




 本文探讨C++中虚继承的概念及其实现细节,包括空类的大小、虚基类的额外开销、对齐问题、类对象布局以及成员函数的绑定等问题。特别关注虚继承对类大小的影响以及数据成员的存取机制。
本文探讨C++中虚继承的概念及其实现细节,包括空类的大小、虚基类的额外开销、对齐问题、类对象布局以及成员函数的绑定等问题。特别关注虚继承对类大小的影响以及数据成员的存取机制。
当X,Y,Z,A中没有任何一个class内有明显的数据,仅仅表示继承的关系。
class X{};
class Y :public virtual X {};
class Z :public virtual X {};
class A :public Y, public Z {};
X,Y,Z,A的大小是多少呢?在本机上的实验结果。
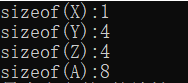
为什么空class的大小是1呢?
其实它隐藏了1byte大小,被编译器安插进去了一个char,这使得class的两个objects在内存中配置独一无二的地址:
X a, b;
if (&a != &b)
cout << "unique address!" << endl;
![]()
至于Y和Z的大小都是4(在我的机器上是4),这个大小和机器有关,也和编译器有关。事实上Y和Z的大小受到三个因素的影响:
1.语言本身所造成的额外负担(overhead)。当语言支持虚基类(virtual base classes),就会导致一些额外的负担。在继承类(derived class)中,这个额外负担反映在某种形式的指针上。它或者指向虚基类subobject,或者指向一个相关表格;表格中存放虚基类subobject的地址,或者是其偏移位置(offset)。在我的机器上是4bytes。
【subobject是实例对象中继承自基类A的部分就是类B的基类子对象了,例子中a就是类B的subobject】
class A{
public:
int a;
}
class B:virtual public A{
public:
int b;
}
2.编译器对于特殊情况所提供的优化处理。虚基类X subobject的1bytes大小同样出现在class Y和Z身上。某些编译器对empty virtual base class 提供特殊支持(不包含这1bytes大小),我的编译器提供这项特殊处理。所以本来是1byte + 4byte 存储大小会因为对齐变成8bytes,但是却因为优化,成为4bytes。
3.Allgnment(对齐)的限制。class Y 和 Z 如果在不支持优化处理的编译器下,内存大小4bytes + 1bytes,在大部分机器上大小会收到alignment的限制,使得它们能够更有效的在内存中存取,如果没有优化的编译器,必须填补3bytes,最终结果就是8bytes。
NOTE:alignment就是将数值调整到某数的整数倍。在32位机器上,通常alignment为4bytes,使得bus的“运输量”达到最高效率
Empty虚基类已经成C++ OO设计的特有属于,提供一个虚接口,没有任何数据定义。某些新的编译器对此提供特殊处理,在此策略下,一个empty虚基类被视为继承类对象(derived class object)最开头的部分,也就是说它没有花费任何的额外空间,这样就节省了上述第二点的1bytes。
c++对class X Y Z的对象布局:
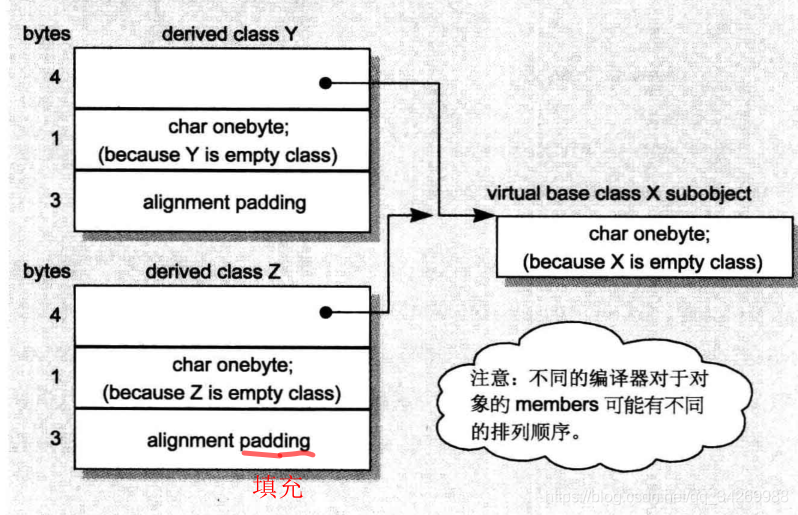
没有特殊处理的对象布局
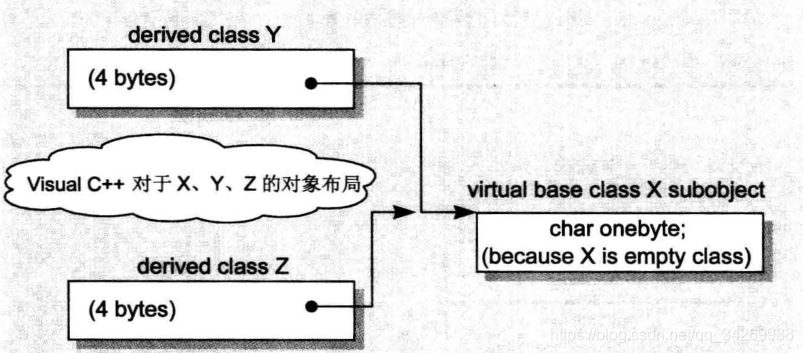
有特殊处理的编译器的对象布局
class A的大小是多少呢?答案是8。
一个虚基类subobject只会在继承类中保存一份实例,不管它在class继承体系中出现了多少次!class A的大小由以下几点决定:
- 被大家共享的唯一一个class X实例,大小为1byte。(和我机器上的实际情况不符---没搞懂)
- Base class Y大小,减去“虚基类X而配置的1byte”的大小,结果是4bytes,Base class Z也是,一共8bytes
- class A自己的大小:0 byte
- class A的alignment,此时正好8byte,不用对齐。
NOTE:如果我们在虚基类X中放置一个(及以上)的数据成员,两种编译器就会产生出完全相同的对象布局。
第三章类的数据成员(data members)和类的层次结构(class hierarchy)是中心议题。
Nonstatic data members放置的是“个别的class object”感兴趣的数据;static data members则放置的是“整个class”感兴趣的数据
c++对象模型把数据直接存放在每一个类对象之中,对于继承(无论是虚继承还是非虚继承)而来的非静态数据成员也是一样。并没有定义其间的排列顺序。至于静态数据成员,则被放置在程序的一个全局数据段(??)(global data segment)中,不会影响个别的类对象大小。在程序中,不管类产生多少个对象,静态数据成员永远只有一份实例(即使该类没有任何对象实例,其静态数据成员也是存在)。但是一个模板类的静态数据成员行为稍有不同。
每一个类对象的大小有时候比你想象的要大,原因是:
- 由编译器自动加上额外数据成员,用以支持某些语言特性(主要是各种virtual特性)
- alignment(边界调整)的需要
3.1data member的绑定(The Binding of a Data Member)
类的内部和外部都定义了一个testVal ,如果返回的话肯定是返回class内部的那个,结果为3。
int testVal = 5;
typedef int length;
class Test {
public:
void test() { cout<<testVal<<endl; }
};
void main() {
Test t;
t.test();
}
在早期c++编译器上,如果对testVal 做出取用操作,会返回那个全局的testVal ,这样的绑定时不在大家预期之中的!因此导出早期C++的防御性程序设计风格:
1.把所有数据成员都放在class声明起头出,以保证正确的绑定:
int testVal=5;
class Test {
public:
int testVal=3;
void test() { cout<<testVal<<endl; }
};
2.把所有的内敛函数,不管大小都放在class声明之外(就是把内敛函数都在类外定义,这样不是速度就降低了很多么!):
class Test {
public:
int testVal =3;
void test();
};
void Test::test(){
cout<<testVal<<endl;
}
C++ Standard以“member scope resolution rules”来精炼这个“rewriteing rule”,其效果是,如果一个内敛函数在类声明之后立刻被定义,那么就还是对其评估求值(evaluate)。(真是读不懂这句话,但是知识点就是以下两个)
1.如果是在函数体内的数据绑定就是正常的绑定
2.如果是在函数的参数列表中还是会出现问题
通过一个简单的例子就能说明,因为如果对一个成员函数本体分析(就是执行函数体内部的语句),这个操作是在整个类的声明之后才开始的,所以test函数返回的testVal,因为整个类声明完了,所有的成员类型都知道了,这个时候已经由类中的testVal替代了全局的testVal,所以输出结果:3;然而对于一个成员函数的函数列表这样就会出现问题,因为在查看类声明的时候,会检查每个成员函数的返回类型,函数的参数列表,成员变量的类型(就是除了函数体内部不查其他都知道了),所以test2函数时,length类型是int型,输出结果是3,test3成员函数时,由于已经看到length类型定义成double,所以返回值是3.5。
int testVal = 5;
typedef int length;
class Test {
public:
void test() { cout<<testVal<<endl; }
void test2(length x) { cout << x << endl; }
typedef double length;
void test3(length x) { cout << x << endl; }
int testVal = 3;
};
void main() {
Test t;
t.test();
t.test2(3.5);
t.test3(3.5);
}

改正方法:采用防御式编程,直接把length类型声明提到class起始处。
3.2data member的布局( Data Member Layout)
已知一下一组数据成员:
class M {
public:
int a=1;
int b = 2;
int c = 3;
static const int val = 5;
int d = 4;
static const int val2 = 5;
int e = 5;
}
非静态成员在类对象中排列顺序和其被声明的顺序一样,任何中间接入的静态数据成员都会不会放进对象布局之中。静态数据成员存放在程序的数据段之中,和每个类对象无关。
【数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域】
C++标准要求,在同一个访问块(也就是private,public,protected等区段),成员的排列只需要符合“较晚出现的成员在类对象中有较高的地址”即可。这也就是表明成员的存储地址并不是连续排列,什么东西可以介于成员之间呢?答案是成员的边界调整(alignment)可能需要填补一些bytes。
编译器还可能会合成一些内部使用的数据成员来支持整个对象模型,如vptr。目前所有的编译器都把它安插在每一个“内涵虚函数的类”的对象中。vptr会被放在什么位置呢?传统上它放在所有显示声明的成员最后。如今,也有一些编译器把vptr放在类对象的最前端。C++标准秉承“对布局所持放任态度”,允许编译器把那些内部产生的成员自由放在任何位置上,甚至放在程序员声明出来的成员之间。
C++标准也允许编译器将多个访问块(access sections)之间的数据成员自由排列而不必在乎它们class声明的顺序,编译器可以随意把b,c放在a前面,但是没有编译器会这样做,还是按序的排列,如下:
class M {
public:
int a=1;
protected:
int b = 2;
int c = 3;
private:
int d = 4;
int e = 5;
}
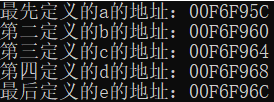
目前各家编译器都是把一个以上的访问块(access sections)连锁在一起,依照声明的顺序成为一个连续区块。访问块(access sections)的多寡不会带来额外附带,一个块8个变量和八个块1个变量得到的对象大小是一致的。
3.3data member的存取
point3d origin;
origin.x = 0.0;
你可能会问x的存取成本是什么?答案视x和point3d如何声明而定。
- x可能是静态成员;也可能是非静态成员。
- point3d可能是独立(非派生类);也可能是单一基类的派生类;甚至是多重继承或虚继承的。
如果我们定义一个对象和一个指针,通过成员运算符"."和指针运算符“->”,两种存取方式差异大吗?
point3d origin,*pt = &origin;
origin.x = 0.0;
pt->x =0.0;
答案是在本节最后揭晓。
静态数据成员(Static Data Members)
静态数据成员,被编译器提出与class之外(???啥意思),并视为一个global变量(只在class声明范围之内课件)。每个成员的存取许可(private,protected或public),以及与类的关联(???),并不会招致空间或者时间的额外负担——无论是每个类对象还是静态数据成员本身。
每一个静态数据成员只有一个实例,存放在程序的数据段之中。每次程序取用静态成员时,就会被内部转换为对该唯一extern实例的直接参考操作(?不理解),简单的例子:
original.chunkSize = 250;
//equals to
//Point3d::chunkSize =250;
pt->chunkSize = 250;
//equals to
//Point3d::chunkSize =250;
也就是说:虽然静态成员变量不在某一个具体的类对象之中,但是我们仍然可以通过成员运算符"."和指针运算符“->”来存取。存取静态成员并不需要通过类对象。
即使chunkSize 是从一个非常复杂的继承关系中继承而来的成员,或者它是一个虚基类的虚基类(virtual base class 的virtual base class)(或者是其他非常复杂的继承结构)的成员。也无关紧要,因为程序中静态成员只有唯一的实例,而其存取路径仍然是那么直接。
【静态成员怎么由函数调用和某些语法获取?没懂】
若静态成员时经函数调用,或者其他某些语法获取?
foobar().chunkSize = 250;
C++标准明确要求foobar()必须被求值(evaluated),虽然其结果并无用处。下面是一种可能的转化:
//foobar().chunkSize = 250;
//evaluate expression,discarding result
(void) foobar();
Point3d.chunkSize = 250;
若取一个静态数据成员的地址,会得到一个指向其数据类型的指针,而不是一个指向其类成员的指针,因为静态成员并不在某一个类对象之中。
![]()
若有两个类,每个类都声明一个静态成员变量freeList,那么当他们都放在程序的数据段时,就会导致名称冲突。编译器的解决方法是暗中对每一个静态数据成员编码(name-mangling),以获得一个独一无二的程序识别代码。
class object 翻译成类对象好像不对,subobject 翻译成基类中有的那部分。感觉这翻译错了,下面还是再用英文表述。
非静态数据成员(Nonstatic Data Members)
非静态数据成员直接存放在每一个类对象中,除非由显示(explicit)或者隐式的(implicit)类对象,都这无法直接存取它们。
只要程序员在一个成员函数中直接处理一个非静态数据成员,所谓的“implicit”类对象就会发生。例如如下代码:
Point3d
Point3d::translate(const Point3d &pt){
x += pt.x;
y += pt.y;
z += pt.z;
}
表面是对x、y、z直接存取,事实上是经由一个“implicit”类对象(由this指针表达)完成的,事实上这个函数参数是:
//成员函数的内部转化
Point3d
Point3d::translate(Point3d* const this,const Point3d &pt){
this->x += pt.x;
this->y += pt.y;
this->z += pt.z;
}
对一个非静态数据成员进行存取操作,编译器要把class object的起始地址加上数据成员的偏移位置(offset)。举个例子,如:
origin._y = 0.0;
那么&origin._y将等于:
&origin._y + (&Point3d::_y-1);
注意-1操作。指向数据成员的指针,其offset值总是被加上1,使得编译系统分出:
“一个指向数据成员的指针,用以指出类的第一个成员”
“一个指向数据成员的指针,没有指出任何成员”
每一个非静态数据成员的偏移位置在编译时期即可获知,甚至如果成员属于一个基类的部分(base class subobject)(派生自单一或多重继承串链)也是一样。(???不明白)。因此存取一个非静态数据成员,其效率和存取一个C 结构体成员或者一个非继承类的成员时一样的。
让我们看一看虚拟继承。虚拟继承将为“经由base class subobject(基类中的部分)”来存取类成员导入一层新的间接性,比如:
point3d *pt3d;
pt3d->_x = 0.0;
其执行效率在_x是一个结构体成员,一个类成员,单一继承、多重继承的情况下都完全相同。但如果_x是一个虚基类的成员,存取速度会稍慢一点。
如果我们定义一个对象和一个指针,通过成员运算符"."和指针运算符“->”,两种存取方式差异大吗?
point3d origin,*pt = &origin;
origin.x = 0.0;
pt->x =0.0;
答案是:当 point3d 是一个继承类,其继承结构有一个虚基类,并且存取的成员(如本例中的x)是一个从该虚基类继承而来的成员时,就会有重大的差异。此时我们不能说pt必然指向哪一种类类型(因此,我们也就不知道编译时期这个成员这正的偏移位置),所以这个存取操作必须延迟至执行期,经过一个额外的间接导引才能解决。如果使用origin就不会有这些问题,其类型无疑是point3d类,而即使它继承自虚基类,成员的偏移位置也在编译时期就固定了。编译器甚至可以静态地由origin就解决对x的存取。
思考:感觉这就是由于多态“便利”引起的,当使用指针来调用函数的时候。只有在程序运行时才知道是调用子类的函数还是基类的函数。如果使用引用也会有这种原因吧!

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









