







Redis 实现分布式锁
前言
什么是分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,这个时候,便需要使用到分布式锁。
下面将以电商系统商品扣减为例
在一个电商系统中,如果一个客户进行下单操作,那么对应的要对实际的库存进行减扣操作,基于这样的一个场景,就会出现超卖的问题
基础代码
package com.example.demo.module.redisTest.controller;
import com.example.demo.common.dto.R;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("redisTestT")
public class RedisControllerT {
private final Logger log = LoggerFactory.getLogger(RedisControllerT.class);
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 设置测试数据
*/
@GetMapping("setData")
public R setData(){
redisTemplate.opsForValue().set("data","100");
return R.ok();
}
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if(data > 0){
int realData = data - 1;
redisTemplate.opsForValue().set("data",String.valueOf(realData));
log.info("商品扣减成功,剩余商品:"+realData);
return R.ok();
}
log.warn("库存不足......");
return R.fail("库存不足......");
}
}
上面的代码逻辑是说,当我们访问 /redisTestT/deductData 请求的时候说明用户进行了下单的操作,所以就要获取到当前的库存量,然后进行减一操作。将减一之后的结果更新到库存中。
那么问题来了,在单用户操作的场景下没有任何问题,或者说在单线程的场景下没有任何问题,那么一个电商系统并不是简单的就支持一个用户,它需要支持的高并发。也就是说支持多个用户同时下单的操作。那么这个时候就会出现问题。
下面就通过 Jmeter 来进行压测模拟。
Jmeter 的安装及使用
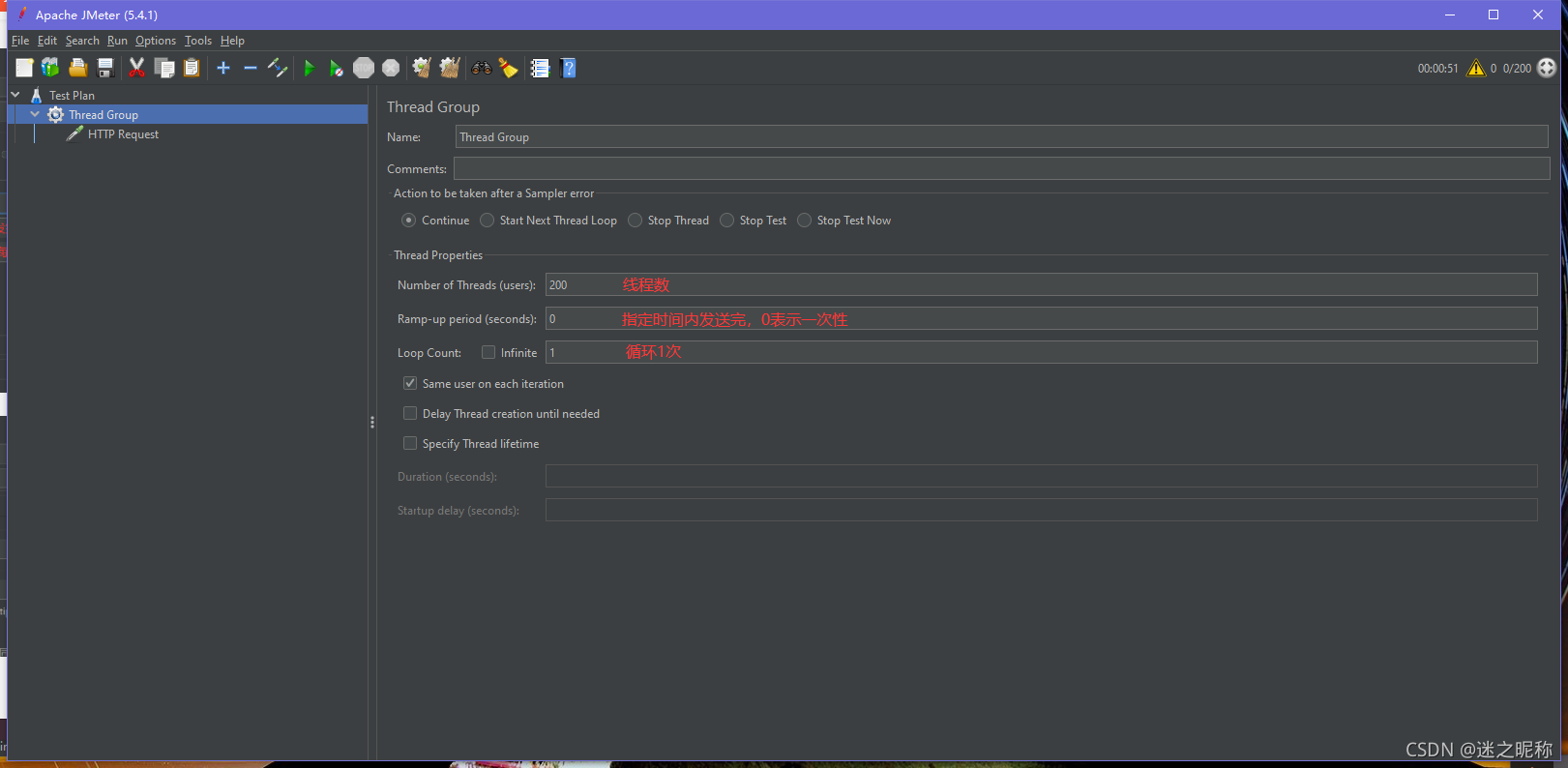
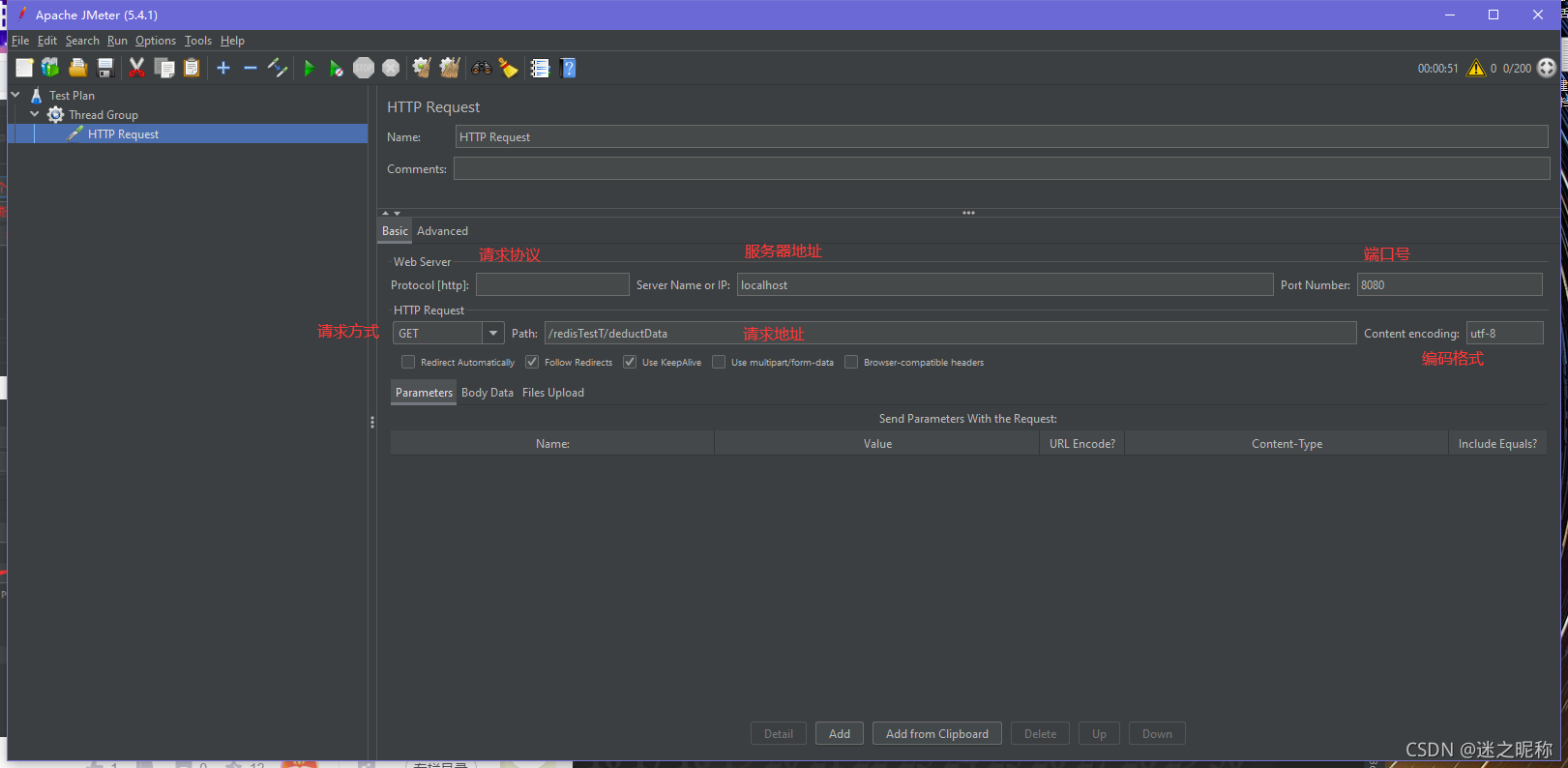
模拟结果:
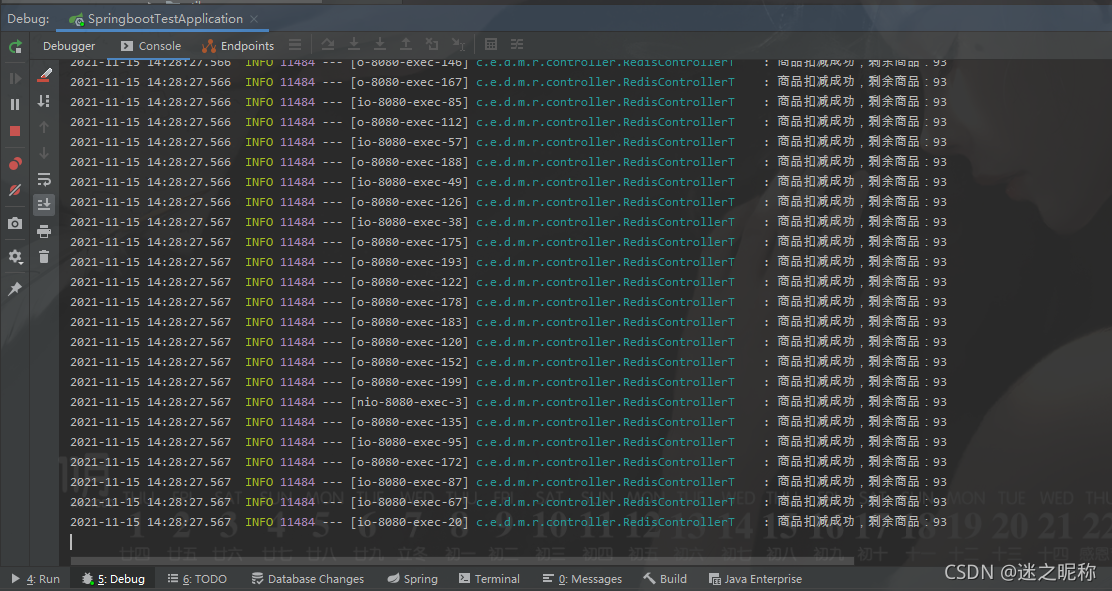
从上面截图中可以看到库存为 93 的时候,交易成功了很多订单,商品已经多卖出去了。
既然出问题了那么就要想办法解决啊?这个时候想到最多的就是多线程,既然线程和线程之间,数据处理不一致,能否使用 synchronized 加锁测试?
synchronized 加锁
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
synchronized (this) {
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if (data > 0) {
int realData = data - 1;
redisTemplate.opsForValue().set("data", String.valueOf(realData));
log.info("商品扣减成功,剩余商品:" + realData);
return R.ok();
}
log.warn("库存不足......");
return R.fail("库存不足......");
}
}
重新压测结果:
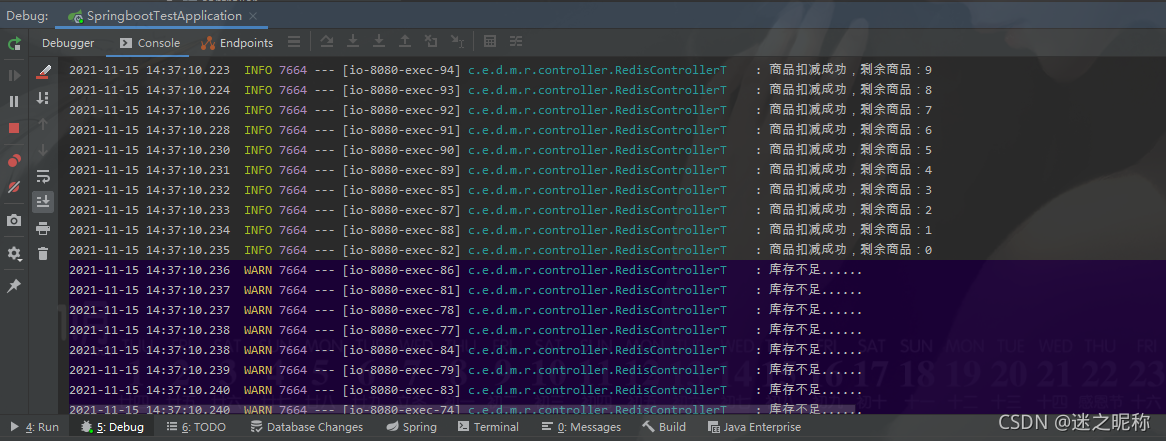
在单机模式下,添加 synchronized 关键字,的确能够避免商品的超卖现象!
但是在分布式微服务中,针对该服务设置了集群,synchronized 依旧还能保证数据的正确性吗?假设多个请求,被注册中心负载均衡,每个微服务中的该处理接口,都添加有 synchronized
synchronized只是针对单一服务器的 JVM 进行加锁,但是分布式是很多个不同的服务器,导致两个线程或多个在不同服务器上共同对商品数量信息做了操作!
使用 Redis 实现分布式锁
在 Redis 中存在一条命令 setnx (set if not exists) 如果不存在key,则可以设置成功;否则设置失败。
分布式锁原始模型
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
String key = "lock";
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
boolean lock = redisTemplate.opsForValue().setIfAbsent(key, "this is lock");
// 保存失败,表示存在线程正在执行扣减商品操作
if(!lock){
log.error("扣减失败,请稍后再试");
return R.fail("扣减失败,请稍后再试");
}
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if (data > 0) {
int realData = data - 1;
redisTemplate.opsForValue().set("data", String.valueOf(realData));
log.info("商品扣减成功,剩余商品:" + realData);
return R.ok();
}
// 执行完删除 key 释放锁
redisTemplate.delete(key);
log.warn("库存不足......");
return R.fail("库存不足......");
}
下面就来分析一下这个代码。
首先我们知道,在一个代码执行过程中都是从上到下进行执行的,那么如果上面这段代码在执行删减库存操作的时候出现了问题,那么就会导致最后释放锁的逻辑没有被执行到。那么其他的线程进来访问这个操作的时候就会出问题。所以这里做的第一步优化是对这个业务逻辑的异常进行捕获。并且将释放锁的逻辑放入到 finally 中,如下
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
String key = "lock";
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
boolean lock = redisTemplate.opsForValue().setIfAbsent(key, "this is lock");
// 保存失败,表示存在线程正在执行扣减商品操作
if(!lock){
log.error("扣减失败,请稍后再试");
return R.fail("扣减失败,请稍后再试");
}
try {
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if (data > 0) {
int realData = data - 1;
redisTemplate.opsForValue().set("data", String.valueOf(realData));
log.info("商品扣减成功,剩余商品:" + realData);
return R.ok();
}
}finally {
// 执行完删除 key 释放锁
redisTemplate.delete(key);
}
log.warn("库存不足......");
return R.fail("库存不足......");
}
这个逻辑相比上面其他的逻辑来说,显得更加的严谨。
但是如果服务器因为断电、系统崩溃等原因出现宕机,导致本该执行 finally 中的语句未成功执行完成!!同样出现 key 一直存在,导致死锁!
那么我们知道 finally 中的代码一定会执行么,我想是不一定的,在 Java 中 Exception 是可以被捕获的。机房停电,kill -9 等操作,导致整个的逻辑还没有来得及执行 finally 就出现问题。也就导致了刚刚的错误。这个时候就会想到,其实在 setnx 操作之后还可以对这个所进行一个超时时间的设置。也就是说进行了如下的一个优化。
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
String key = "lock";
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
// 设置超时时间
boolean lock = redisTemplate.opsForValue().setIfAbsent(key, "this is lock",30, TimeUnit.SECONDS);
// 保存失败,表示存在线程正在执行扣减商品操作
if(!lock){
log.error("扣减失败,请稍后再试");
return R.fail("扣减失败,请稍后再试");
}
try {
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if (data > 0) {
int realData = data - 1;
redisTemplate.opsForValue().set("data", String.valueOf(realData));
log.info("商品扣减成功,剩余商品:" + realData);
return R.ok();
}
}finally {
// 执行完删除 key 释放锁
redisTemplate.delete(key);
}
log.warn("库存不足......");
return R.fail("库存不足......");
}
做完这个过期时间设置之后,即使在操作过程中出现了 kill -9 这样的操作,也会在30秒之后自动的将锁进行释放,这样的话后续的操作线程还是可以获取到锁进行操作。
为一个公共组件来说,首先需要做的事情就是实现某种规则,那么这种规则如何实现,实现什么样的规则就需要使用到接口,对于一个锁来说,最主要的两个操作就是锁的获取,以及锁的释放操作,如下
Lock
package com.example.demo.common.redisLock;
public interface Lock {
/**
* 获取锁
*/
boolean getLock();
/**
* 释放锁
*/
boolean releaseLock();
}
RedisLock 实现类
package com.example.demo.common.redisLock;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
public class RedisLock implements Lock {
private static final Logger log = LoggerFactory.getLogger(RedisLock.class);
// 分布式锁 key 名称
private static final String lock = "lock";
@Autowired
private RedisTemplate<String,Object> redisTemplate;
// 获得锁
@Override
public boolean getLock() {
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
// 设置超时时间
return redisTemplate.opsForValue().setIfAbsent(lock, "this is lock", 30, TimeUnit.SECONDS);
}
// 释放锁
@Override
public boolean releaseLock() {
// 执行完删除 key 释放锁
return redisTemplate.delete(lock);
}
}
redisLock 锁使用
package com.example.demo.module.redisTest.controller;
import com.example.demo.common.dto.R;
import com.example.demo.common.redisLock.Lock;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("redisTestT")
public class RedisControllerT {
private final Logger log = LoggerFactory.getLogger(RedisControllerT.class);
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private Lock redisLock;
/**
* 设置测试数据
*/
@GetMapping("setData")
public R setData(){
redisTemplate.opsForValue().set("data","100");
return R.ok();
}
/**
* 扣减商品
*/
@GetMapping("deductData")
public R deductData(){
String key = "lock";
// 获取锁
boolean lock = redisLock.getLock();
// 保存失败,表示存在线程正在执行扣减商品操作
if(!lock){
log.error("扣减失败,请稍后再试");
return R.fail("扣减失败,请稍后再试");
}
try {
int data = Integer.parseInt(redisTemplate.opsForValue().get("data"));
if (data > 0) {
int realData = data - 1;
redisTemplate.opsForValue().set("data", String.valueOf(realData));
log.info("商品扣减成功,剩余商品:" + realData);
return R.ok();
}
}finally {
// 释放锁
redisLock.releaseLock();
}
log.warn("库存不足......");
return R.fail("库存不足......");
}
}
这个操作完成之后就需要考虑一下了,在整个的操作过程中,多线程访问,怎么能保证这个线程进入之后和其他线程进入之后获取到的就是自己拿到的那把锁,或者说,这锁应该在整个的应用中是单例存在的。这样如何保证呢?
因为我们知道在多线程执行过程中会涉及到一个指令重排序的操作,第一个线程进来之后正常的获取到锁了,注意这个是对 Redis 的操作,在 Redis 中设置了一个 lock,那么其他线程进入的时候其实已经开始准备执行 release 的操作了那么这个时候就会导致在 Redis 不存在 lock,后续的线程就会进行重新的设置。导致整个系统的死锁,或者是服务假死。那么就要保证当前线程操作当前锁。
这里先做了如下的一个操作
package com.example.demo.common.redisLock;
import cn.hutool.core.lang.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
public class RedisLock implements Lock {
private static final Logger log = LoggerFactory.getLogger(RedisLock.class);
// 分布式锁 key 名称
private static final String lock = "lock";
@Autowired
private RedisTemplate<String,Object> redisTemplate;
private String uuid;
// 获得锁
@Override
public boolean getLock() {
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
// 设置超时时间
uuid = UUID.randomUUID().toString();
return redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
}
// 释放锁
@Override
public boolean releaseLock() {
// 执行完删除 key 释放锁
if(uuid.equals(redisTemplate.opsForValue().get(lock))){
return redisTemplate.delete(lock);
}
return false;
}
}
首先从代码逻辑的角度上来说好像是可以保证了当前线程操作当前锁,那么带来的另外的问题就是这个 uuid 会被覆盖,这样就出现了线程安全问题,有人就说了可不可以考虑用一个不被覆盖的内容来进行操作呢?线程安全并且还可以在随着线程传递点东西,那么首选的就是 ThreadLocal 。
下面对代码进行如下的改进。
package com.example.demo.common.redisLock;
import cn.hutool.core.lang.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
public class RedisLock implements Lock {
private static final Logger log = LoggerFactory.getLogger(RedisLock.class);
// 分布式锁 key 名称
private static final String lock = "lock";
private ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
@Autowired
private RedisTemplate<String,Object> redisTemplate;
// 获得锁
@Override
public boolean getLock() {
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
// 设置超时时间
String uuid = UUID.randomUUID().toString();
stringThreadLocal.set(uuid);
return redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
}
// 释放锁
@Override
public boolean releaseLock() {
String uuid = stringThreadLocal.get();
// 执行完删除 key 释放锁
if(uuid.equals(redisTemplate.opsForValue().get(lock))){
stringThreadLocal.remove();
return redisTemplate.delete(lock);
}
return false;
}
}
在这里可以看到如果后续线程没有获取到锁之后会直接进行返回操作,在一定场景下并不是太满足场景业务要求。那么就需要进行一个优化操作,实现一个阻塞与非阻塞的调配。例如一个抢购的场景,抢购的商品就只有 100 个,而正好从各个地方过来的请求也只有 100 个,那么当第一个人下单的时候,这个时候其他人获取锁的时候都是 false,意味着后进入的 99 个用户其实是没有买到商品的。
那么这个时候就需要让锁支持一个阻塞操作。也就是说如果后续没有拿到锁,就一直尝试获取这个锁,而不是直接返回。对于直接返回的操作就可以看作是一个非阻塞的,而对于等待获取就是一个阻塞的。
这里就需要对分布式锁组件可以进行阻塞操作。这里采用了自旋的方式来实现。也就是先在外面定义一个锁标识,如果这个锁标识为获取到锁则直接返回,如果没有获取到锁则进入到一个死循环中,一直尝试去获取这个锁,直到获取到锁之后跳出本次的循环
package com.example.demo.common.redisLock;
import cn.hutool.core.lang.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
public class RedisLock implements Lock {
private static final Logger log = LoggerFactory.getLogger(RedisLock.class);
// 分布式锁 key 名称
private static final String lock = "lock";
// 获取锁的等待重试时间
private static final long acquireTimeout = 10 * 1000;
private ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
@Autowired
private RedisTemplate<String,Object> redisTemplate;
// 获得锁
@Override
public boolean getLock() {
// 获取锁,在 redis 中创建一个key
// setIfAbsent 如果该 key 在 redis 中存在则返回 false , 不存在则保存并返回 true
// 设置超时时间
String uuid = UUID.randomUUID().toString();
stringThreadLocal.set(uuid);
boolean lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
if(!lockTemp){
// 当重试获取锁时长超过限定时自动退出,返回获取失败
long endTime = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < endTime){
lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
if(lockTemp){
break;
}
}
// 死死等,等到获取到锁为止
// do{
// lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
// }while (lockTemp);
}
return lockTemp;
}
// 释放锁
@Override
public boolean releaseLock() {
String uuid = stringThreadLocal.get();
// 执行完删除 key 释放锁
if(uuid.equals(redisTemplate.opsForValue().get(lock))){
stringThreadLocal.remove();
return redisTemplate.delete(lock);
}
return false;
}
}
如果第一个请求过来了开始获取锁,所有的对于锁的请求问题都已经解决了,并且设置了 30 秒的过期时间,但是这里一定可以保证这个锁拿到之后,后续的业务操作就一定是低于 30 秒进行返回么,如果超过 30 秒那么就导致在释放锁的时候没有该锁这个一个问题,30 秒之后这个锁失效了,其他线程就会继续进入到该操作中,但是实际上当前操作并没有完成。那么这样这个问题怎么解决?
其实这个就是可以看做一个锁穿透,几乎可以看错一个操作超时导致其他操作超时,整个所有的锁都是不起作用的。但是如果这个时间设置太长的话,就会影响整个的系统性能。这个时候就需要在低性能的情况下达到 Redis 分布式锁的高可用。
继续对这个问题进行优化
package com.example.demo.common.redisLock;
import cn.hutool.core.lang.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* redis 分布式锁
*/
@Component
public class RedisLock implements Lock {
private static final Logger log = LoggerFactory.getLogger(RedisLock.class);
// 分布式锁 key 名称
private static final String lock = "lock";
// 获取锁的等待重试时间
private static final long acquireTimeout = 10 * 1000;
private ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Override
public boolean getLock() {
boolean lockTemp = false;
if(stringThreadLocal.get() == null){
// 开启子线程为锁延期,防止业务执行时间过长导致锁失效
// 一个线程执行完后下一个线程才可执行
Thread thread = new Thread(() -> {
while (true){
log.info("锁延期--------");
redisTemplate.expire(lock,30,TimeUnit.SECONDS);
// 每10秒延期一次
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// redis 值带上子线程id,释放锁时用于停止子线程
String uuid = String.format("%s:%s",thread.getId(),UUID.randomUUID().toString());
// value 存入 ThreadLocal 中,保证各线程独立,防止混乱覆盖
stringThreadLocal.set(uuid);
lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
if(!lockTemp){
// 当重试获取锁时长超过限定时自动退出,返回获取失败
long endTime = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < endTime){
lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
if(lockTemp){
break;
}
}
// 死死等,等到获取到锁为止
// do {
// lockTemp = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 30, TimeUnit.SECONDS);
// }while (!lockTemp);
}
if(lockTemp){
// 获得锁,子线程启动锁延期
thread.start();
}else{
stringThreadLocal.remove();
}
}
return lockTemp;
}
@Override
public boolean releaseLock() {
String uuid = stringThreadLocal.get();
if(uuid != null){
int id = Integer.parseInt(uuid.split(":")[0]);
Thread thread = findThread(id);
thread.stop();
log.info("子线程停止------------");
if(uuid.equals(redisTemplate.opsForValue().get(lock))){
redisTemplate.delete(lock);
stringThreadLocal.remove();
return true;
}
}
return false;
}
private static Thread findThread(long threadId){
ThreadGroup threadGroup = Thread.currentThread().getThreadGroup();
while (threadGroup != null){
Thread[] threads = new Thread[(int)(threadGroup.activeCount()*1.2)];
int count = threadGroup.enumerate(threads,true);
for (int i=0;i<count;i++){
if(threads[i].getId() == threadId){
return threads[i];
}
}
threadGroup = threadGroup.getParent();
}
return null;
}
}
到这里整个的分布式的逻辑就完成了。当然这里使用自己编写的方式来实现分布式锁,但是在很多的框架中都有所实现,仅供参考。

















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









