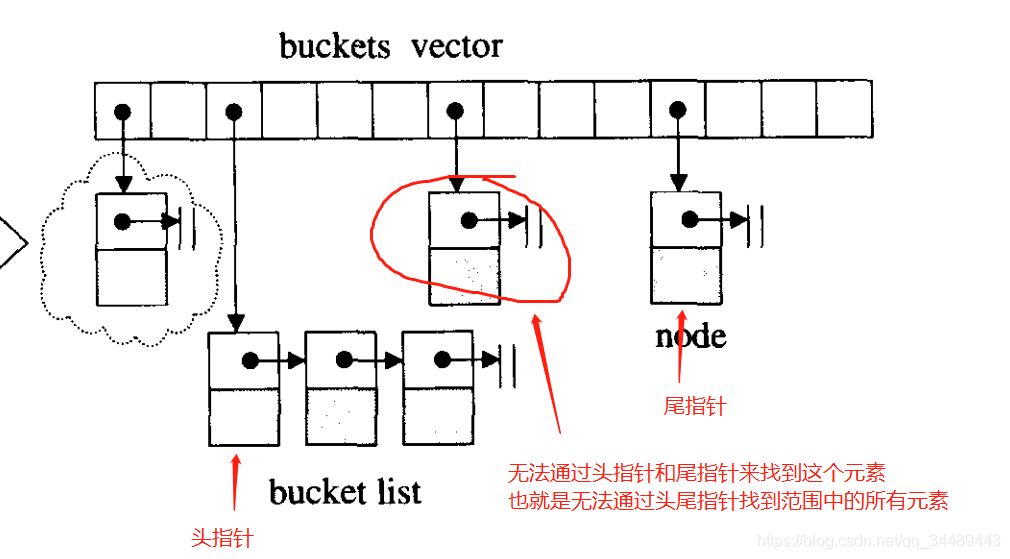
那既然无法通过头尾指针找到范围内的所有元素,又如何去执行find函数呢。
所以似乎不同的数据结构,针对同一个算法的模板函数,入口参数无法统一,如果不能统一,那么数据容器和算法就无法分开,因为需要针对每一个数据结构,都要特制一种算法。
而在STL中find函数的入口参数就是迭代器,迭代器就是数据容器和算法的粘合剂,能够统一算法的入口参数。
所以只要每一个数据容器都根据标准自定义迭代器,那么STL提供的算法的模板函数就可以使用,因为模板函数都是使用迭代器作为输入参数以及返回参数的。
三、迭代器与traits
迭代器和traits结合是非常紧密的,或者我源码看到现在为止,所有的traits都是在迭代器中呈现的(不保证traits只在迭代器中使用到)
为何迭代器中使用如此频繁,因为首先迭代器自身就是一个模板类,而迭代器作为模板函数的入口参数以及模板参数,完美符合了我在第一点中提到的使用情境,自然使用较多。模板函数中可以通过traits机制,萃取出许多迭代器的特性,并加以利用。
四、迭代器中traits的具体体现
迭代器的相应型别:迭代器的相应型别就是模板函数通过traits机制,可以获得的信息类型。比如在第一点中,通过萃取机制,可以获得函数模板的模板入口参数T。
而在stl迭代器中提供五种相应型别,源码如下:
template <class _Category, class _Tp, class _Distance = ptrdiff_t,
class _Pointer = _Tp*, class _Reference = _Tp&>
struct iterator {
typedef _Category iterator_category;//模板函数可以萃取iterator_category知道这个迭代器是什么类型的,迭代器类型见第五点
typedef _Tp value_type;//迭代器或者说迭代器的模板参数,也就是迭代器所指对象的类型
typedef _Distance difference_type;//表示两个迭代器之间距离的类型,
//比如说有的相邻两个类型之间相差(unsigned int)1,而有的相邻两个类型之间相差(int)1,difference_type就是存储距离类型是unsigned int还是int。
//不过一般都是使用的ptrdiff_t类型,就是__int64类型
typedef _Pointer pointer;//一般都是取value_type*,就是迭代器指向对象的类型的指针
typedef _Reference reference;//一般都是取value_type&,就是迭代器指向对象的类型的引用
};
这五种迭代器型别是最常用的,如果你想要自定义数据结构,那么在自定义迭代器时,一定要加入这五种型别,才可以被模板函数使用。
注意:以上五种型别都可以用来直接定义变量的
专门用来萃取的类
template <class _Iterator>
struct iterator_traits {
typedef typename _Iterator::iterator_category iterator_category;//迭代器种类
typedef typename _Iterator::value_type value_type;
typedef typename _Iterator::difference_type difference_type;
typedef typename _Iterator::pointer pointer;
typedef typename _Iterator::reference reference;
};
在模板函数中,stl又加入了一层萃取封装,使用方法以count源码举例说明:
template <class _InputIter, class _Tp>
typename iterator_traits<_InputIter>::difference_type
count(_InputIter __first, _InputIter __last, const _Tp& __value) {
typename iterator_traits<_InputIter>::difference_type __n = 0;//特别注意!!!
for ( ; __first != __last; ++__first)
if (*__first == __value)
++__n;
return __n;
}
模板函数count想要调用迭代器模板_InputIter中的距离类型来定义一个迭代器模板_InputIter适配的距离变量。
其实这里使用
typename iterator_traits<_InputIter>::difference_type __n = 0;
//等价于
typename _InputIter::difference_type __n = 0;
问题一:为什么需要进行一层额外封装?
为了处理这样的情况,如果对于count函数,我输入的模板参数不是迭代器,而是一个普通类型的指针,那该怎么办?比如说我有一个int类型的数组,头尾节点都是int*类型的指针,如下的语句:
typename iterator_traits<int *>::difference_type __n = 0;
如果iterator_traits只有如上的一种定义的话,这显然是不对的,因为int *是没有自己定义difference_type类型的。所以这种情况下,需要对iterator_traits进行偏特化,为了让普通类型指针也能够适用这个函数。源码如下:
template <class _Tp>
struct iterator_traits<_Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Tp>
struct iterator_traits<const _Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef const _Tp* pointer;
typedef const _Tp& reference;
};
如果有指针作为模板参数,那么五个相应型别就不在是从迭代器中去得到,而是直接根据指针来得到。
问题2:为什么只有指针的偏特化,如果是普通类型变量怎么办?
普通类型变量就不可以使用find函数,所有的模板函数中使用迭代器的地方,就不可能使用普通类型变量,最多只能使用普通类型指针。因为迭代器就是起到了指针的作用。相当于一个函数需要指针作为入口参数,你输入一个变量,那显然是不行的。
有了上面两种偏特化定义,下面的程序就对了
typename iterator_traits<int *>::difference_type __n = 0;
五、迭代器型别iterator_category
iterator_category是代表的迭代器指针的类型,迭代器指针类型有五种,如下所示:
- input_iterator:只读迭代器,可以读取迭代器指向的对象
- output_iterator:只写迭代器,向迭代器指向对象写入数值,但是不可以读取
- forward_iterator:前向迭代器,可双向移动
- bidirectional_iterator:双向迭代器,并对迭代器指向的对象进行读取
- random_access_iterator:随机访问迭代器,可以直接跳到容器的任何一个元素处,对其进行读写操作。
后三种使用较多,前三种没有看到stl中有容器使用
问题一:那如何来实现这些区别的呢,其实就是不同类型的迭代器,重载了不同的运算符。
如下图所示:
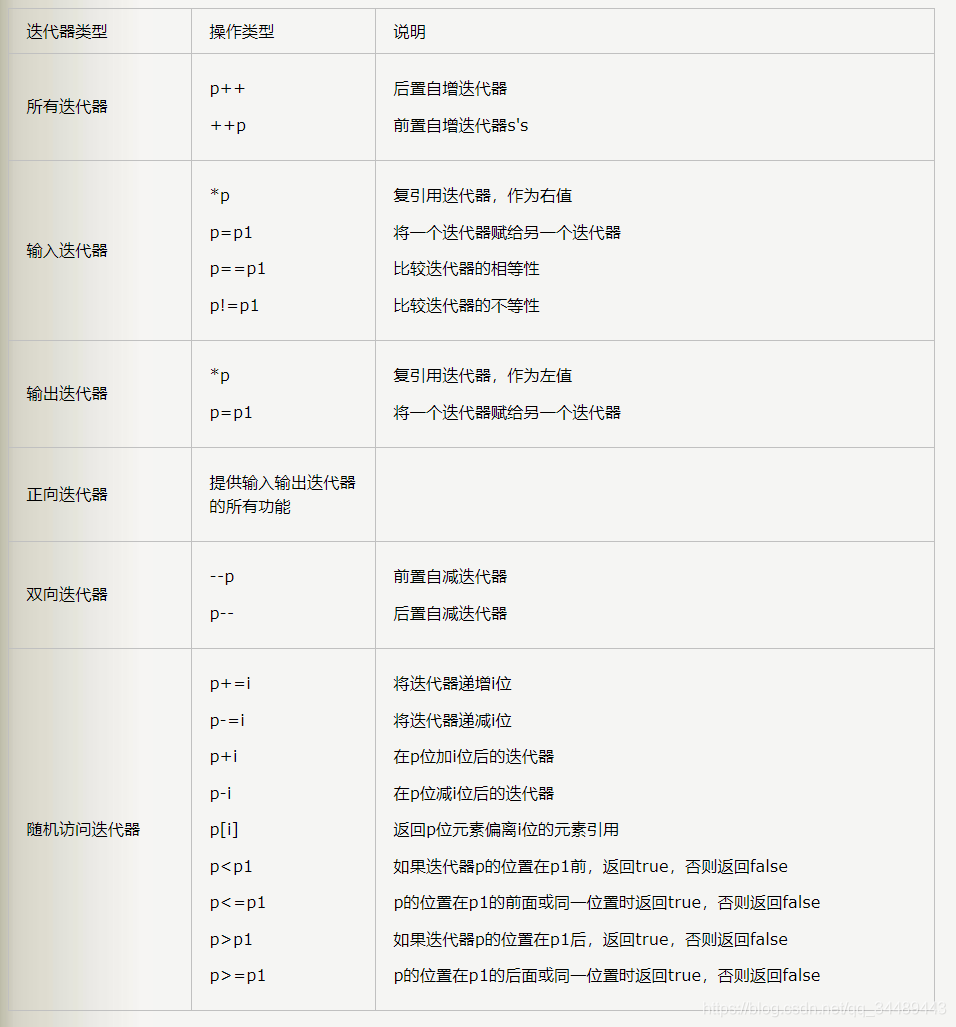
注意:->运算符并不是那种迭代器的特例,如果需要可以自定义重载,如果不需要,就不用重载,上图所示的是属于这种迭代器必须重载的运算符。
问题二:那程序如何自动区分这些类别呢,或者说如果萃取iterator_category,得到的是什么呢?
其实得到的是如下五种空类:
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
五种类型分别对应了一种空类,至于为什么使用继承关系,详见书98页。
其中forward_iterator_tag没有继承output_iterator_tag,网上有人解答说output_iterator不完全匹配forward_iterator,具体原因不详。
不过这其实用处不大,很少会用到继承关系的,因为使用符合自己类别的效率最高。

而这五种空类需要自己根据自己迭代器的特性来判断属于那种,并定义那种空类。
六、迭代器最重要的两点
上面所讲的迭代器和traits方面,都是为了迭代器和算法函数能够无缝对接,但是作为数据容器和算法的粘合剂,如何与数据容器进行无缝对接呢?
这一点很简单,就是在迭代器中,加入数据容器相关的成员变量。
所以看一个迭代器最重要的就是两点:
- 迭代器中的相应型别,其中最主要关注的就是这个迭代器是什么类型的,重载了哪些运算符
- 迭代器中的成员变量,这些成员变量都是和数据容器相关的。
七、以一个例子来讲解一下迭代器使用的全过程
advance函数就是将__i++循环n次
template <class _InputIterator, class _Distance>
inline void advance(_InputIterator& __i, _Distance __n) {
__advance(__i, __n, iterator_category(__i));
}
//__advance有三种重载形式
//针对只读迭代器的
template <class _InputIter, class _Distance>
inline void __advance(_InputIter& __i, _Distance __n, input_iterator_tag) {
while (__n--) ++__i;//由于input_iterator只有++这种运算符,所以只能接收n为正值
}
//针对双向迭代器的
template <class _BidirectionalIterator, class _Distance>
inline void __advance(_BidirectionalIterator& __i, _Distance __n,
bidirectional_iterator_tag) {
if (__n >= 0)//bidirectional_iterator重载了++和--,所以可以接收负值
while (__n--) ++__i;
else
while (__n++) --__i;
}
//针对随机存储迭代器的
template <class _RandomAccessIterator, class _Distance>
inline void __advance(_RandomAccessIterator& __i, _Distance __n,
random_access_iterator_tag) {
__i += __n;//由于random_access_iterator可以任意跳转,所以更快
}
可以看到,如果将random_access_iterator迭代器使用input_iterator迭代器的函数,那么效率会非常低
另外,判断类别的函数iterator_category()源码如下:
iterator_category(const _Iter& __i) { return __iterator_category(__i); }
__iterator_category(const _Iter&)//返回模板参数_Iter对应的迭代器种类
{
typedef typename iterator_traits<_Iter>::iterator_category _Category;
return _Category();//定义了一个iterator_traits<_Iter>::iterator_category空变量,但是足够让重载函数识别了。
}
八、STL迭代器的遍历
| 容器 | 迭代器类型 | 成员变量 | 备注 |
|---|---|---|---|
| vector | Random Access Iterator | 指向该数组某一位置的普通指针 | 在linux版本的STL中不仅仅是普通指针 |
| list | Bidirectional Iterator | 指向链表中某一节点的指针 | |
| deque | Random Access Iterator | 共有四个参数:①指向map中控数组的指针②该迭代器指向的元素③该迭代器指向元素所在缓冲区的首地址④该迭代器指向元素所在缓冲区的尾地址 | |
| slist | Forward Iterator | 指向链表中的某一节点的指针 | |
| RB-tree | Bidirectional Iterator | 指向红黑树中某一节点的指针 | 这个迭代器也是map,set,multimap,multiset的迭代器 |
| hashtable | Forward Iterator | 共两个参数:①迭代器所指向的元素②迭代器指向的元素所属桶的指针 | 这个迭代器也是hash_map,hash_set,hash_multimap,hash_multiset的迭代器 |
注意:
- 这上面的迭代器都只是SGI版本的迭代器,但是在其他版本中并不一定是一样的。
- 但是可以看到的是,基本所有的迭代器中都有一个元素,是指向该容器中某一个元素的指针,所以迭代器有和指针非常类似的行为,也来源于此。
九、总结
其实迭代器从使用的角度来看,行为类似于指针,并且有和->操作符,但是从源码角度看,里面蕴含的技巧真的很多。首先迭代器是一个类,这个类中重载了和->操作符,所以行为类似指针,并且类中的成员变量也基本都是指针,也可以理解为对指针作了一些封装。收货很大!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









