







接着上一篇的dubbo的服务发布
上一篇讲完dubbo的远程服务发布之后,到了org.apache.dubbo.registry.integration.RegistryProtocol#export的doLocalExport(originInvoker, providerUrl)调用之后,本篇看一下dubbo在远程服务发布完成之后对zookeeper的连接等操作
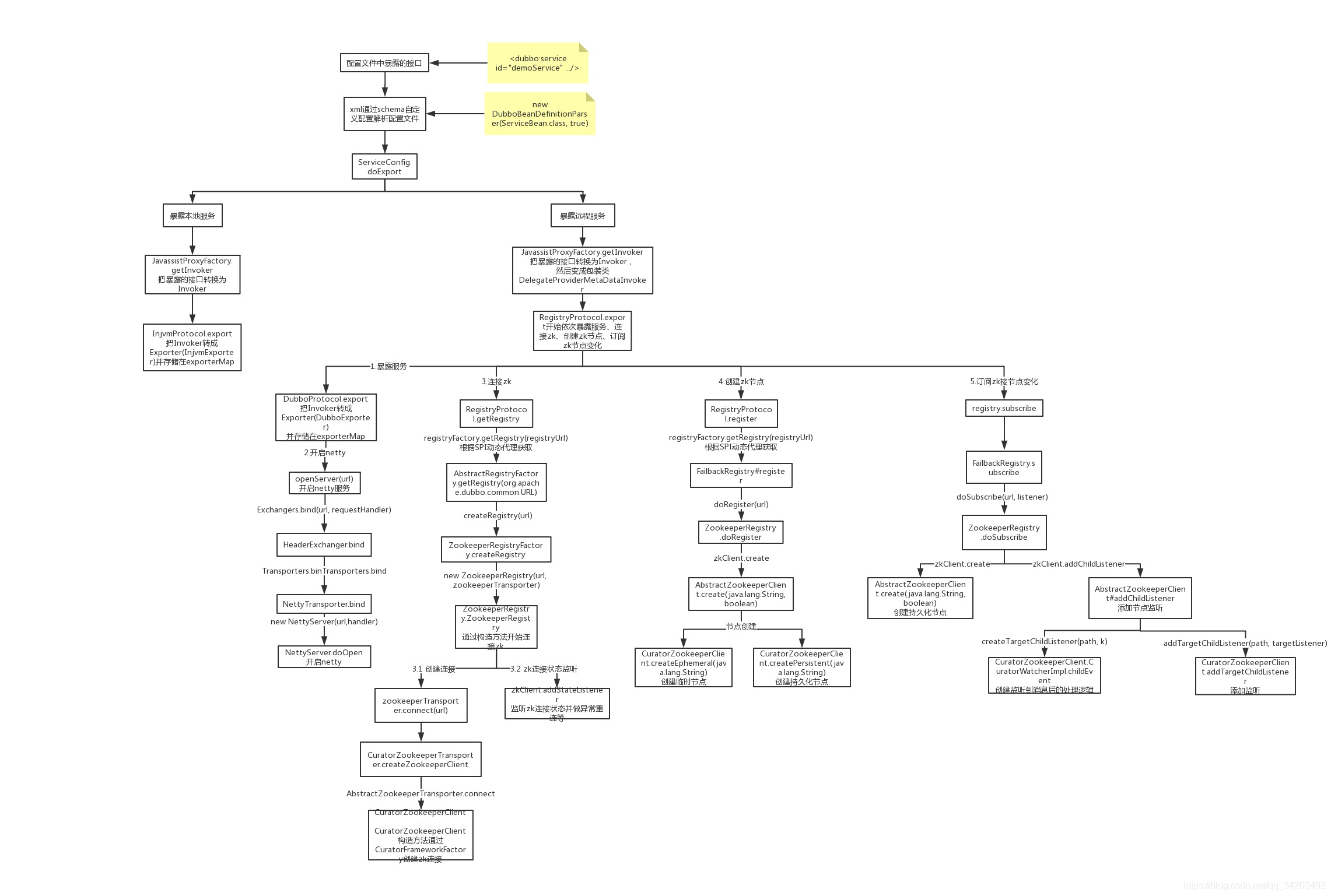
一. 创建zk连接
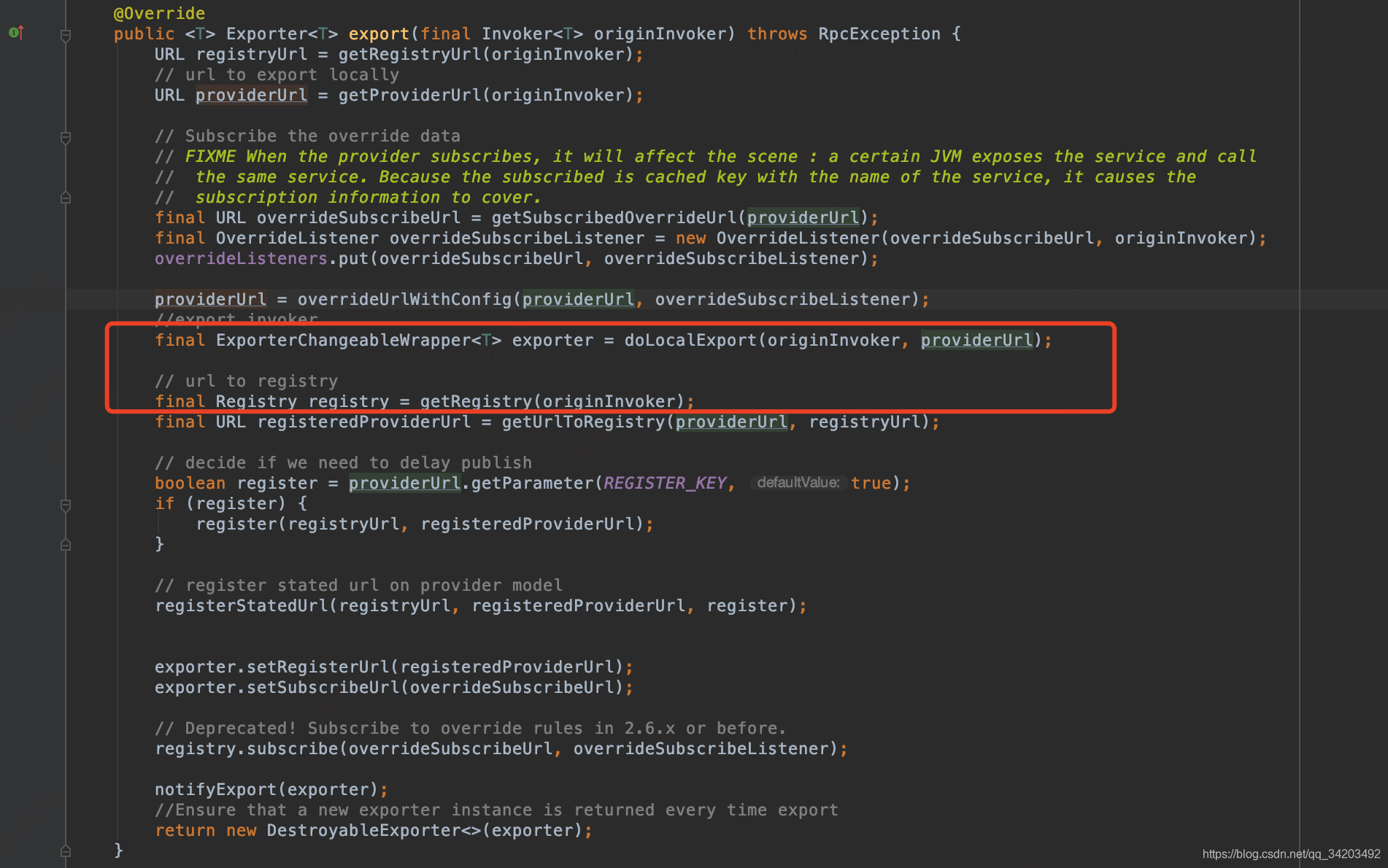
首先进入org.apache.dubbo.registry.integration.RegistryProtocol#getRegistry方法:
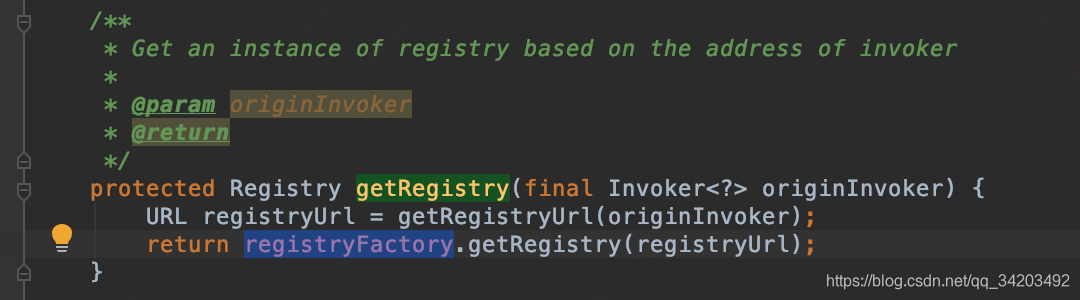
这里的registryFactory实际上还是SPI获取的一个动态代理类:RegistryFactory$Adaptive,那么这里既然是处理zk相关的,这里获取的肯定就是org.apache.dubbo.registry.zookeeper.ZookeeperRegistryFactory,不过这个ZookeeperRegistryFactory集成自org.apache.dubbo.registry.support.AbstractRegistryFactory
registryFactory.getRegistry(registryUrl)其实是先到了:org.apache.dubbo.registry.support.AbstractRegistryFactory#getRegistry(org.apache.dubbo.common.URL)
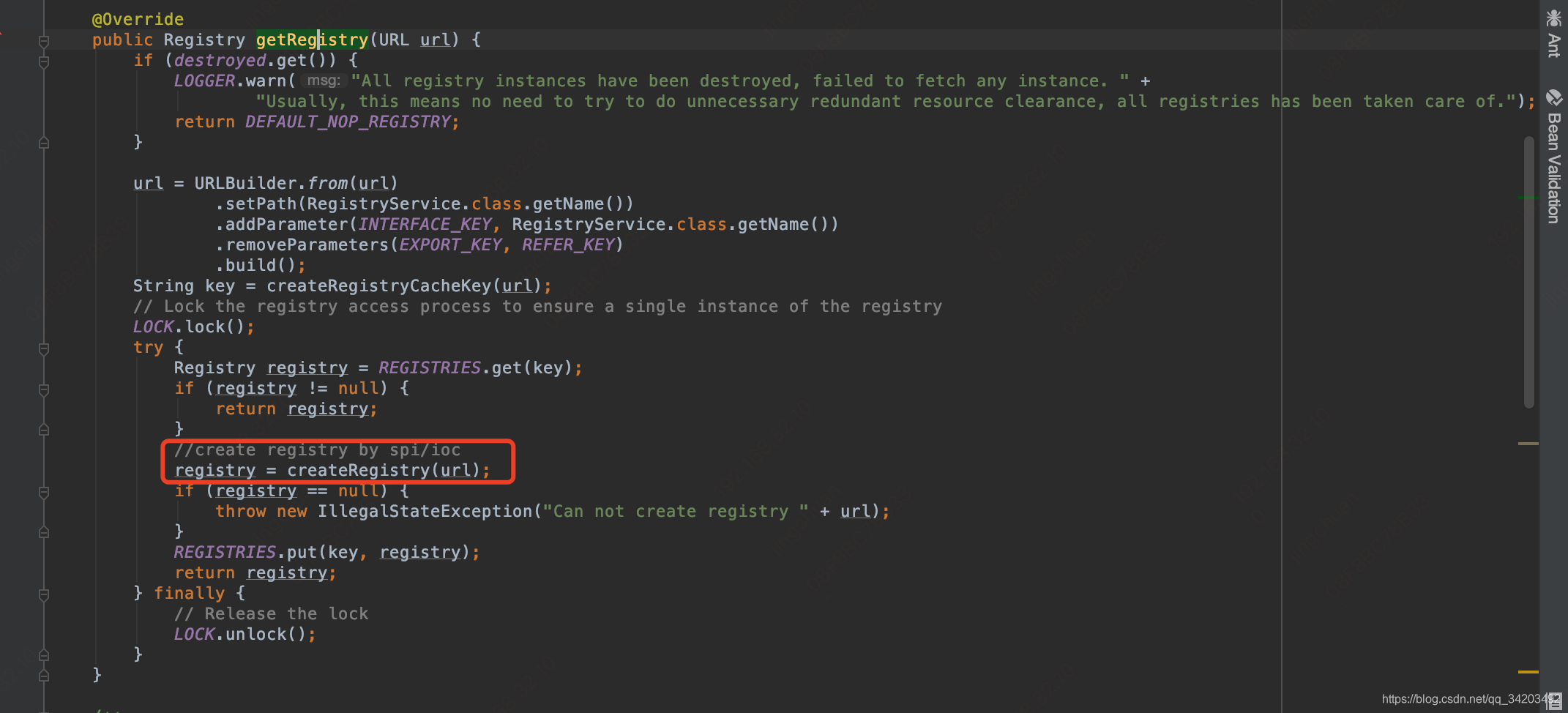
这个方法会在Lock里面获取一个注册中心Registry,如果没有就创建一个createRegistry(url),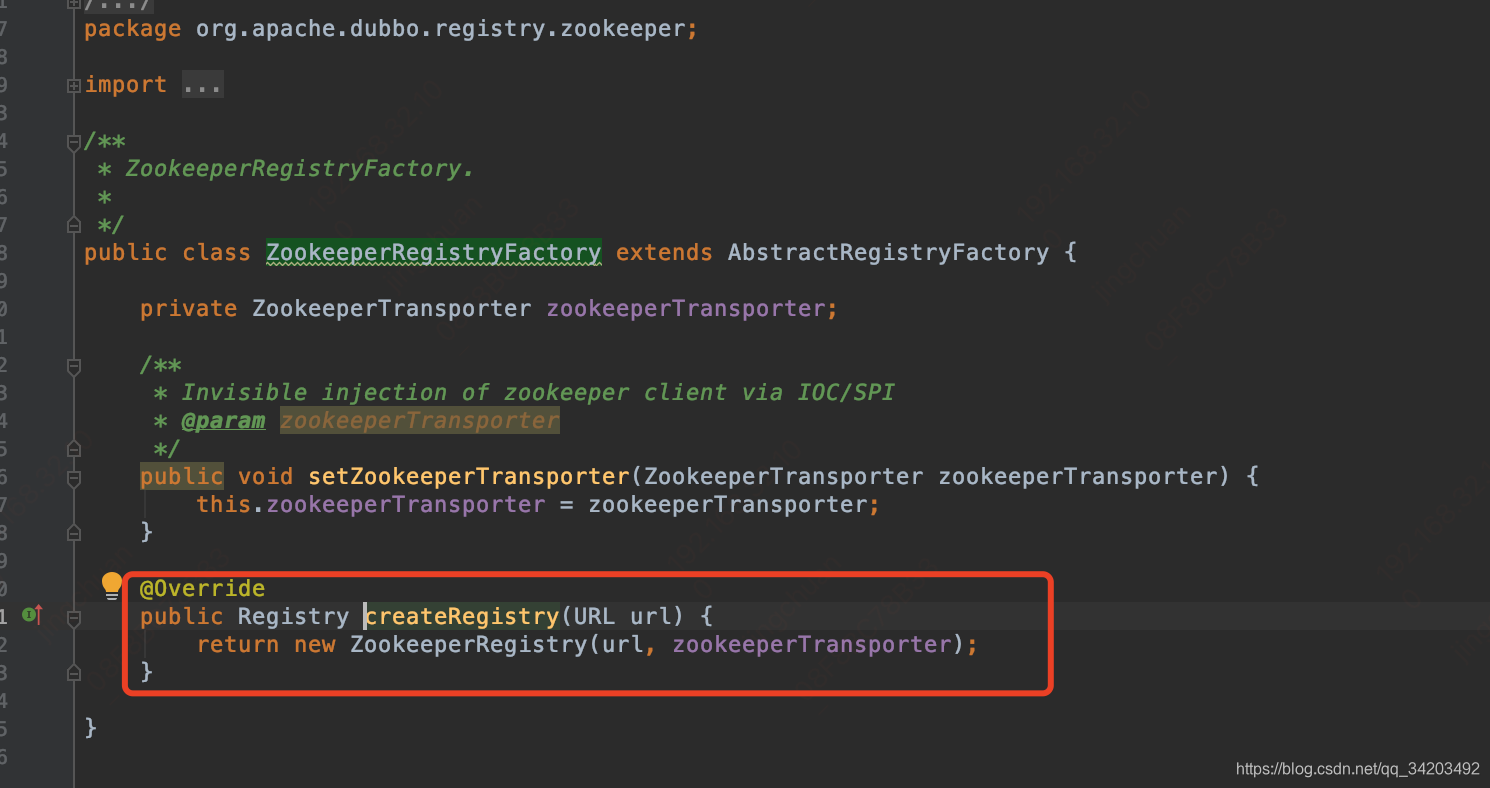
org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#ZookeeperRegistry
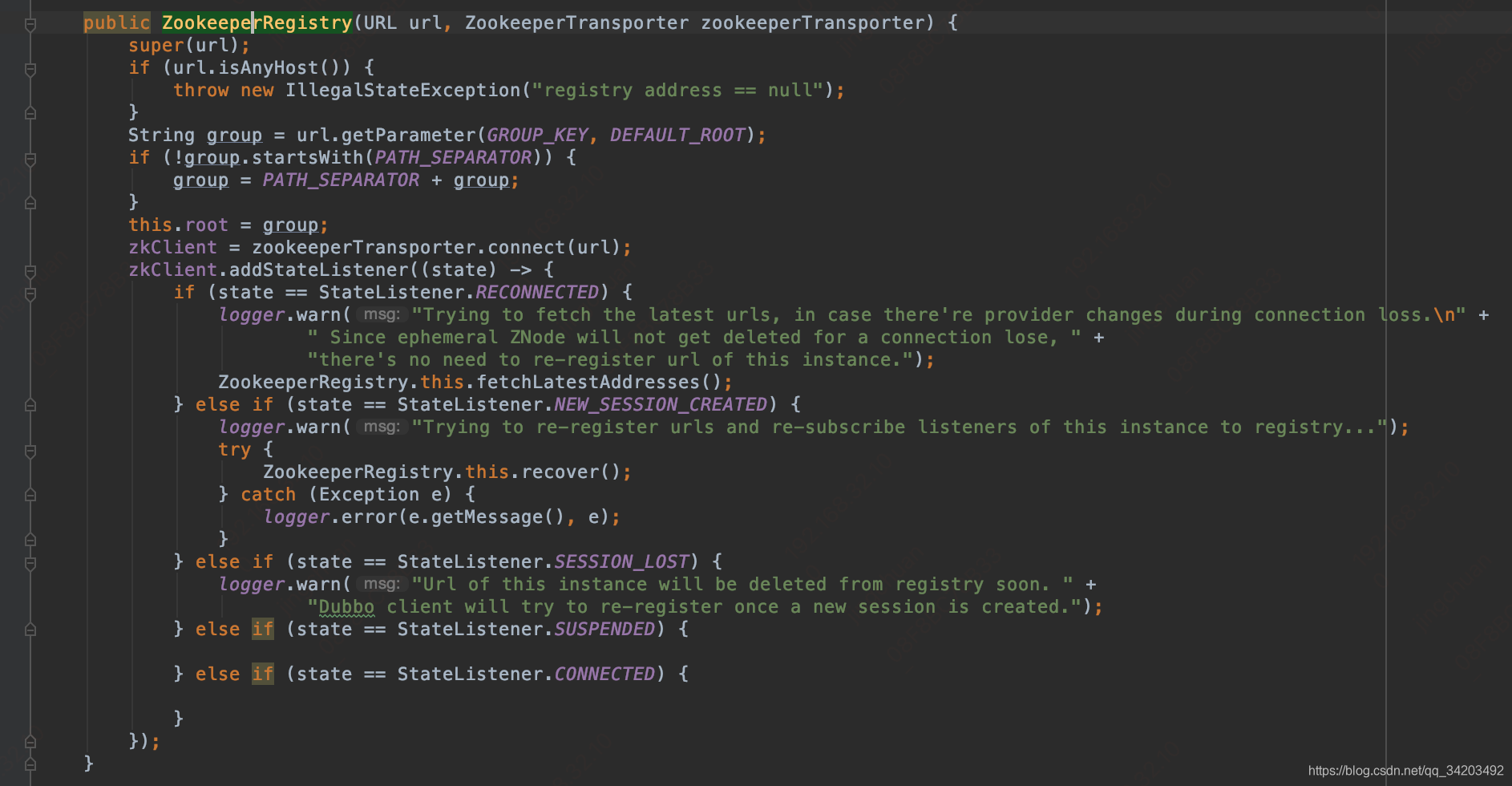
先从super(url)一步一步跟上去会看到这个代码
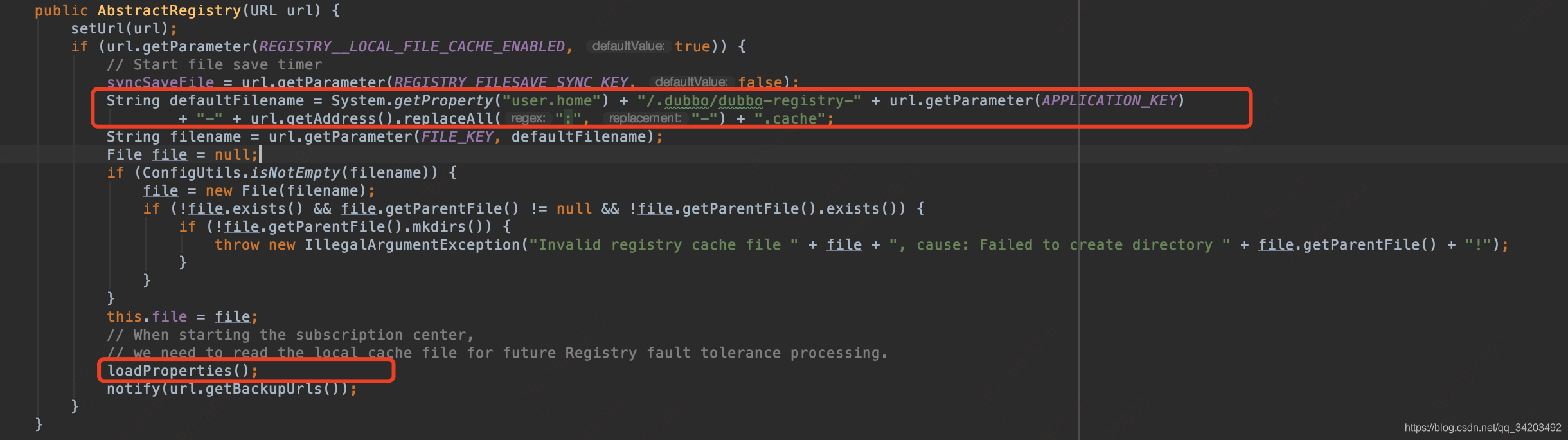
这里会生成一个.cache的文件在用户home目录下,然后在下面loadProperties()把这些文件中的内容加载到properties里面
然后回到org.apache.dubbo.registry.support.FailbackRegistry#FailbackRegistry
这里检测注册中心并重新连接如果失败了就重新连接
然后再回到:org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#ZookeeperRegistry
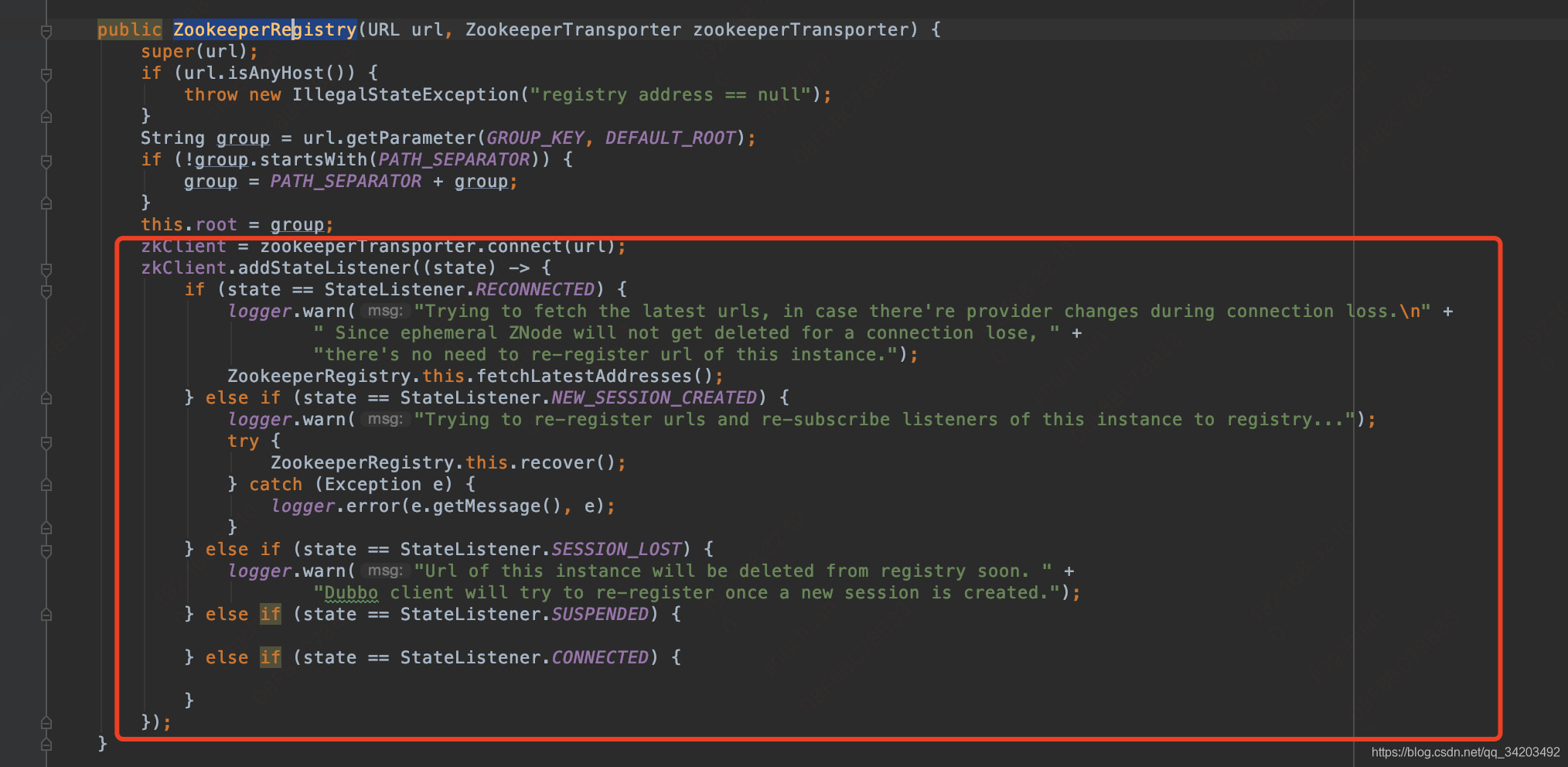
这里开始zookeeper连接了,这个zookeeperTransporter还是一个SPI获取的代理类:ZookeeperTransporter$Adaptive,然后就到了org.apache.dubbo.remoting.zookeeper.support.AbstractZookeeperTransporter#connect,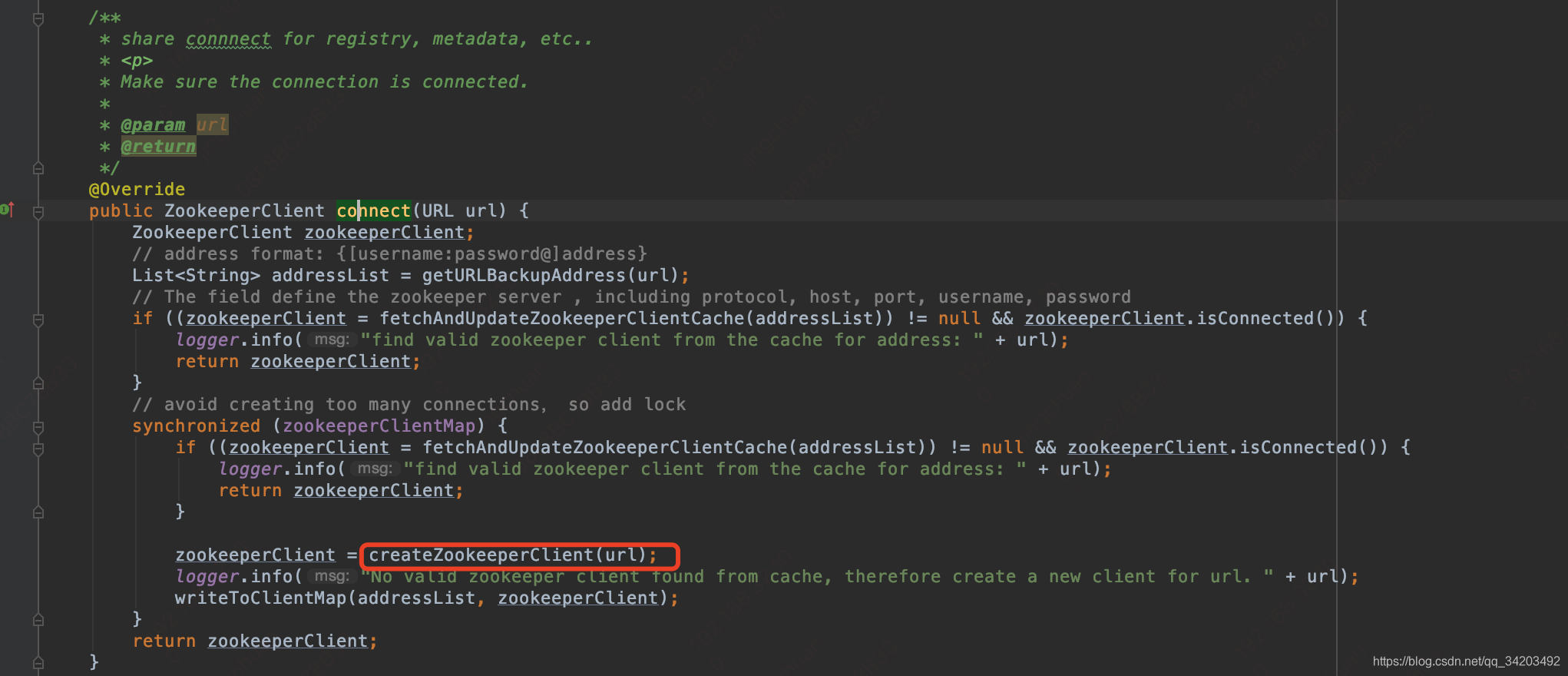
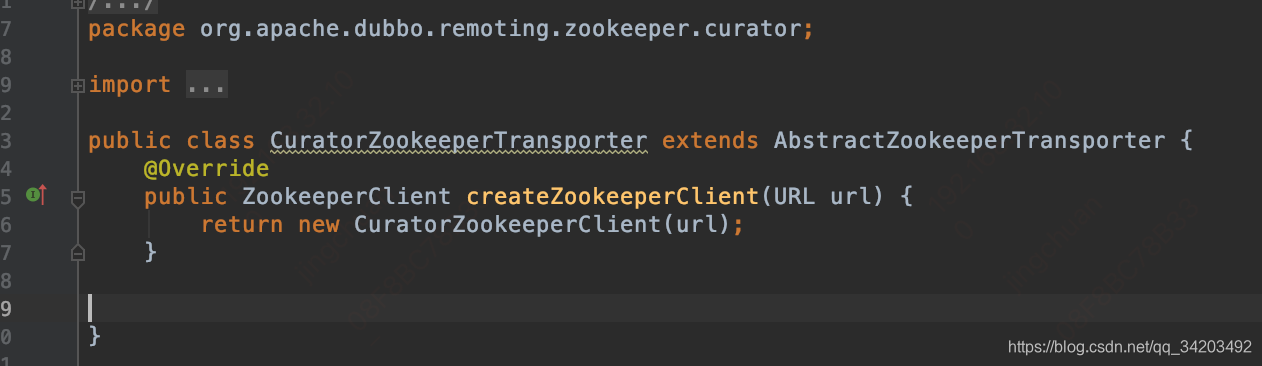
再到org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperTransporter#createZookeeperClient
继续跟进到org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient#CuratorZookeeperClient
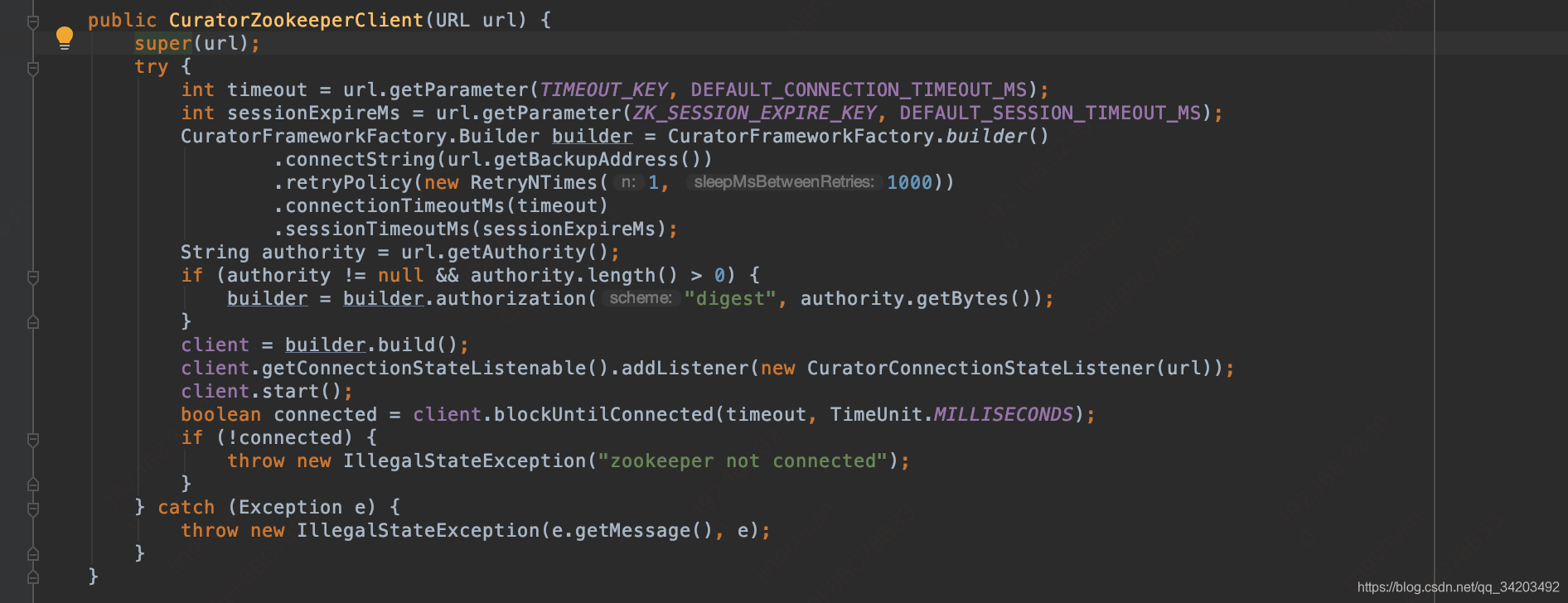
这里可以看到使用的是CuratorFrameworkFactory,老版本使用的ZkClient,其实都是连接zk,不了解的可以网上了解下zk的连接ZkClient和CuratorFrameworkFactory
//创建CuratorFramework 客户端实例,
//.connectString是集群服务器地址
//.retryPolicy(new RetryNTimes(1, 1000)) 回调策略是RetryNTimes
//.connectionTimeoutMs(timeout) 连接超时时间
//.sessionTimeoutMs 会话超时时间
CuratorFrameworkFactory.Builder builder = CuratorFrameworkFactory.builder()
.connectString(url.getBackupAddress())
.retryPolicy(new RetryNTimes(1, 1000))
.connectionTimeoutMs(timeout)
.sessionTimeoutMs(sessionExpireMs);
//....省略
//添加连接状态的监听
client.getConnectionStateListenable().addListener(new CuratorConnectionStateListener(url));
//开始连接
client.start();
在添加的状态监听里面org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient.CuratorConnectionStateListener#stateChanged
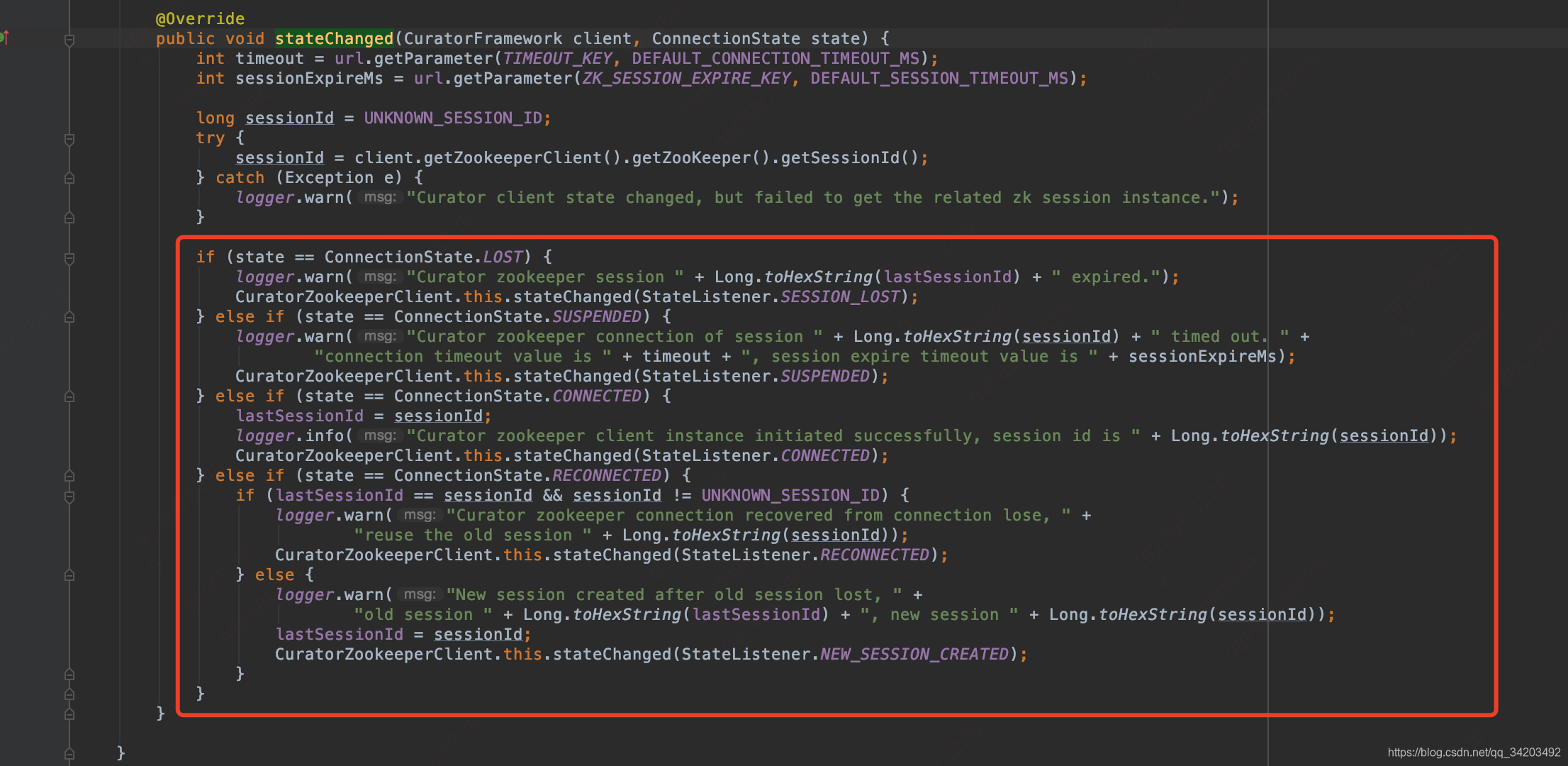
有对于连接状态的断开重连等恢复连接的操作
最后回到:org.apache.dubbo.remoting.zookeeper.support.AbstractZookeeperTransporter#connect
把创建的zk连接保存到Map中,然后创建连接基本就完成了
二. zk节点注册
回到org.apache.dubbo.registry.integration.RegistryProtocol#export中
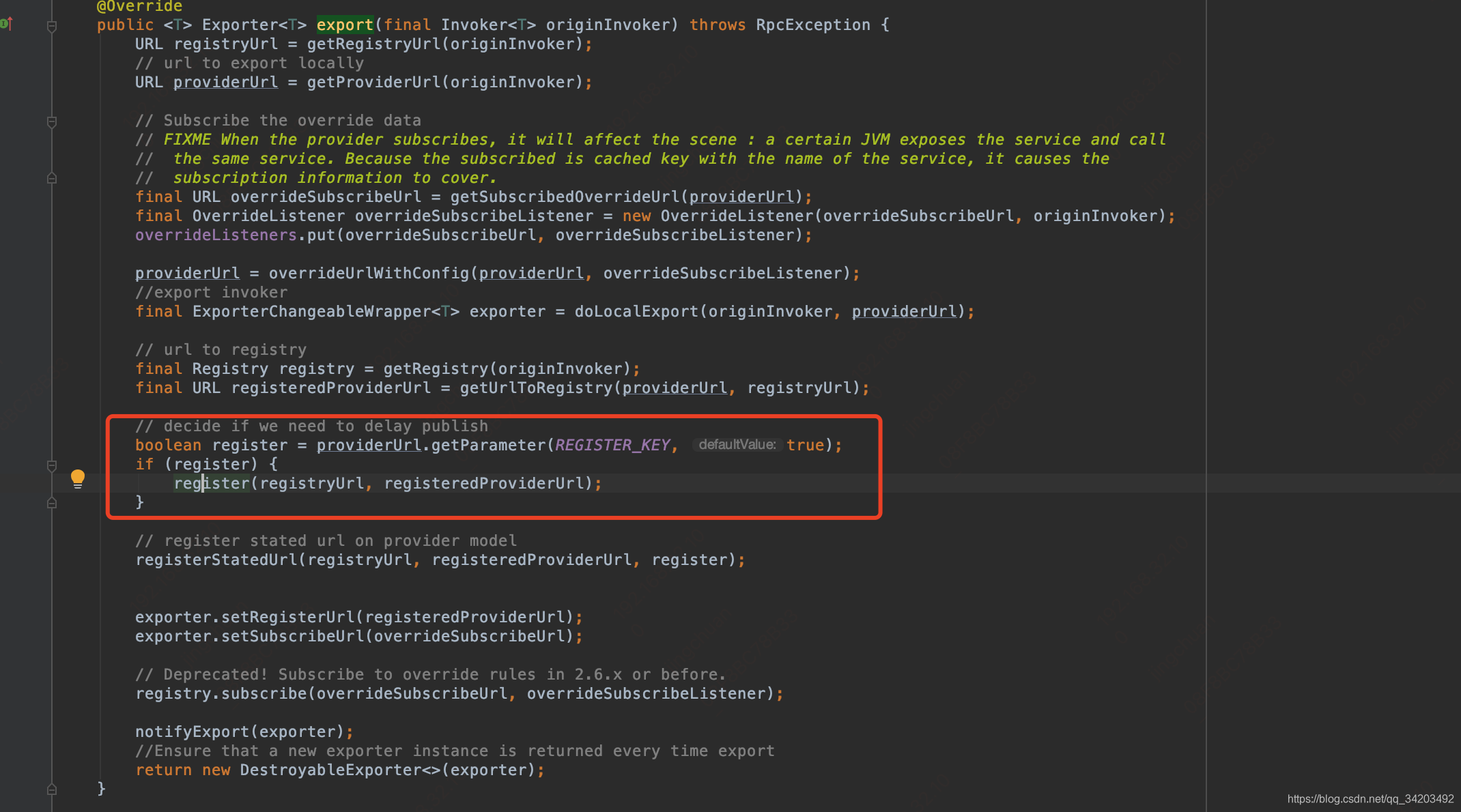
zk连接成功后,进入org.apache.dubbo.registry.integration.RegistryProtocol#register,最终会调用到:org.apache.dubbo.registry.support.FailbackRegistry#register
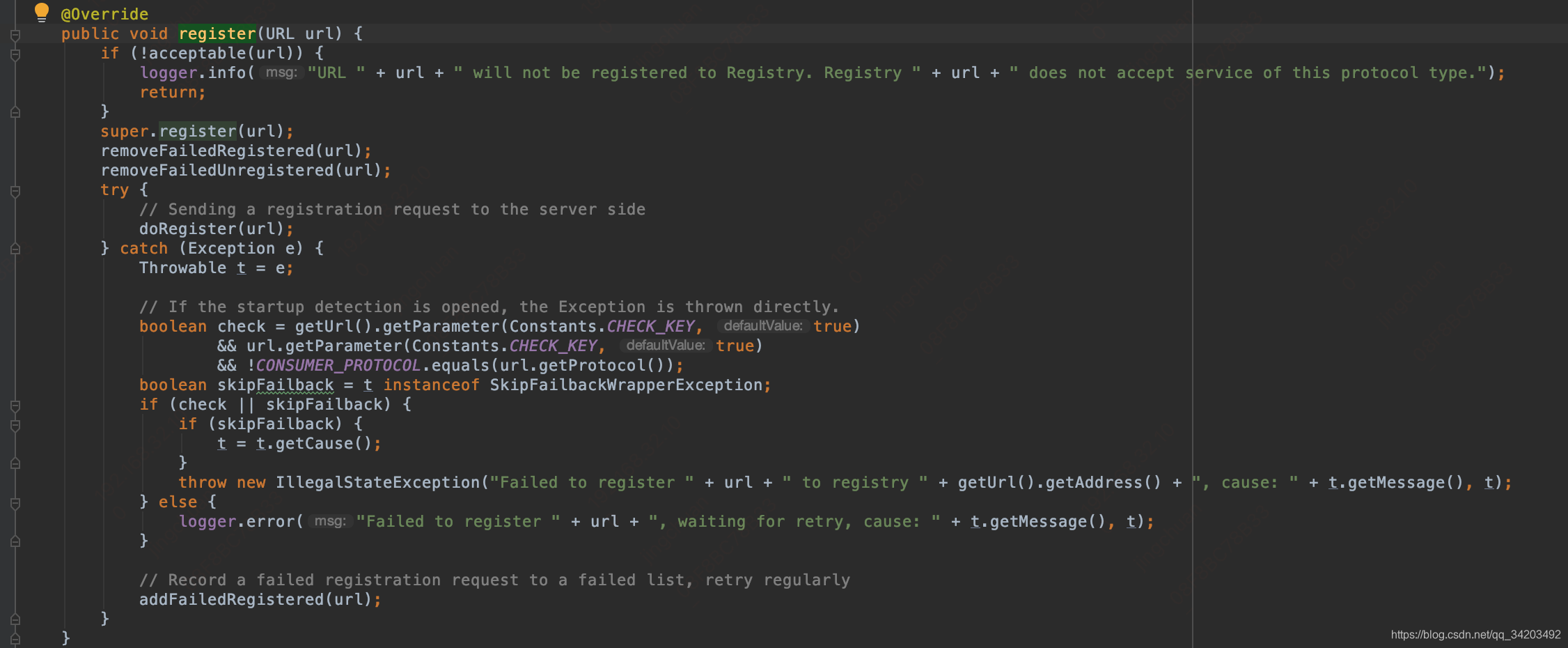
可以看到里面有个doRegister(url);这一步就是向zk发送注册请求
然后继续跟进到了org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#doRegister

再继续跟进到:org.apache.dubbo.remoting.zookeeper.support.AbstractZookeeperClient#create(java.lang.String, boolean)
注意上面zkClient.create的最后一个参数是在传入的的时候是true
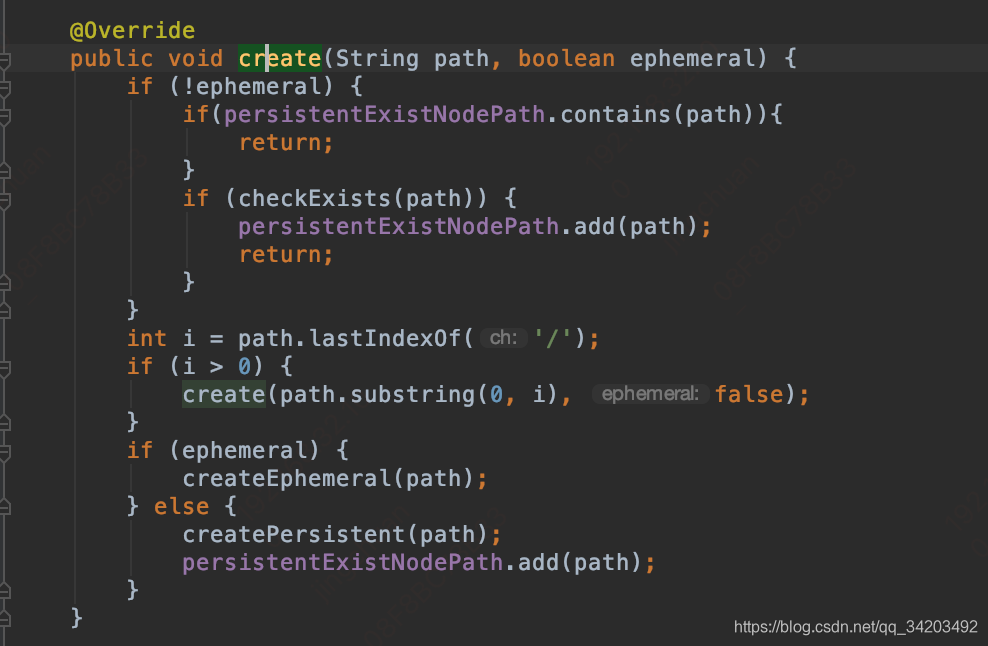
在这个方法里面,path的值是表示zk中要创建的节点,比如:
dubbo/com.alibaba.dubbo.demo.DemoService/providers/dubbo%3A%2F%2F192.168.100.52%3A20880%2Fcom.alibaba.dubbo.demo.DemoService%3Fanyhost%3Dtrue%26application%3Ddemo-provider%26dubbo%3D2.0.0%26generic%3Dfalse%26interface%3Dcom.alibaba.dubbo.demo.DemoService%26loadbalance%3Droundrobin%26methods%3DsayHello%26owner%3Dwilliam%26pid%3D2416%26side%3Dprovider%26timestamp%3D1474276306353
当这两个入参进入org.apache.dubbo.remoting.zookeeper.support.AbstractZookeeperClient#create(java.lang.String, boolean)方法时,他会被/分割成下面这样的,然后根据path.lastIndexOf('/')的值是不是再次进入方法,两个入参会不一样,这里有点类似递归,最终结果如下
- dubbo ➡️
createPersistent(path)创建持久化节点 - dubbo/com.alibaba.dubbo.demo.DemoService➡️
createPersistent(path)创建持久化节点 - dubbo/com.alibaba.dubbo.demo.DemoService/providers ➡️
createPersistent(path)创建持久化节点 - dubbo/com.alibaba.dubbo.demo.DemoService/providers/dubbo%3A%2F%2F192.168.100.52%3A20880%2Fcom.alibaba.dubbo.demo.DemoService%3Fanyhost%3Dtrue%26application%3Ddemo-provider%26dubbo%3D2.0.0%26generic%3Dfalse%26interface%3Dcom.alibaba.dubbo.demo.DemoService%26loadbalance%3Droundrobin%26methods%3DsayHello%26owner%3Dwilliam%26pid%3D2416%26side%3Dprovider%26timestamp%3D1474276306353 ➡️
createEphemeral(path)创建临时节点,当接口下线之后这个临时节点也就没了
也就是说总共创建了4个节点,3个持久化的,1个临时的,依次属于层级关系,并不是单独的
实际的创建方法如下
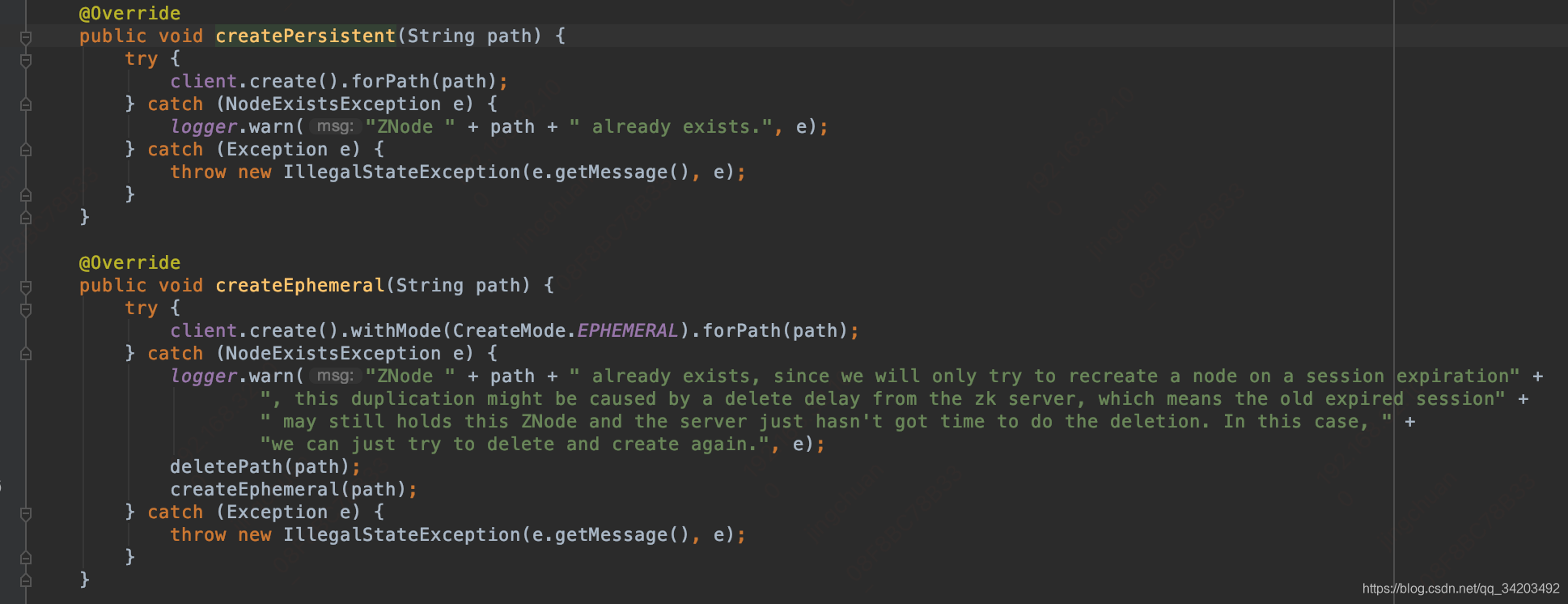
实际调用的是:org.apache.curator.framework.CuratorFramework#create,和上面连接zk一样使用的CuratorFramework
这里补一下zk的持久化节点和临时节点的概念:
- 持久节点:该数据节点被创建后,就会一直存在于zookeeper服务器上,直到有删除操作来主动删除这个节点
- 临时节点:临时节点的生命周期和客户端会话绑定在一起,客户端会话失效,则这个节点就会被自动清除
三. 订阅zookeeper
看完zk的节点创建
回到:org.apache.dubbo.registry.integration.RegistryProtocol#export里
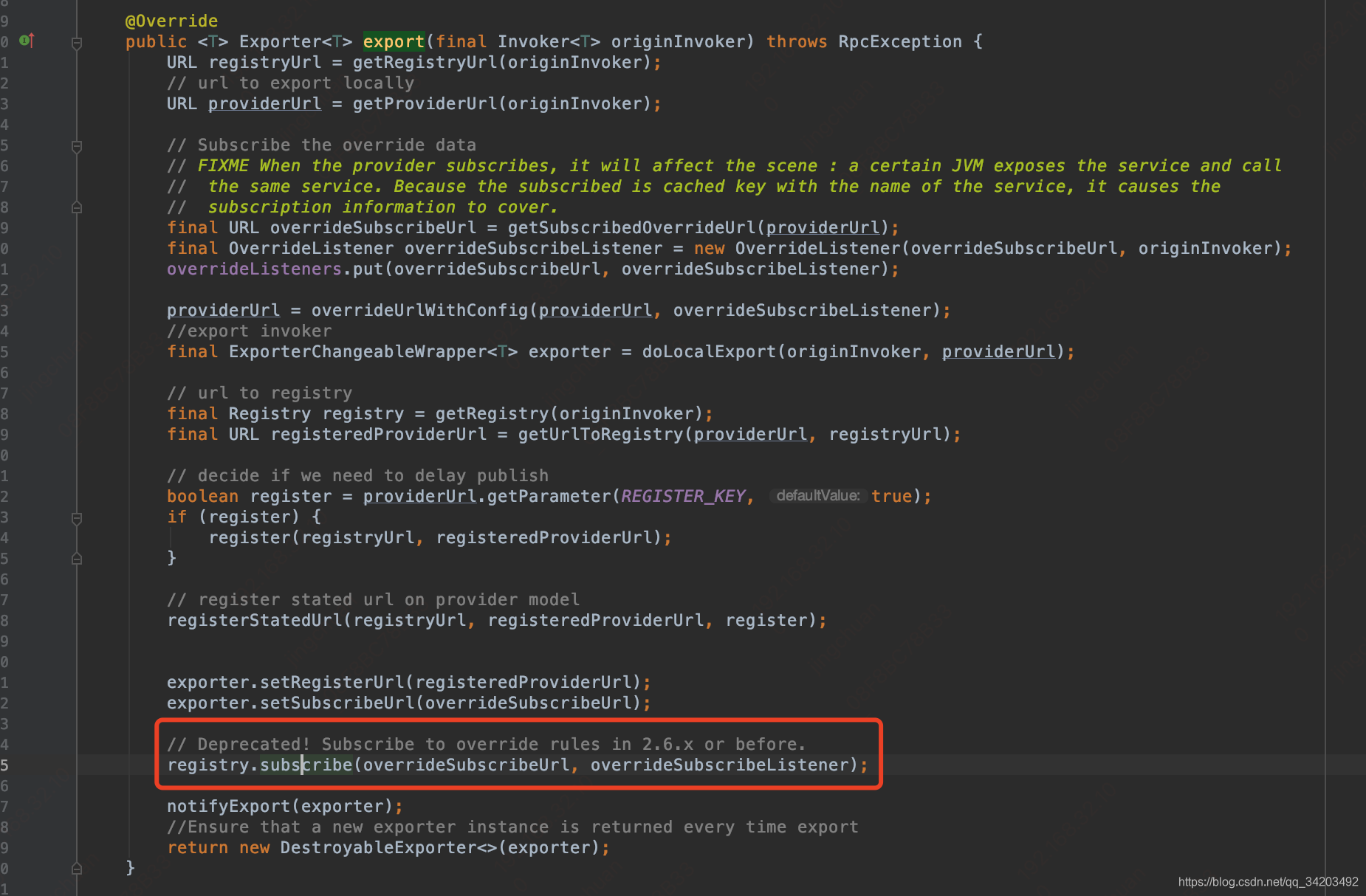
进入registry.subscribe(overrideSubscribeUrl, overrideSubscribeListener)走到了:org.apache.dubbo.registry.support.FailbackRegistry#subscribe
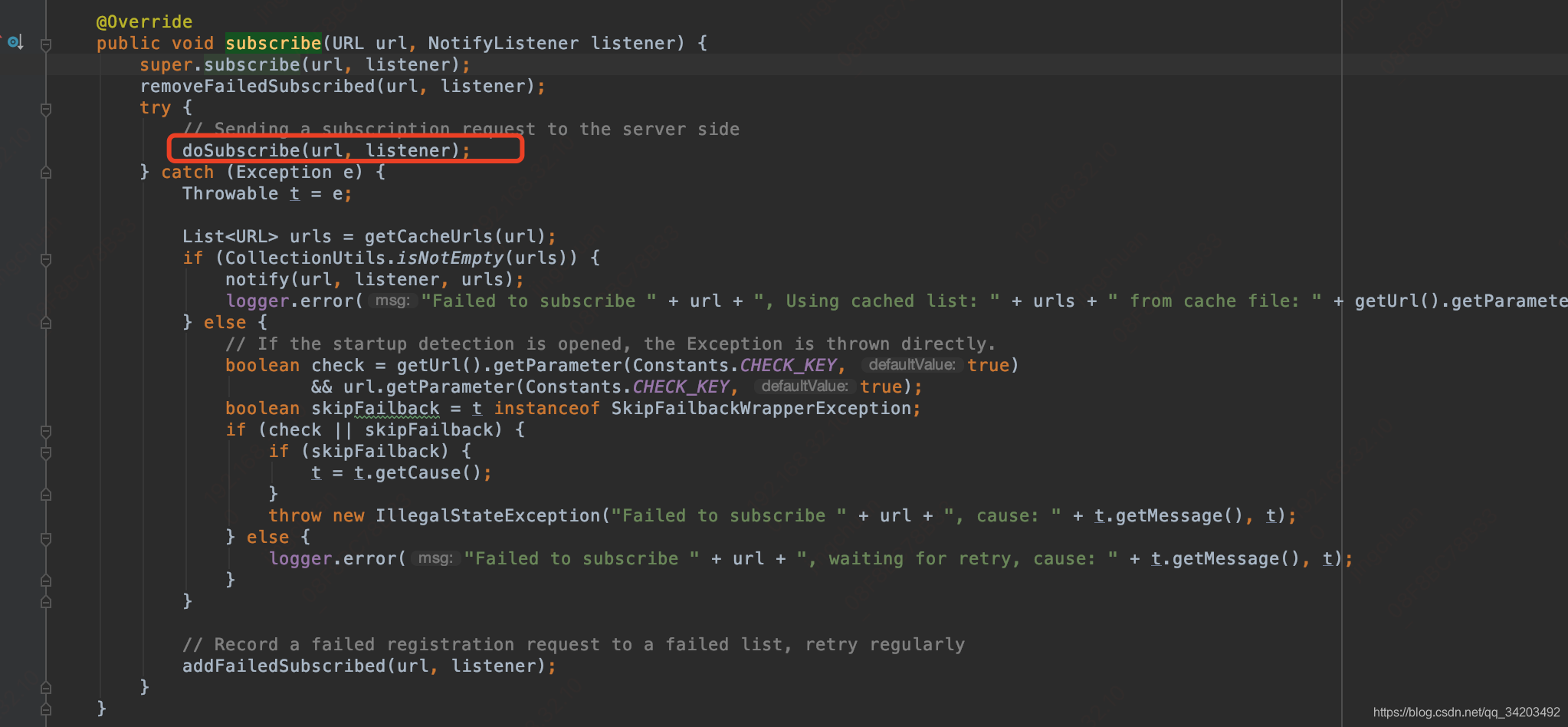
进入:doSubscribe(url, listener); 走到了:org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#doSubscribe
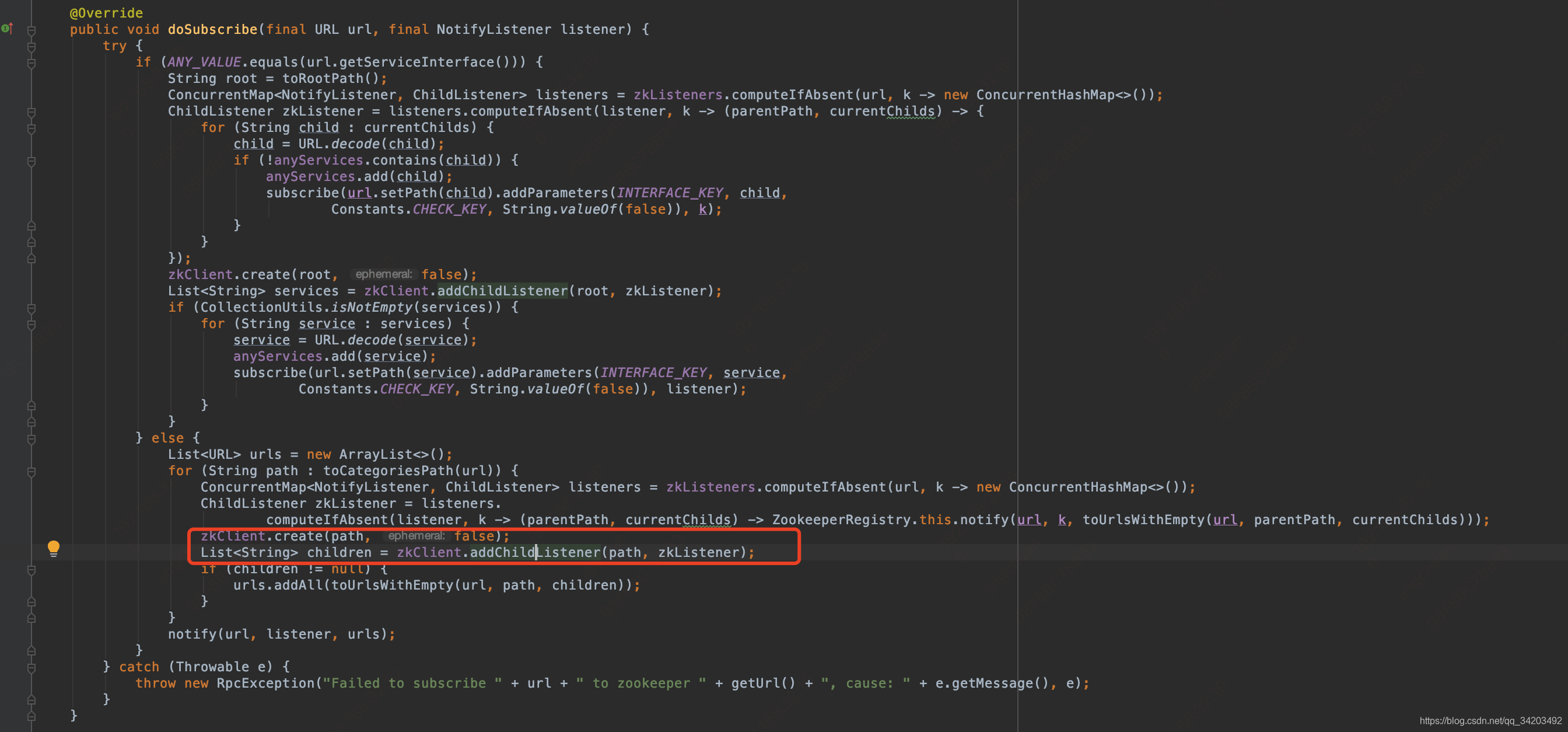
在这个方法里:zkClient.create(path, false);其中path是:/dubbo/com.alibaba.dubbo.demo.DemoService/configurators,和上面创建节点一样的逻辑,拿着这个path和false做入参,创建相应的持久化节点。
然后继续下一步:zkClient.addChildListener(path, zkListener),对节点进行监听:org.apache.dubbo.remoting.zookeeper.support.AbstractZookeeperClient#addChildListener

这里会创建一个监听,用于处理收到订阅消息后的逻辑处理:org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient#createTargetChildListener继续跟进到:org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient.CuratorWatcherImpl#CuratorWatcherImpl(org.apache.curator.framework.CuratorFramework, org.apache.dubbo.remoting.zookeeper.ChildListener, java.lang.String)
这个构造了一个监听的对象和方法:org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient.CuratorWatcherImpl#childEvent

创建的这个监听对于不同的变化做出不同的处理。然后创建好监听处理逻辑后,
监听的实际调用开始是在:org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClient#addTargetChildListener
这个方法里面的client就是CuratorFramework,和连接、创建节点一样的
到这里zk的订阅就完成了
所以zk的订阅总结步骤就是
- 创建持久化节点
- 创建监听收到订阅消息的处理逻辑
- 启动监听
在订阅处理完成后还有一步:org.apache.dubbo.registry.support.FailbackRegistry#notify
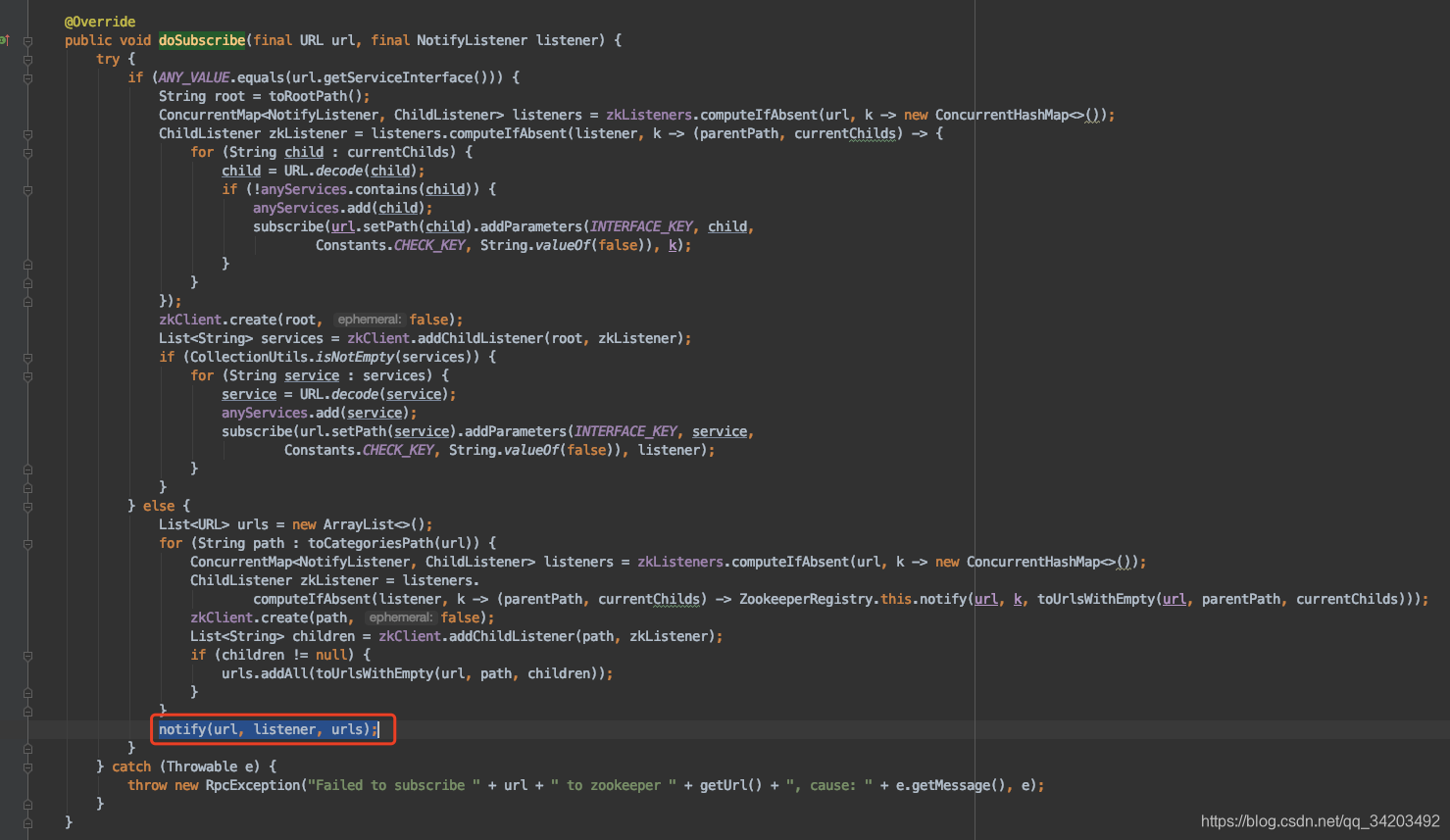
跟进代码:
org.apache.dubbo.registry.support.FailbackRegistry#notify➡️ org.apache.dubbo.registry.support.FailbackRegistry#doNotify➡️ org.apache.dubbo.registry.support.AbstractRegistry#notify(org.apache.dubbo.common.URL, org.apache.dubbo.registry.NotifyListener, java.util.List<org.apache.dubbo.common.URL>)
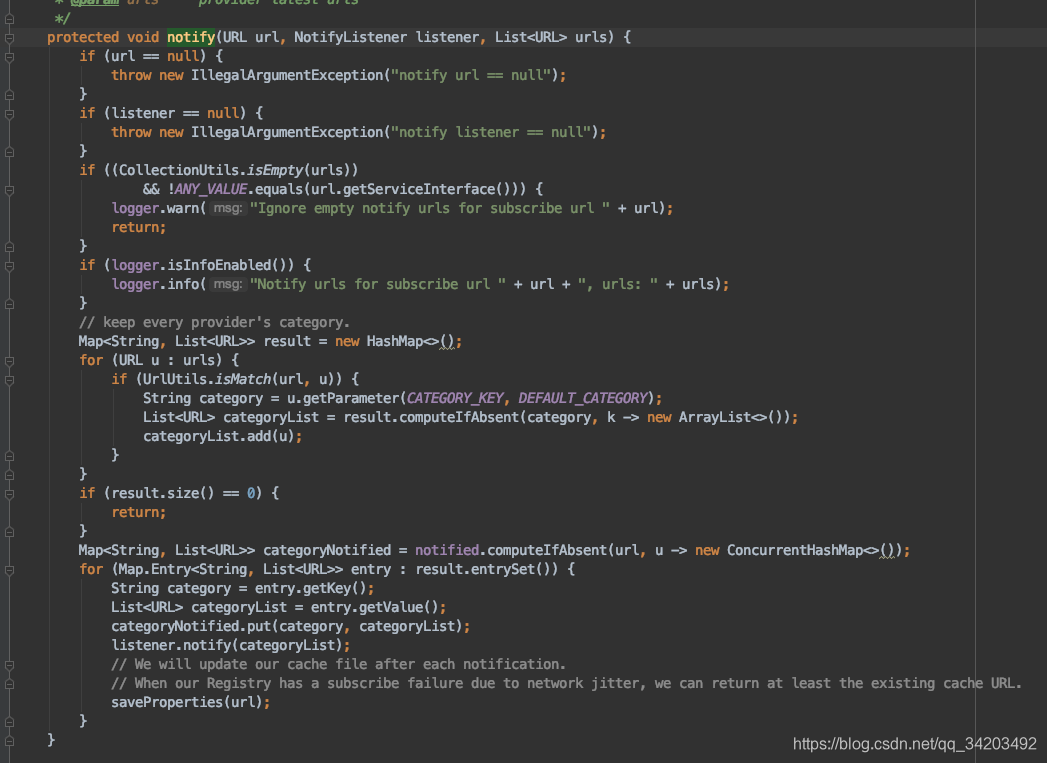
最终到了:org.apache.dubbo.registry.support.AbstractRegistry#saveProperties
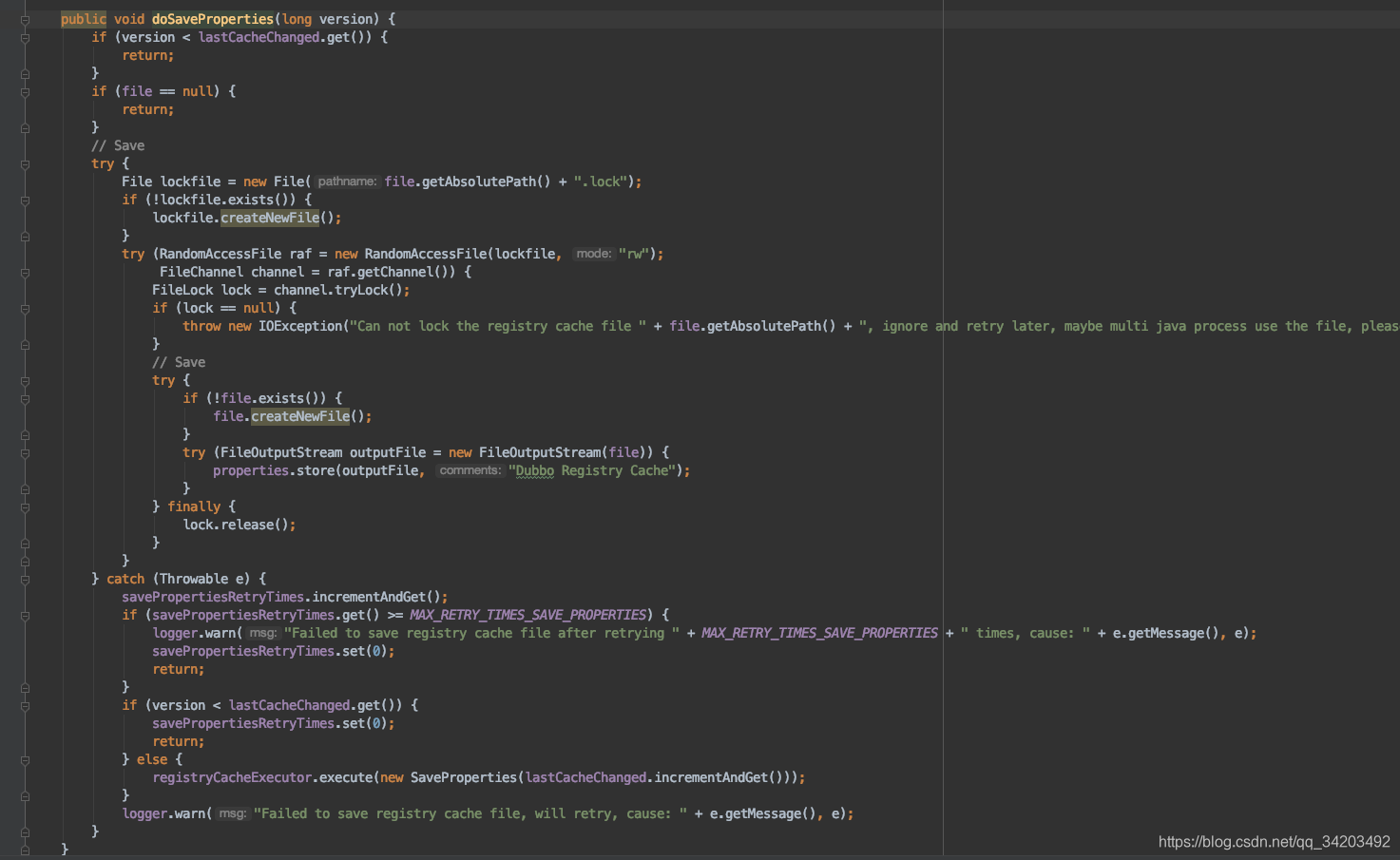
把服务端的注册url信息保存到一个用户目录/.dubbo/dubbo-registry-xxxx.cache文件中。这里保存到文件的原因上面注释也写了,是为了在异常情况下拿到要订阅的url。
然后订阅完成

















 6548
6548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









