







Coding Skill目录下的所有Tutorials、Notes博客都会不定期迭代更新
文章目录
卷积神经网络CNN
像素、分辨率
http://baijiahao.baidu.com/s?id=1601797930021194629&wfr=spider&for=pc
https://zhidao.baidu.com/question/252088649.html
图像质量评价
What Is CNN?
对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法。

每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。
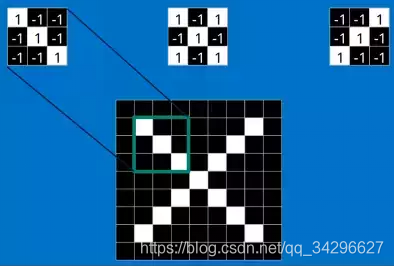
当给你一张新的图时,CNN并不能准确地知道这些features到底要匹配原图的哪些部分,所以它会在原图中每一个可能的位置进行尝试。这样在原始整幅图上每一个位置进行匹配计算,我们相当于把这个feature变成了一个过滤器。这个我们用来匹配的过程就被称为卷积操作,这也就是卷积神经网络名字的由来。
这个卷积操作背后的数学知识其实非常的简单。要计算一个feature和其在原图上对应的某一小块的结果,只需要简单地将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可。如果两个像素点都是白色(也就是值均为1),那么11 = 1,如果均为黑色,那么(-1)(-1) = 1。不管哪种情况,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。如果一个feature(比如nn)内部所有的像素都和原图中对应一小块(nn)匹配上了,那么它们对应像素值相乘再累加就等于n2,然后除以像素点总个数n2,结果就是1。同理,如果每一个像素都不匹配,那么结果就是-1。具体过程如下:
最后整张图算完,大概就像下面这个样子:

为了完成我们的卷积,我们不断地重复着上述过程,将feature和图中每一块进行卷积操作。最后通过每一个feature的卷积操作,我们会得到一个新的二维数组。这也可以理解为对原始图像进行过滤的结果,我们称之为feature map,它是每一个feature从原始图像中提取出来的“特征”。其中的值,越接近为1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
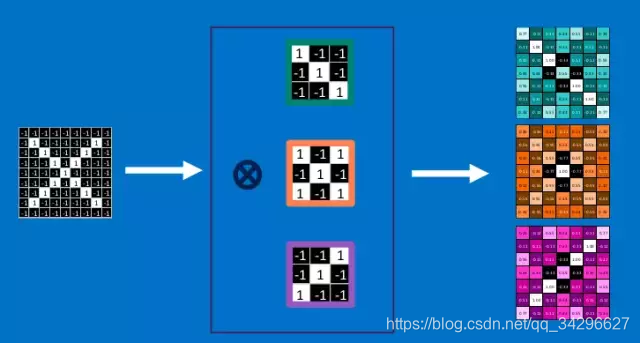
这样我们的原始图,经过不同feature的卷积操作就变成了一系列的feature map。我们可以很方便,直观地将这整个操作视为一个单独的处理过程。在CNN中,我们称之为卷积层(convolution layer),这样你可能很快就会想到后面肯定还有其他的layer。
Why CNN?
事实上,可以这样理解 VGGNet 的结构: 前面的卷积层是从图像中提取 “特征”, 而后面的全连接层把图片的“特征”转换为类别概率。真中, VGGNet 中的浅层(如 convl_l, conv1_2 ),提取的特征往往是比较简单的(如检测点、线、 亮度), VGGNet中的深层(如conv5 1 conv5 2), 提取的特征往往比 较复杂(如有无人脸或某种特定物体 )。
VGGNet 的本意是输入图像 , 提取特征,并输出图像 类别 。 图像风格迁 移正好与真相反 ,输入的是特征,输出对应这种特征的圄片
CNN Theory
一文详解卷积神经网络的演变历程!
https://mp.weixin.qq.com/s/bBQGDyh8pflBpYSsBuEYTA
教程 | 如何使用纯NumPy代码从头实现简单的卷积神经网络
https://mp.weixin.qq.com/s?__biz=MzU2MDc1MjEyMQ==&mid=2247486116&idx=4&sn=66dd2be47d1680bfbac5f050b08ce811&source=41#wechat_redirect
https://github.com/ahmedfgad/NumPyCNN
图文并茂地讲解卷积神经网络
https://mp.weixin.qq.com/s/ixwEVn_WMkH28w5aYITnBw
卷积神经网络VGG16这么简单,为什么没人能说清?
https://mp.weixin.qq.com/s/D5Fx0yx9FJb5gF93-c0xZA
[透析] 卷积神经网络CNN究竟是怎样一步一步工作的?
https://mp.weixin.qq.com/s/G5hNwX7mnJK11Cyr7E5b_Q
从AlexNet剖析-卷积网络CNN的一般结构
https://mp.weixin.qq.com/s/D6ok6dQqyx6cCJKc2M8YpA
卷积神经网络CNN学习笔记
https://mp.weixin.qq.com/s/t8jg_bpEcQiJmgIqKarefQ
变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作
https://mp.weixin.qq.com/s/V6o7rjmIaY6uhSS-H1TLcw
一文读懂 12种卷积方法(含1x1卷积、转置卷积和深度可分离卷积等)
https://mp.weixin.qq.com/s/287vamTc6QD4wo6maX0dbQ
卷积神经网络基础
https://mp.weixin.qq.com/s/ZHV-lyTUAG3CwqlxaRD62g
全卷积网络
https://mp.weixin.qq.com/s/TBdKb0rAuQPqUeSQKdM9WA
反卷积介绍
https://mp.weixin.qq.com/s/U_bFm0iuaTwOUNgN-NMWDQ
七个基本框架TensorFlow代码实战
https://mp.weixin.qq.com/s/CrKO2_0zYpe_BeV-KA05Yg
改进卷积神经网络,你需要这14种设计模式
https://mp.weixin.qq.com/s/Lh_lJNvV9BGhc6no2ln-_g
卷积神经网络调参经验
https://blog.youkuaiyun.com/qq_28413479/article/details/77542818
bp调参tricks
https://blog.youkuaiyun.com/zouxy09/article/details/45288129
High Parameters Skills
learning rate setup rules
https://blog.youkuaiyun.com/u012513618/article/details/78454652
https://blog.youkuaiyun.com/qq_33485434/article/details/80452941

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









