






 本文记录了Datawhale爬虫学习的第二部分,包括嵩天教授讲解的正则表达式基础,以及三个实战任务:1) 淘宝商品比价爬虫,通过获取cookie进行登录并抓取商品名和价格;2) 中国大学排名爬取,提取排名、学校名称和总分;3) 爬取丁香园论坛的用户名和回复内容,利用Xpath解析HTML。
本文记录了Datawhale爬虫学习的第二部分,包括嵩天教授讲解的正则表达式基础,以及三个实战任务:1) 淘宝商品比价爬虫,通过获取cookie进行登录并抓取商品名和价格;2) 中国大学排名爬取,提取排名、学校名称和总分;3) 爬取丁香园论坛的用户名和回复内容,利用Xpath解析HTML。
学习笔记
1.嵩天教授爬虫课第三章
B站链接、MOOC链接
第三章的内容是re(regular expression,正则表达式)
re是python自带的标准库无需安装,通过简洁的方式刻画字符串的特征。
re通常使用raw string,避免大量转义字符的使用。
常用操作符:


经典正则表达式实例:


主要方法:

控制标记:

编译:

Match对象:


最小匹配:
re默认为贪婪匹配,即有多个匹配时返回最长的匹配,当需要返回最短匹配时,需要用最小匹配。

2.Datawhale三个实战任务
2.1.淘宝商品比价定向爬虫
- 爬取网址:https://s.taobao.com/search?q=书包&js=1&stats_click=search_radio_all%25
- 爬取思路:
- 提交商品搜索请求,循环获取页面
- 对于每个页面,提取商品名称和价格信息
- 将信息输出到屏幕上
注意:cookie是有时效性的,需要先打开网址(需要登陆淘宝账号),然后在下图位置找到cookie。

# 导入包
import requests
import re
# 提交商品搜索请求,循环获取页面
def getHTMLText(url):
"""
请求获取html,(字符串)
:param url: 爬取网址
:return: 字符串
"""
try:
# 添加头信息,
kv = {
'cookie': 'cna=fEfdFRKIuH8CAWdmLMNW9fP/; t=06c1d4a95d61fdcdef2c8b5e9eae79bb; thw=cn; hng=TW%7Czh-TW%7CTWD%7C158; miid=662854181659420300; _samesite_flag_=true; cookie2=14ad127d55c447afd9cdb865fec3e9db; _tb_token_=fefd535ee3308; sgcookie=EZ121BoL2kOgGgj1sBgB4; unb=2617385050; uc3=vt3=F8dBxGR1S2QYJlph3dQ%3D&nk2=GcBicUe%2B4P0%3D&lg2=WqG3DMC9VAQiUQ%3D%3D&id2=UU6gZjn2erOwMA%3D%3D; csg=e031fa2e; lgc=zh2zh2zh; cookie17=UU6gZjn2erOwMA%3D%3D; dnk=zh2zh2zh; skt=38e3a7b39d12066d; existShop=MTU4NzYzNjkzNw%3D%3D; uc4=id4=0%40U2xt%2Fi2hmQlTJLDDNSO3l5Z48c4B&nk4=0%40GwkTUEseG%2FUrwFSngC6D01rU8Q%3D%3D; tracknick=zh2zh2zh; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=h01; _nk_=zh2zh2zh; cookie1=B0Spc9p07epJ6kfY0jbAtWOan2Lw0Uf2AuKo1h4ZtBU%3D; enc=jm%2FeH%2Br4%2FzP0R8WyRaP56eHn56%2BtOuOWnPAFuT%2BZIkNbNWL6r6hgZFhZTOD9rQGnoD3L3PaodVWGObdRCew5FQ%3D%3D; JSESSIONID=5F00082365D6A6CEB9CEA338FB7C7263; tfstk=cWUCBdVLipvQtW4e781ZYs9lkigdaLXj_EMgOle2FIBMoQPsBsAvuxGwtfv9Wmh1.; mt=ci=2_1; v=0; l=eBOfwFsgq3x_4R7yBOfZEurza7yFjIRAguPzaNbMiT5P_Jfp57XlWZjX_N89CnNVh64wR3yAaP02BeYBq1x0JeHw2j-la1Mmn; isg=BB4ep9JIzOjPJBuV4dTZxkH0b7Rg3-JZWXXOHMinhWFc677FMGygaFrB57fBU9px; uc1=cookie16=V32FPkk%2FxXMk5UvIbNtImtMfJQ%3D%3D&cookie21=URm48syIYB3rzvI4Dim4&cookie15=WqG3DMC9VAQiUQ%3D%3D&existShop=false&pas=0&cookie14=UoTUPcqfG7PGhA%3D%3D'
}
r = requests.get(url, timeout=30, headers=kv)
# r = requests.get(url, timeout=30)
# print(r.status_code)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
# 对于每个页面,提取商品名称和价格信息
def parsePage(glist, html):
'''
解析网页,搜索需要的信息
:param glist: 列表作为存储容器
:param html: 由getHTMLText()得到的
:return: 商品信息的列表
'''
try:
# 使用正则表达式提取信息
price_list = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
name_list = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(price_list)):
price = eval(price_list[i].split(":")[1]) #eval()在此可以去掉""
name = eval(name_list[i].split(":")[1])
glist.append([price, name])
except:
print("解析失败")
# 将信息输出到屏幕上
def printGoodList(glist):
tplt = "{0:^4}\t{1:^6}\t{2:^10}"
print(tplt.format("序号", "商品价格", "商品名称"))
count = 0
for g in glist:
count = count + 1
print(tplt.format(count, g[0], g[1]))
# 根据页面url的变化寻找规律,构建爬取url
goods_name = "书包" # 搜索商品类型
start_url = "https://s.taobao.com/search?q=" + goods_name
info_list = []
page = 3 # 爬取页面数量
# 进度条优化用户体验
count = 0
for i in range(page):
count += 1
try:
url = start_url + "&s=" + str(44 * i)
html = getHTMLText(url) # 爬取url
parsePage(info_list, html) #解析HTML和爬取内容
print("\r爬取页面当前进度: {:.2f}%".format(count * 100 / page), end="") # 显示进度条
except:
continue
printGoodList(info_list)
部分结果图:

2.2.中国大学排名定向爬取
- 爬取url:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html
- 爬取思路:
- 从网络上获取大学排名网页内容
- 提取网页内容中信息到合适的数据结构(二维数组)-排名,学校名称,总分
- 利用数据结构展示并输出结果
# 导入库
import requests
from bs4 import BeautifulSoup
import bs4
# 从网络上获取大学排名网页内容
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 提取网页内容中信息到合适的数据结构(二维数组)
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# 根据实际提取需要的内容,
ulist.append([tds[0].string, tds[1].string, tds[3].string])
# 利用数据结构展示并输出结果
# 对中英文混排输出问题进行优化:对format(),设定宽度和添加参数chr(12288)
def printUnivList(ulist, num=20):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format('排名', '学校名称', '总分', chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
u_info = [] # 存储爬取结果的容器
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
fillUnivList(u_info, html) # 爬取
printUnivList(u_info, num=30) # 打印输出30个信息
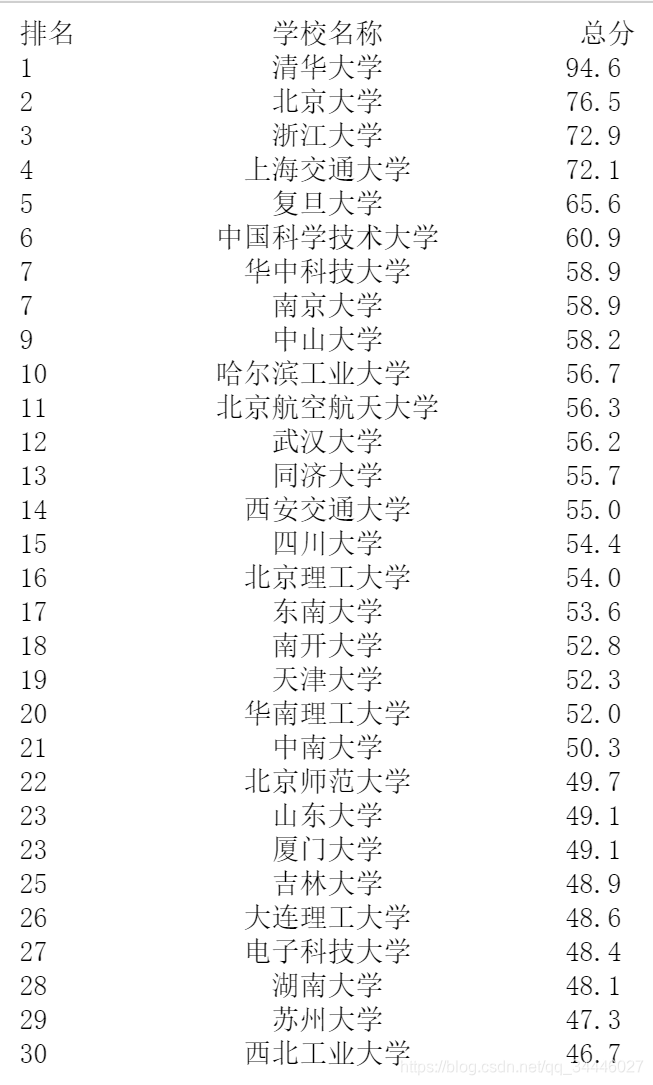
结果图:
2.3.爬取丁香园-用户名和回复内容
- 爬取思路:
- 获取url的html
- lxml解析html
- 利用Xpath表达式获取user和content
- 保存爬取的内容
# 导入库
from lxml import etree
import requests
url = "http://www.dxy.cn/bbs/thread/626626#626626"
# 获取url的html
req = requests.get(url)
html = req.text
# lxml解析html
tree = etree.HTML(html)
tree
# 利用Xpath表达式获取user和content(重点)
user = tree.xpath('//div[@class="auth"]/a/text()')
# print(user)
content = tree.xpath('//td[@class="postbody"]')
# 保存爬取的内容
results = []
for i in range(0, len(user)):
# print(user[i].strip()+":"+content[i].xpath('string(.)').strip())
# print("*"*80)
# 因为回复内容中有换行等标签,所以需要用string()来获取数据
results.append(user[i].strip() + ": " + content[i].xpath('string(.)').strip())
# 打印爬取的结果
for i,result in zip(range(0, len(user)),results):
print("user"+ str(i+1) + "-" + result)
print("*"*100)
结果图:



















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









