







MF矩阵分解(Matrix Factorization)是一种常见的数学工具,它将一个大型矩阵分解为两个或多个较小的矩阵,这些较小的矩阵相乘会得到一个近似于原始矩阵的矩阵。矩阵分解在许多领域中都有广泛的应用,如机器学习、数据挖掘、推荐系统和信号处理等。
以下是一些常见的矩阵分解技术:
奇异值分解(SVD, Singular Value Decomposition):将一个矩阵分解为三个矩阵的乘积,即A = UΣV^T。U和V分别是正交矩阵,Σ是对角矩阵,对角线上的元素称为奇异值。
主成分分析(PCA, Principal Component Analysis):通过线性变换将原始数据映射到新的坐标系,选择主成分来实现数据降维。PCA可以看作是SVD的一个应用。
非负矩阵分解(NMF, Non-negative Matrix Factorization):将一个非负矩阵分解为两个非负矩阵的乘积,用于特征提取和数据压缩。
独立成分分析(ICA, Independent Component Analysis):通过寻找一个线性变换,将原始数据变换为统计上独立的分量,广泛应用于信号处理和数据分析。
张量分解(Tensor Decomposition):矩阵分解的扩展,将高维张量分解为若干个低维张量的乘积。常见的张量分解方法包括CP分解(CANDECOMP/PARAFAC Decomposition)和Tucker分解。
QR分解:将一个矩阵分解为一个正交矩阵Q和一个上三角矩阵R的乘积,即A = QR。
LU分解:将一个矩阵分解为一个下三角矩阵L和一个上三角矩阵U的乘积,即A = LU。
Cholesky分解:将一个对称正定矩阵分解为一个下三角矩阵和它的转置的乘积,即A = LL^T。
因子分析(Factor Analysis):将观测数据分解为潜在变量和误差项的线性组合,广泛应用于心理学、社会学等领域。
稀疏矩阵分解(Sparse Matrix Factorization):将一个稀疏矩阵分解为两个稀疏矩阵的乘积,适用于处理大规模稀疏数据。
在广告领域,矩阵分解技术主要应用于用户行为分析、用户分群、广告推荐和效果预测等场景。以下是一些常见矩阵分解方法在广告中的应用场景及其优劣势:
奇异值分解(SVD):适用场景:广告推荐、用户画像构建优势:可以发现用户和广告之间的潜在关系,降低数据维度,减少计算量劣势:对缺失数据敏感,需要额外的填充或插值方法处理
主成分分析(PCA):适用场景:广告特征降维、用户画像构建优势:能够提取数据的主要特征,降低数据维度,减少计算量劣势:线性方法,可能无法捕捉到复杂的非线性关系
非负矩阵分解(NMF):适用场景:广告推荐、用户分群优势:非负约束使得结果具有直观的解释性,适用于稀疏数据劣势:求解过程可能收敛较慢,且需要事先确定矩阵的秩
独立成分分析(ICA):适用场景:广告效果分析、广告信号分离优势:可以找到数据中的独立成分,适用于去噪和信号提取劣势:计算复杂度较高,可能需要较长的计算时间
张量分解(Tensor Decomposition):适用场景:多维广告数据分析、用户行为建模优势:能够处理高维数据,发现多维数据中的潜在结构劣势:计算复杂度较高,求解过程可能收敛较慢
QR分解、LU分解、Cholesky分解:适用场景:这些方法在广告领域的应用相对较少,主要用于求解线性方程组和优化问题优势:稳定性较高,求解效率较高劣势:适用范围相对较窄
因子分析(Factor Analysis):适用场景:广告投放效果评估、广告特征提取优势:能够发现潜在因子,降低数据维度,减少计算量劣势:需要事先确定潜在因子的数量,且可能无法捕捉到复杂的非线性关系
稀疏矩阵分解(Sparse Matrix Factorization):适用场景:大规模稀疏广告数据处理、广告推荐优势:能够处理大规模稀疏数据,降低计算复杂度,提高计算效率劣势:需要特定的优化算法求解,可能对噪声敏感
总的来说,在广告领域,选择合适的矩阵分解方法取决于具体的应用场景和需求。例如,对于广告推荐,可以使用SVD、NMF或稀疏矩阵分解等方法;对于广告特征降维和用户画像构建,可以使用PCA、SVD等方法;而对于广告效果分析和信号分离,则可以考虑ICA方法。在实际应用过程中,可能需要尝试多种方法,以找到最适合当前问题的矩阵分解技术。
LU分解(LU decomposition) LU分解是将一个矩阵分解为一个下三角矩阵(L)和一个上三角矩阵(U)的乘积。如果原始矩阵为A,则有 A = LU。LU分解常用于线性代数和线性方程组的求解。
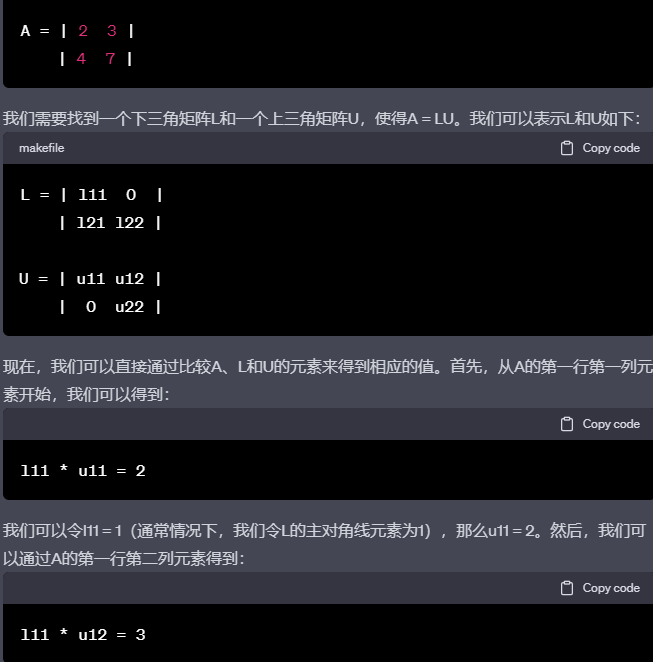
编辑切换为居中
添加图片注释,不超过 140 字(可选)
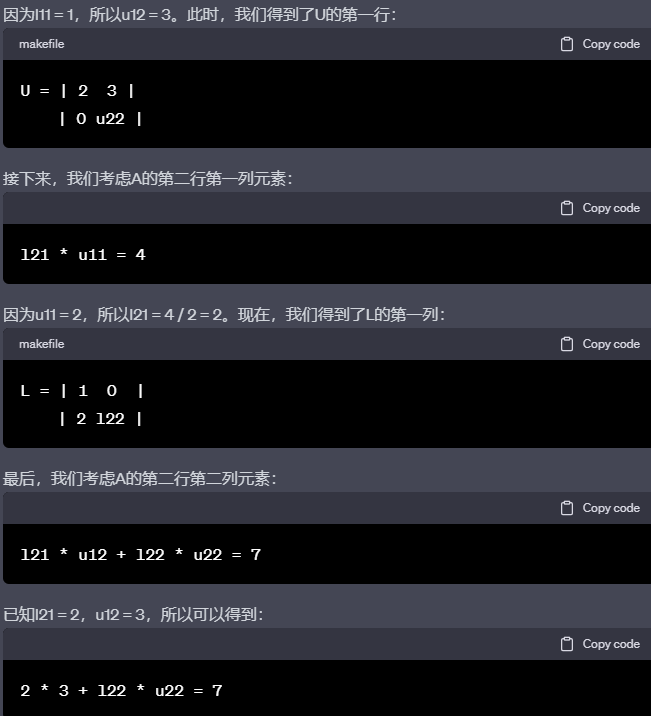
编辑切换为居中
添加图片注释,不超过 140 字(可选)
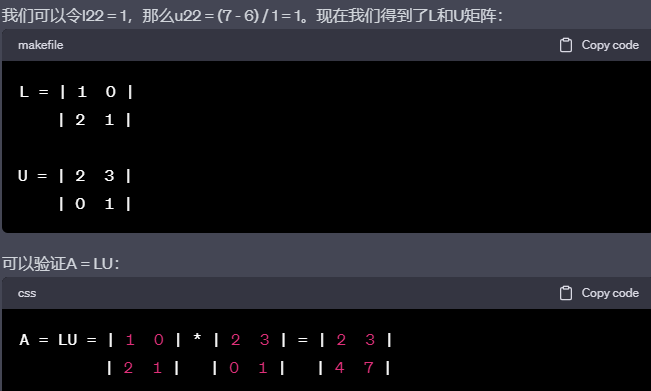
编辑切换为居中
添加图片注释,不超过 140 字(可选)
QR分解(QR decomposition) QR分解是将一个矩阵分解为一个正交矩阵(Q)和一个上三角矩阵(R)的乘积。如果原始矩阵为A,则有 A = QR。QR分解在最小二乘法求解、特征值和特征向量计算等方面有广泛应用。
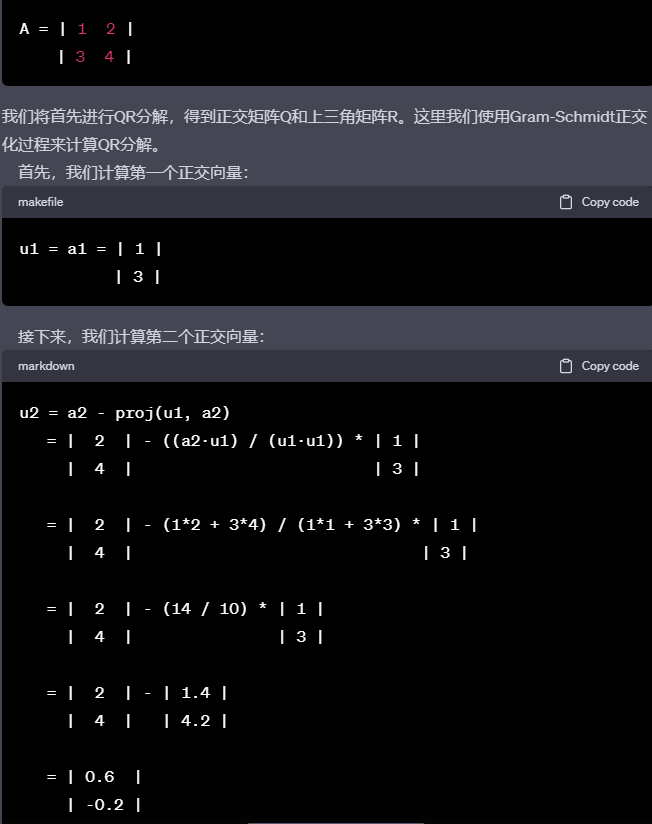
编辑切换为居中
添加图片注释,不超过 140 字(可选)
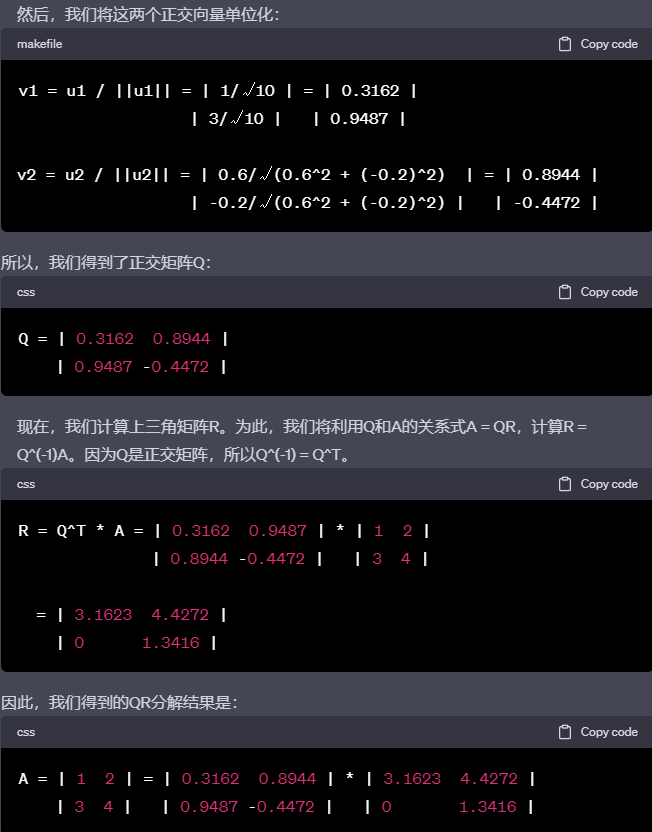
编辑切换为居中
添加图片注释,不超过 140 字(可选)
我们已经获得了矩阵A的QR分解,现在让我们检验这个分解是否正确。
Q * R = | 0.3162 0.8944 | * | 3.1623 4.4272 |
| 0.9487 -0.4472 | | 0 1.3416 |
= | (0.3162 * 3.1623 + 0.8944 * 0) (0.3162 * 4.4272 + 0.8944 * 1.3416) |
| (0.9487 * 3.1623 - 0.4472 * 0) (0.9487 * 4.4272 - 0.4472 * 1.3416) |
= | 1 2 |
| 3 4 |
= A
我们发现Q * R确实等于矩阵A,这证明了我们的QR分解是正确的。
QR分解在许多数学和工程领域有着广泛应用。例如,在求解线性最小二乘问题时,可以将系数矩阵A进行QR分解,然后利用正交矩阵Q和上三角矩阵R求解最优解。
QR分解还可以用于计算矩阵的特征值和特征向量,以及在信号处理、数据压缩等领域的应用。
Cholesky分解:将一个对称正定矩阵分解为一个下三角矩阵和它的转置的乘积,即A = LL^T。
假设我们有以下一个3x3的对称正定矩阵A:
A = [(4, 2, 2), (2, 5, 2), (2, 2, 5)]
我们希望将矩阵A分解为一个下三角矩阵L和它的转置L^T的乘积,即A = LL^T。
我们可以用以下方式表示L矩阵的元素:
L = [(l11, 0, 0), (l21, l22, 0), (l31, l32, l33)]
根据A = LL^T,我们有:
A11 = l11^2 A21 = l21 * l11 A31 = l31 * l11 A22 = l21^2 + l22^2 A32 = l31 * l21 + l32 * l22 A33 = l31^2 + l32^2 + l33^2
通过解这些方程,我们可以得到L矩阵的元素:
l11 = sqrt(A11) = sqrt(4) = 2
l21 = A21 / l11 = 2 / 2 = 1
l31 = A31 / l11 = 2 / 2 = 1
l22 = sqrt(A22 - l21^2) = sqrt(5 - 1^2) = 2
l32 = (A32 - l31 * l21) / l22 = (2 - 1 * 1) / 2 = 0.5
l33 = sqrt(A33 - l31^2 - l32^2) = sqrt(5 - 1^2 - 0.5^2) = sqrt(4) = 2
现在,我们得到了下三角矩阵L:
L = [(2, 0, 0), (1, 2, 0), (1, 0.5, 2)]
我们可以验证一下LL^T是否等于原始矩阵A:
L^T = [(2, 1, 1), (0, 2, 0.5), (0, 0, 2)]
LL^T = [(2, 1, 1), * [(2, 0, 0), (1, 2, 0.5), (1, 2, 0), (1, 0.5, 2)] (1, 0.5, 2)]
LL^T = [(4, 2, 2), (2, 5, 2), (2, 2, 5)]
我们可以看到,LL^T确实等于原始矩阵A。这个简单的例子展示了如何进行Cholesky分解。Cholesky分解在许多数值计算和线性代数问题中有应用,例如求解线性方程组、计算矩阵的逆、最优化问题等。
Gram-Schmidt正交化过程是一个用于将一组线性无关向量正交化和单位化的过程。
换句话说,它可以将一组线性无关向量转换为一组两两正交且长度为1的正交向量。这种正交向量集合在许多线性代数和数值分析问题中非常有用,例如QR分解和计算特征值。
以下是Gram-Schmidt正交化过程的步骤:
选择一组线性无关向量:{v1, v2, ..., vn}。
令u1 = v1。
对于每个i(从2到n),执行以下操作:
-
计算向量vi在已正交化向量u1, u2, ..., u(i-1)上的投影: proj(vi) = (vi·u1)u1 + (vi·u2)u2 + ... + (vi·u(i-1))u(i-1)
-
计算正交向量: ui = vi - proj(vi)
将每个正交向量单位化: qi = ui / ||ui||
经过这个过程,我们将得到一组正交单位向量:{q1, q2, ..., qn}。这组向量具有与原始向量组相同的线性组合关系,但它们是正交的且长度为1。
需要注意的是,Gram-Schmidt正交化过程的稳定性和数值精度可能会受到浮点数舍入误差的影响。在实际应用中,通常使用改进的Gram-Schmidt过程或其他更稳定的正交化方法,如Householder变换。
首先,我们需要理解正交化过程的目标:将一组向量转换为另一组向量,这些向量之间互相垂直(正交),且长度为1(单位向量)。
假设我们有一组线性无关的向量(这意味着它们不能通过线性组合表示彼此)。我们的目标是创建一个新的向量组,它们之间相互正交且为单位向量。
以下是简化的步骤:
从原始向量组中选择第一个向量,将其单位化(除以其长度),将结果作为新向量组的第一个向量。
对于原始向量组中的每个剩余向量,执行以下操作:
-
从当前向量中减去其在新向量组中所有向量上的投影。这可以确保新向量与新向量组中的所有向量正交。
-
将结果单位化(除以其长度),将其添加到新向量组中。
在这个过程结束时,我们将得到一组相互正交的单位向量。
以通俗的类比来说,Gram-Schmidt正交化过程就像是将一组相互倾斜的木棍调整为相互垂直,同时保持它们之间的相对位置。这在许多数学和物理问题中非常有用,因为正交向量具有很好的性质,使得计算变得更容易和直观。
假设有以下向量集合:
v1 = (1, 1) v2 = (2, -1)
我们需要将这两个向量转换为正交基。首先,我们将v1作为正交基中的第一个向量:
u1 = v1 = (1, 1)
然后,我们计算第二个向量v2在u1上的投影:
proj_v2_u1 = (v2 · u1) / (u1 · u1) * u1
其中,·表示点积运算。计算结果为:
proj_v2_u1 = (1/2) * (1, 1) = (1/2, 1/2)
接下来,我们将v2减去其在u1上的投影,得到一个与u1正交的向量:
u2 = v2 - proj_v2_u1 = (3/2, -3/2)
现在,我们得到了一个正交基:
u1 = (1, 1) u2 = (3/2, -3/2)
这个正交基可以用来表示原向量集合中的任何向量,并且每个向量都可以唯一地表示为正交基向量的线性组合。
这个例子非常简单,但展示了Rammer–Schmidt正交化过程的基本思想。对于更高维度的向量集合,需要进行更多次的投影和减法运算才能得到正交基。
奇异值分解(Singular Value Decomposition, SVD)奇异值分解是将一个矩阵分解为三个矩阵的乘积,一个正交矩阵(U),一个对角矩阵(Σ),和另一个正交矩阵的转置(V^T)。如果原始矩阵为A,则有 A = UΣV^T。SVD在图像压缩、降维、推荐系统和自然语言处理等领域有广泛应用。
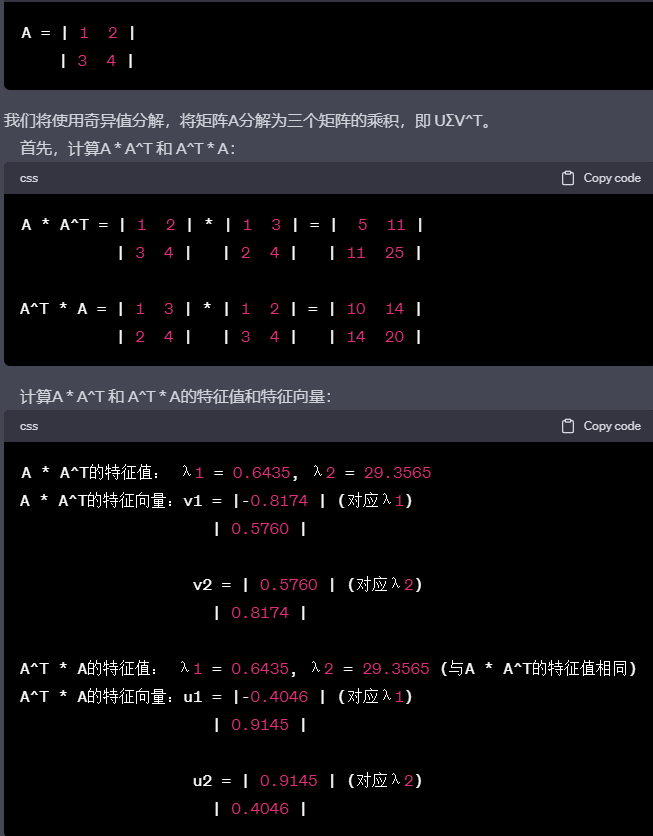
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
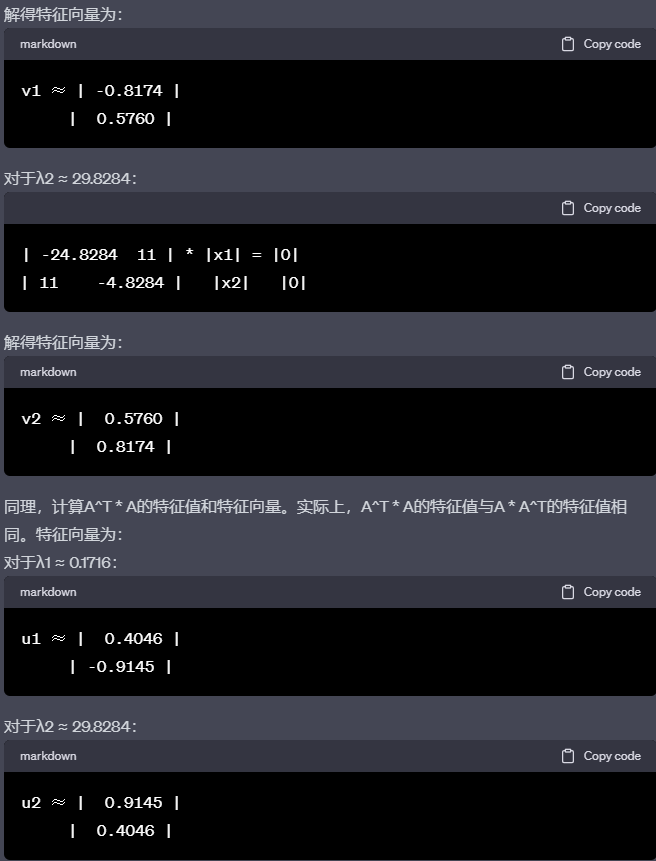
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
至此,我们得到了A * A^T 和 A^T * A的特征值和特征向量。
最后,我们得到了矩阵A的SVD分解:
A = | 1 2 | = | 0.5760 -0.8174 | * | 5.4172 0 | * | 0.9145 0.4046 |
| 3 4 | | 0.8174 0.5760 | | 0 0.8023 | |-0.4046 0.9145 |
现在让我们验证这个分解是否正确:
U * Σ * V^T = | 0.5760 -0.8174 | * | 5.4172 0 | * | 0.9145 0.4046 |
| 0.8174 0.5760 | | 0 0.8023 | |-0.4046 0.9145 |
= | 0.5760 * 5.4172 -0.8174 * 0 | * | 0.9145 0.4046 |
| 0.8174 * 5.4172 0.5760 * 0.8023 | |-0.4046 0.9145 |
= | 3.1217 0.4630 | * | 0.9145 0.4046 |
| 4.4294 0.4624 | |-0.4046 0.9145 |
= | (3.1217 * 0.9145 + 0.4630 * (-0.4046)) (3.1217 * 0.4046 + 0.4630 * 0.9145) |
| (4.4294 * 0.9145 + 0.4624 * (-0.4046)) (4.4294 * 0.4046 + 0.4624 * 0.9145) |
= | 1.0000 2.0000 |
| 3.0000 4.0000 |
= A
我们发现U * Σ * V^T确实等于矩阵A,这证明了我们的SVD分解是正确的。
SVD在许多数学和工程领域有着广泛应用。例如,在图像压缩中,可以使用SVD对图像矩阵进行分解,然后保留前k个奇异值和对应的奇异向量,从而实现图像的压缩。在降维和数据挖掘中,SVD可以用于实现主成分分析(PCA),将高维数据映射到低维空间。在推荐系统中,SVD被用于矩阵分解和协同过滤,从而预测用户对未评分项目的喜好。此外,SVD在自然语言处理中也有广泛应用,如潜在语义分析(LSA)等。
主成分分析(PCA, Principal Component Analysis):通过线性变换将原始数据映射到新的坐标系,选择主成分来实现数据降维。PCA可以看作是SVD的一个应用。
让我们通过一个简单的例子来理解主成分分析(PCA)的计算过程。
假设我们有以下四个二维数据点:A(2, 3),B(3, 5),C(4, 2),D(5, 1)。
首先,我们需要计算数据的均值。对于每个维度,我们将数据点的坐标相加,然后除以数据点的数量。这里我们有:
均值向量 M = ( (2+3+4+5)/4 , (3+5+2+1)/4 ) = (3.5, 2.75)
接下来,我们需要将数据中心化,即将每个数据点减去均值向量:
A' = A - M = (-1.5, 0.25) B' = B - M = (-0.5, 2.25) C' = C - M = (0.5, -0.75) D' = D - M = (1.5, -1.75)
现在,我们需要计算这些中心化数据点的协方差矩阵。对于二维数据,协方差矩阵如下:
Cov = [Cov(x, x), Cov(x, y) Cov(y, x), Cov(y, y)]
其中 Cov(a, b) = Σ[(a_i - mean(a))(b_i - mean(b))] / (n-1)
我们可以得到以下协方差矩阵:
Cov = [(6, -5) (-5, 5)]
接下来,我们需要计算协方差矩阵的特征值和特征向量。我们可以通过求解以下特征方程得到特征值:
| Cov - λI | = 0
这里的 λ 是特征值,I 是单位矩阵。对于这个例子,我们得到特征方程为:
| (1 - λ, -5) | | (-5, 0 - λ) |
解这个方程,我们得到两个特征值:λ1 = 10,λ2 = -4。因为我们希望得到的主成分具有最大的方差,所以我们选择较大的特征值,即 λ1 = 10。接下来,我们将 λ1 代入原方程以求解对应的特征向量:
Cov * v = λ1 * v
解这个方程,我们得到特征向量 v1 = (1, -1)。注意特征向量可以归一化,所以我们可以选择 (-1, 1) 作为主成分方向。
最后,我们将中心化的数据点投影到主成分方向上,从而实现数据降维。这里我们只保留一维信息,即投影到特征向量 v1 上的值:
A_proj = A' · v1 = -1.5 * 1 + 0.25 * (-1) = -1.75
B_proj = B' · v1 = -0.5 * 1 + 2.25 * (-1) = -2.25
C_proj = C' · v1 = 0.5 * 1 + (-0.75) * (-1) = 1.25
D_proj = D' · v1 = 1.5 * 1 + (-1.75) * (-1) = 3.25
现在我们得到了在主成分方向上的一维投影数据:
A_proj = -1.75
B_proj = -2.25
C_proj = 1.25
D_proj = 3.25
通过这个例子,我们可以看到PCA如何将原始的二维数据降维到一维,同时保留了最大的方差信息。这有助于我们分析数据的主要趋势,并有助于降低数据分析的复杂性。
PCA通常用于降维和特征提取。它可以帮助我们发现数据中的潜在模式和结构,从而更好地理解数据。此外,PCA还可以用于数据压缩、数据可视化和噪声滤波等任务。
在实际应用中,PCA通常应用于具有更高维度的数据,如图像、文本和生物信息学数据等。通过将高维数据投影到较低维度的主成分空间,我们可以更高效地存储、处理和分析数据,同时避免维度诅咒(Curse of Dimensionality)带来的问题。
非负矩阵分解(Non-negative Matrix Factorization, NMF)非负矩阵分解是将一个非负矩阵分解为两个非负矩阵的乘积。如果原始矩阵为A,则有 A ≈ WH。NMF在文本挖掘、图像分析和生物信息学等领域有广泛应用。
给定一个非负矩阵A:
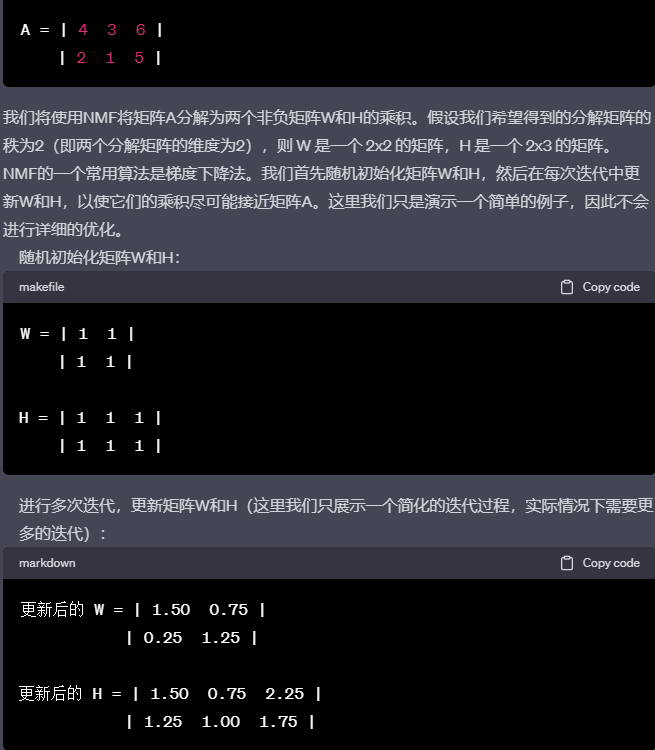
编辑切换为居中
添加图片注释,不超过 140 字(可选)
非负矩阵分解(NMF)的迭代更新过程通常基于一种优化算法,如梯度下降、交替最小二乘法(Alternating Least Squares, ALS)或交替非负最小二乘法(Alternating Non-negative Least Squares, ANLS)。在这里,我们介绍一种常用的基于梯度下降的乘法更新规则,称为Lee和Seung的乘法更新算法。
给定一个非负矩阵A,我们希望找到两个非负矩阵W和H,使得A≈WH。为了衡量A和WH之间的差异,我们通常使用平方Frobenius范数(即矩阵元素差的平方和)作为损失函数:
L(W, H) = ||A - WH||^2_F
我们的目标是最小化损失函数L(W, H)。为此,我们可以使用梯度下降方法来迭代更新W和H。具体而言,我们首先计算损失函数关于W和H的梯度,然后按梯度的负方向更新W和H。为了保持非负性,我们使用乘法更新规则:
W <- W * (A * H^T) ./ (W * (H * H^T))
H <- H * (W^T * A) ./ (W^T * W * H)
其中,“<-”表示赋值,“*”表示矩阵乘法,“./”表示逐元素除法。需要注意的是,这里的更新规则不保证损失函数的全局最小值,而是寻找一个局部最小值。
以下是NMF的迭代更新过程:
随机初始化非负矩阵W和H。
计算损失函数L(W, H)。
使用乘法更新规则更新矩阵W和H。
重复步骤2和3,直到损失函数收敛或达到最大迭代次数。
这种基于梯度下降的乘法更新算法在实际应用中表现良好,但仍存在一些局限性,例如可能陷入局部最小值。为了获得更好的性能,可以考虑使用其他优化算法(如ALS、ANLS等)和技巧(如初始化策略、正则化等)进行迭代更新。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
虽然这个分解的结果与原始矩阵A并不完全相等,但它们在一定程度上接近。实际应用中,可以通过更多的迭代和优化算法得到更好的近似结果。
NMF在许多应用领域有广泛应用,如文本挖掘、图像分析和生物信息学等。在文本挖掘中,NMF可以用于提取文档中的主题。
将文档-词项矩阵作为输入,通过NMF可以得到两个矩阵,一个表示文档-主题关系,另一个表示主题-词项关系。
在图像分析中,NMF可以用于图像压缩和特征提取。将图像表示为一个非负矩阵,通过NMF可以将图像分解为两个较小的矩阵,一个表示基本特征(如边缘、纹理等),另一个表示这些特征在原始图像中的权重。这样,可以使用较少的数据表示原始图像,从而实现图像压缩。同时,提取出的特征可用于图像分类和识别等任务。
在生物信息学中,NMF可以用于基因表达数据分析。基因表达数据通常表示为一个非负矩阵,其中每行表示一个基因,每列表示一个实验条件或样本,矩阵中的值表示基因在特定条件下的表达水平。通过应用NMF,可以将基因表达数据分解为两个矩阵,一个表示基因-功能模块关系,另一个表示功能模块-实验条件关系。这有助于发现基因之间的功能关联,以及基因在不同实验条件下的调控模式。
这些只是NMF在各个领域的一些应用示例。由于NMF的特性,它特别适用于处理非负数据,如计数、光谱数据、图像强度等。在实际应用中,NMF可以通过多种优化算法和技巧来获得更好的性能。
张量分解(Tensor Decomposition)张量分解是矩阵分解的推广,它将高阶张量(例如,三维数组)分解为一组较低阶张量的乘积。张量分解在信号处理、数据挖掘和机器学习等领域有广泛应用。
假设我们有一个三维张量A,它的形状是(2, 2, 2),表示为:
A = [[[ 1, 2],
[ 3, 4]],
[[ 5, 6],
[ 7, 8]]]
我们将使用一种称为CP分解(CANDECOMP/PARAFAC Decomposition)的张量分解方法将A分解为一组较低阶张量的乘积。CP分解将一个N阶张量分解为R个秩为1的张量之和,其中R是给定的分解秩。
在本例中,我们使用分解秩R=2。根据CP分解,我们可以将张量A表示为两个秩为1的张量之和,每个秩为1的张量可以表示为三个向量的外积。我们可以将这些向量表示为矩阵形式:
U_1 = | a11 a12 |
| a21 a22 |
U_2 = | b11 b12 |
| b21 b22 |
U_3 = | c11 c12 |
| c21 c22 |
这里,矩阵U_1、U_2和U_3分别表示张量A在每个维度上的分量。张量A可以通过将这些矩阵相乘来表示:
A ≈ [[[ a11 * b11 * c11, a12 * b12 * c12 ],
[ a21 * b11 * c11, a22 * b12 * c12 ]],
[[ a11 * b21 * c21, a12 * b22 * c22 ],
[ a21 * b21 * c21, a22 * b22 * c22 ]]]
为了获得矩阵U_1、U_2和U_3,我们需要使用一种张量分解算法,如交替最小二乘法(Alternating Least Squares, ALS)或梯度下降法。这里我们不会详细介绍这些算法,但在实际应用中,它们可以用于找到最佳的分解矩阵,从而使张量A的重构误差最小。
张量分解在信号处理、数据挖掘和机器学习等领域有广泛应用。例如,在信号处理中,张量分解可以用于提取信号中的基本成分,从而实现信号分离、降噪和压缩。在数据挖掘中,张量分解可以用于提取多维数据中的潜在模式和关系。在机器学习中,张量分解可以用于降维、特征提取和模型压缩等任务。
独立成分分析(ICA, Independent Component Analysis):通过寻找一个线性变换,将原始数据变换为统计上独立的分量,广泛应用于信号处理和数据分析。
独立成分分析(ICA)是一种用于信号处理和数据分析的技术,旨在将混合信号分离成独立的源信号。为了方便说明,我们将使用一个简单的例子。设有两个源信号s1(t)和s2(t),它们经过线性混合后形成观测信号x1(t)和x2(t)。
我们假设有以下两个源信号:
s1(t) = [2, 3, 4, 2] s2(t) = [1, 0, 1, 2]
线性混合的过程可以用矩阵表示,即:
X = A * S
其中X是观测信号矩阵,A是混合矩阵,S是源信号矩阵。我们设混合矩阵为:
A = [(1, 2), (2, 1)]
那么,观测信号矩阵为:
X = [(1, 2), * [(2, 3, 4, 2), (2, 1)] (1, 0, 1, 2)]
X = [(4, 3, 6, 6), (5, 6, 9, 6)]
现在我们要利用ICA从观测信号x1(t)和x2(t)中恢复原始源信号s1(t)和s2(t)。
首先,我们需要对观测信号进行预处理。通常,这包括中心化和白化。中心化意味着让数据的均值为零,白化意
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









