



 本文深入探讨Python中的数据结构,包括列表、元组、字典、集合的特性与操作,以及字符串处理方法。同时,文章讲解了异常处理机制,提供变位词检测算法和经典数学问题解决方案。
本文深入探讨Python中的数据结构,包括列表、元组、字典、集合的特性与操作,以及字符串处理方法。同时,文章讲解了异常处理机制,提供变位词检测算法和经典数学问题解决方案。
1.列表
可以包含任意类型数据,有序的可变对象集合。+(连接),*(重复),len(长度)。append()在列表末尾增加一个对象。in(not in)操作符检查一个对象是否在一个集合中。remove()从列表中删除指定数据值的第一次出现。pop()根据对象索引值从现有列表删除和返回一个对象,如果没有指定索引值,将删除和返回列表中最后一个对象。extend()取一个对象列表作为唯一参数,将其中各个对象增加至现有列表,即列表合并。insert()取一个索引值和一个对象作为参数,将对象插入到现有列表中指定索引值前面,不能插入到末尾。sort()对列表进行排序。reverse()反转列表。del list[i]删除在该位置上的元素。alist.index(item) 返回列表中第一个等于 item 项的索引。alist.count(item) 返回列表中有多少项的值等于 item 。
first=[1,2,3],second=first,两者会共享这个列表的引用,即一个改变,另一个会随之改变,不是真正的复制。copy(),完成真正的复制。列表切片,letters[0:10:3],开始索引,结束索引,步长,每3个字母选择1个,直到(但不包括)索引位置10。letters[3:],跳过前3个字母。letters[:10],直到(但不包括)索引位置10。letters[::2],每2个字母选择1个。[::-1],[13:3:-1]逆序切片。
>>> sqlist=[x*x for x in range(1,11) if x%2 != 0]
>>> sqlist
[1, 9, 25, 49, 81]
生成列表四种方法:

2.dir(random),显示python中与某个东西相关的所有属性
3.help(random.randint),帮助文档
4.list(range(5,10)),list将range的输出转换为列表。list(“dsdsd”),把字符串转换为列表。range(start,stop,step),指定开始,结束,步长。
5.元组,有序的不可变对象集合。
6.phase=‘’.join(list),使用指定字符拼接,把list转换回字符串。
7.字典,无序。
for k in sorted(found):print(k,found[k])
for k,v in sorted(found.items()):print(k,v)
字典的键必须初始化,if 'pears' not in fruits:fruits['pears']=0等价于fruits.setdefault('pears',0)。
key,value 和 item 这三个函数分别能够给出字典中所有的键、值、键值对。mydict[‘key’] 返回 key 这个键所对应的值,如果 key 不存在,则会报 错 。key in mydict 如果 key 这个键在字典中,那么就返回 True,如果不在, 就返回 False 。del mydict[‘key’] 在字典中移除 key 这个键所对应的键值对 。adict.keys() 以列表的形式返回 adict 中的所有键(key) 。 adict.values() 以列表的形式返回 adict 中的所有值(value) 。 adict.items() 以列表的形式返回 adict 中的所有键值对,列表的每个 元素是包含键和值的元组 。adict.get(key) 返回 key 所对应的值,如果 key 不存在,就返回 None 。 adict.get(key,alt) 返回 key 所对应的值,如果 key 不存在,就返回 alt 。
8.集合
大括号包围,自动去重,无序。vowels=set(’aeeiouu‘),传递一个序列(如字符串)快速生成一个集合。|(并集) 集合 A | 集合 B 返回一个新集合,这个集合是集合 A,B 的并集 。&(交集) 集合 A & 集合 B 返回一个新集合,这个集合只有集合 A,B 共有的 元素,是集合 A,B 的交集。- 集合 A – 集合 B 返回一个新集合,这个集合是集合 A 除去 A 与 B 共有的元素(A-(A∩B)) 。<= 集合 A <= 集合 B 判断集合 A 中的所有元素是否都在集合 B 中,返 回布尔值 True 或者 False 。A.union(B)
返回一个新集合,这个集合含有 A,B 中的所有元素, 是集合 A,B 的并集 。A.intersection(B) 返回一个新集合,这个集合只有集合 A,B 共有的元 素,是集合 A,B 的交集 。A.difference(B) 返回一个新集合,这个集合是集合 A 除去 A 与 B 共 有的元素(A-(A∩B)) 。A.issubset(B) 判断集合 A 中的所有元素是否都在集合 B 中,返回 布尔值 True 或者 False 。A.add(item) 把 item 这个元素添加到集合 A 中 。A.remove(item) 从集合 A 中除去 item 这个元素 。
9.print(a,b,end=''),输出a,b之间有空格,无换行。print("Hello","World", sep="***") Hello***World。print("Hello","World", end="***") Hello World*** 。print("%s is %d years old." % (aName, age)) 。

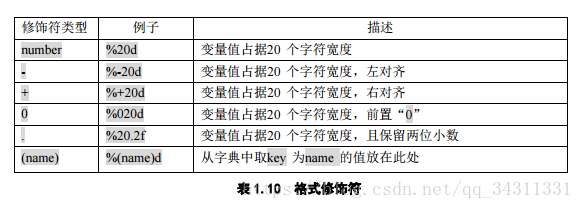
>>> itemdict = {"item":"banana","cost":24}
>>> print("The %(item)s costs %(cost)7.1f cents"%itemdict)
The banana costs 24.0 cents
10.字符串
astring.center(w) 返回一个字符串,w 长度,原字符串居中 。astring.count(item) 返回原字符串中出现 item 的次数 。astring.ljust(w) 返回一个字符串,w 长度,原字符串居左 。astring.lower() 返回一个字符串,全部小写。astring.rjust(w) 返回一个字符串,w 长度,原字符串居右。astring.find(item) 查询 item,返回第一个匹配的索引位置 。astring.split(schar) 以 schar 为分隔符,将原字符串分割,返回一个列表 。
11.异常处理
try:
except:
程序员可以通过使用 raise 语句自己制造运行异常。
>>> if anumber < 0:
raise RuntimeError("You can't use a negative number")
12.最著名的寻找最大公因数的方法是欧几里得算法
def gcd(m,n):
while m%n != 0:
m = n
n = m%n
return n
13.变位词检测
如果一个字符串是 另一个字符串的重新排列组合,那么这两个字符串互为变位词。
1.尽管 s1 和 s2 并不相同,但若为变位词它们一定包含完全一样的字符,利用这一特点,我们可以 采用另一种方法。我们首先从 a 到 z 给每一个字符串按字母顺序进行排序,如果它们是变位词,那么 我们将得到两个完全一样的字符串。sort()。
2.计数比较法
解决变位词问题的最后一个方法利用了任何变位词都有相同数量的 a,相同数量的 b,相同数量 的 c 等等。
14.栈
可以用于反转项的顺序。栈是一 个有序的项的集,项添加和删除的一端称为“顶”。栈的命令是按后进先出进行的。
Stack()创建一个新的空栈。它不需要参数,并返回一个空栈。
Push(item)将新项添加到堆栈的顶部。它需要参数 item 并且没有返回值。
pop()从栈顶删除项目。它不需要参数,返回 item。栈被修改。
peek()返回栈顶的项,不删除它。它不需要参数。堆栈不被修改。
isEmpty()测试看栈是否为空。它不需要参数,返回一个布尔值。
size()返回栈的项目数。它不需要参数,返回一个整数。
15.队列
●·Queue()创建一个空队列对象,无需参数,返回空的队列;
●enqueue(item)将数据项添加到队尾,无返回值;
●·dequeue()从队首移除数据项,无需参数,返回值为队首数据项;
●·isEmpty()测试是否为空队列,无需参数,返回值为布尔值;
●size()返回队列中的数据项的个数,无需参数。
16.Josephus 问题
为了模拟这个环状结构,我们会用到队列。每经过“num”次出队入队的过程后,站在队首的孩子就会永 久离开队列,游戏将在新的圆圈中继续进行。这个过程会一直持续到只有一个名字剩下(即队列规 格为 1 时)。
def hotPotato(namelist, num):
simqueue = Queue()
for name in namelist:
simqueue.enqueue(name)
while simqueue.size() > 1:
for i in range(num):
simqueue.enqueue(simqueue.dequeue())
simqueue.dequeue()
return simqueue.dequeue()

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









