









环境配置
linux环境配置
该配置是在虚拟机中linux系统安装好的前提下,虚拟机安装可查询其他网上教程。 注:部分命令视linux版本而定
防火墙
- 关闭防火墙:systemctl stop firewalld.service
- 禁用防火墙:systemctl disable firewalld.service
- 查看防火墙:systemctl status firewalld.service
建议使用禁用命令,关闭防火墙操作在linux系统重启收失效
Selinux
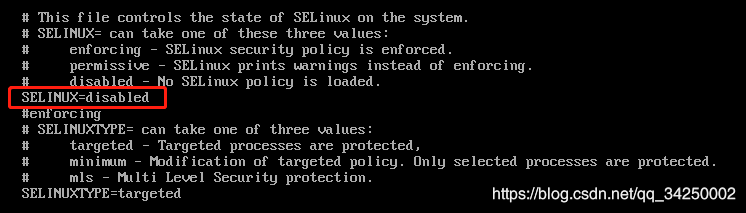
vi /etc/selinux /config
将 SELINUX=enforcing 改为 SELINUX=disabled
IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33 //最后一个名称数字略有不同
//修改
BOOTPROTO=static
ONBOOT=yes
//IP
IPADDR=192.168.X.X
GATEWAY=192.168.X.2 //网关IP
DNS1=8.8.8.8
DNS2=8.8.4.4
NETMASK=255.255.255.0
vi /etc/resolv.conf
nameserver 8.8.8.8
nameserver 8.8.4.4
重启网卡:servie network restart
主机名
修改主机名
hostnamectl set-hostname bigdata111
IP 和主机名关系映射
vi /etc/hosts
192.168.X.51 bigdata111
. //若配置集群则需添加多条
.
.
在 windows 的 C:\Windows\System32\drivers\etc 路径下找到 hosts 添加映射
192.168.X.51 bigdata111
.
.
.
Hadoop环境配置
安装
解压
tar -zxvf soft/hadoop-2.6.4.tar.gz -C /home/uplooking/app/
环境变量
vim /etc/profile
// 加入以下内容:
export HADOOP_HOME=/home/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
//使配置文件生效:
source /etc/profile
ssh免密登录
- 生成公钥和私钥:ssh-key gen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥) - 将公钥拷贝到要免密登录的目标机器上
ssh-copy-id 主机名 1
配置集群
集群部署
| - | bigdata111 | bigdata112 | bigdata113 |
|---|---|---|---|
| HDFS | NameNode SecondaryNameNode DataNode | DataNode | DataNode |
| YARN | ResourceManager NodeManager | NodeManager | NodeManager |
配置文件
core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名 1:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.X.X/data/tmp</value>
</property>
hdfs-site.xml
<!--数据冗余数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary 的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>主机名 1:50090</value>
</property>
<!--关闭权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
yarn-site.xml
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>主机名 1</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置 7 天(秒) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
mapred-site.xml
<!-- 指定 mr 运行在 yarn 上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>主机名 1:10020</value>
</property>
<!--历史服务器页面的地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主机名 1:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/module/hadoop-3.2.1/etc/hadoop,
/opt/module/hadoop-3.2.1/share/hadoop/common/*,
/opt/module/hadoop-3.2.1/share/hadoop/common/lib/*,
/opt/module/hadoop-3.2.1/share/hadoop/hdfs/*,
/opt/module/hadoop-3.2.1/share/hadoop/hdfs/lib/*,
/opt/module/hadoop-3.2.1/share/hadoop/mapreduce/*,
/opt/module/hadoop-3.2.1/share/hadoop/mapreduce/lib/*,
/opt/module/hadoop-3.2.1/share/hadoop/yarn/*,
/opt/module/hadoop-3.2.1/share/hadoop/yarn/lib/*
</value>
</property>
- hadoop-env.sh、yarn-env.sh、mapred-env.sh(分别在这些的文件中添加下面的路径)
export JAVA_HOME=/opt/module/jdk1.8.0_144 //(注:是自己安装的路径)
格式化 Namenode
hdfs namenode -format
启动集群得命令
- Namenode 的主节点:sbin/start-dfs.sh
- Yarn 的主节点:sbin/stop-yarn.sh
- 或者:start-all.sh/stop-all.sh

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









