







hadoop集群的搭建
安装Centos虚拟机
- 安装一台linux7的虚拟机,并设置静态ip地址
- 克隆该虚拟机,并修改静态ip和主机名
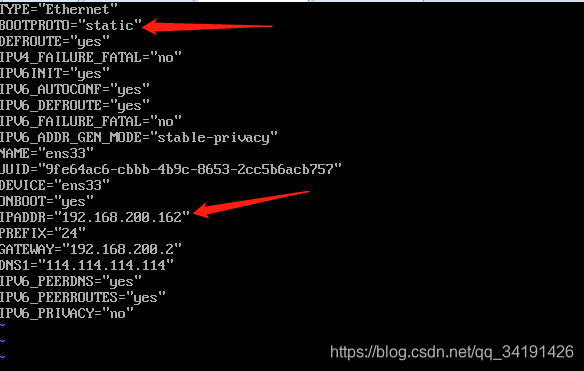
修改静态ip:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
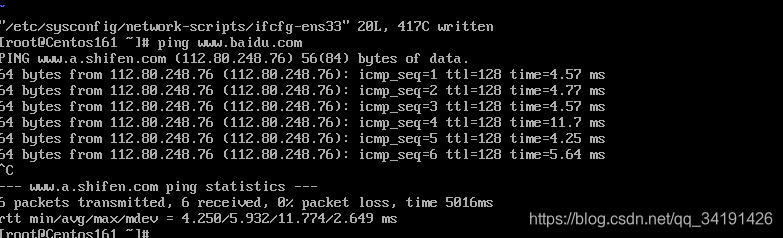
测试虚拟机能否联网:
修改主机名:
vi /etc/hostname
重启虚拟机 - 配置主机名与IP之间的映射关系
vi /etc/hosts

测试一下
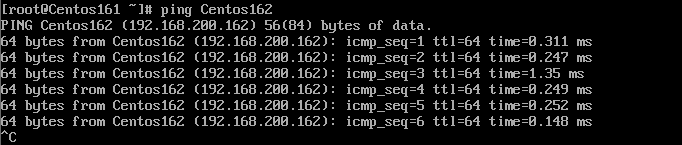
将hosts文件分发到其他虚拟机上
scp -r /etc/hosts root@Centos162:/etc/
scp -r /etc/hosts root@Centos163:/etc/

安装jdk
将安装好的jdk和配置好的环境变量分发到其他虚拟机上
scp -r /opt/software root@Centos162:/opt/
scp -r /opt/software root@Centos163:/opt/
scp -r /etc/profile root@Centos162:/etc/
scp -r /etc/profile root@Centos163:/etc/
重新加载centos162和Centos163的配置文件
source /etc/profile
测试一下另外两台虚拟机的jdk
安装hadoop集群
- 上传hadoop压缩包 /opt/software/hadoop
- 解压
tar -xvf hadoop-2.7.3.tar.gz - 删除hadoop压缩包,节省空间
rm -rf hadoop-2.7.3.tar.gz - 配置hadoop的配置文件
cd /opt/software/hadoop/hadoop-2.7.3/etc/hadoop

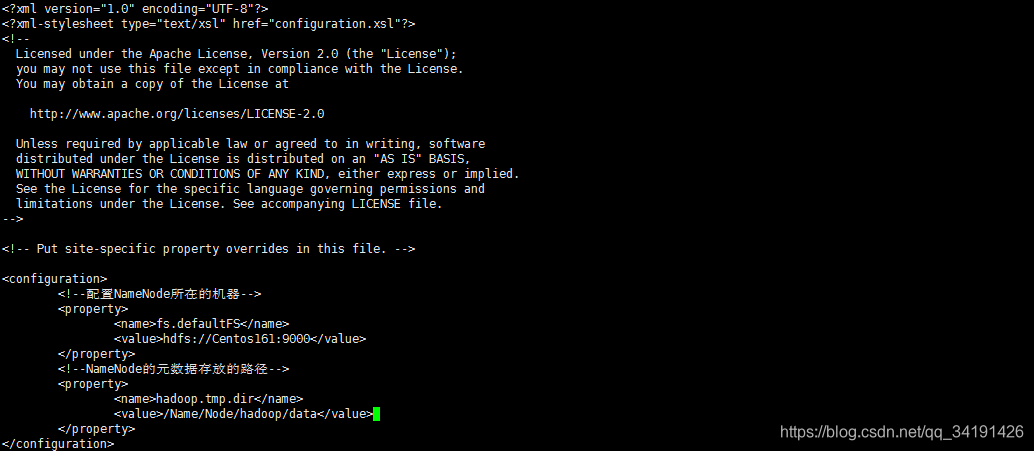
core-site.xml
<!--配置NameNode所在的机器-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Centos161:9000</value>
</property>
<!--NameNode的元数据存放的路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/Name/Node/hadoop/data</value>
</property>
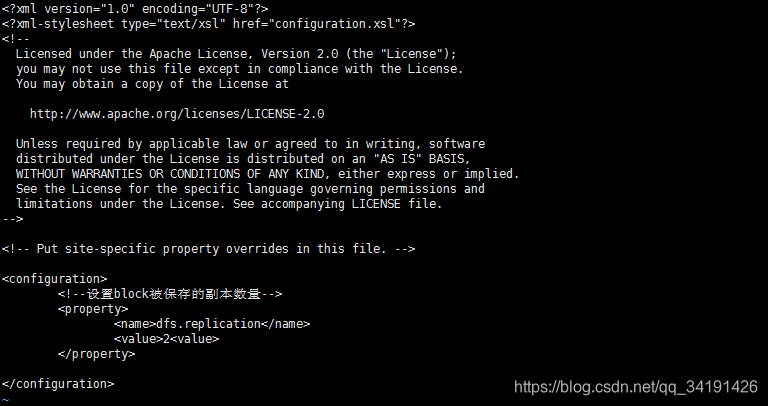
hdfs-site.xml
<!--设置block被保存的副本数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
mapred-site.xml.template
重命名mapred-site.xml.template为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<!--mapreduce程序运行由谁来分配资源-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
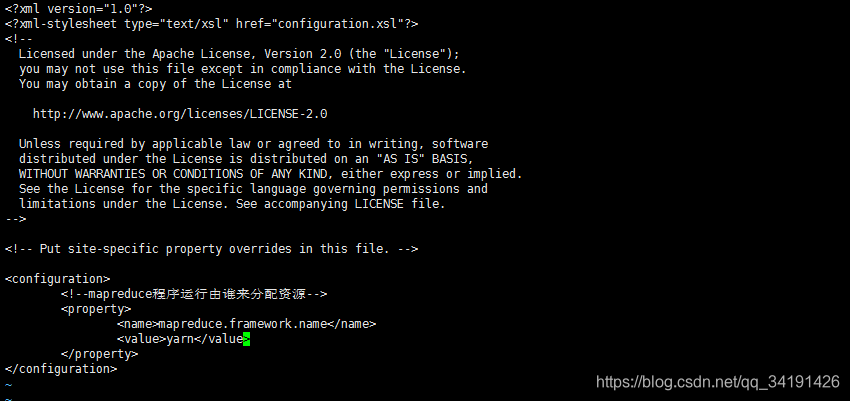
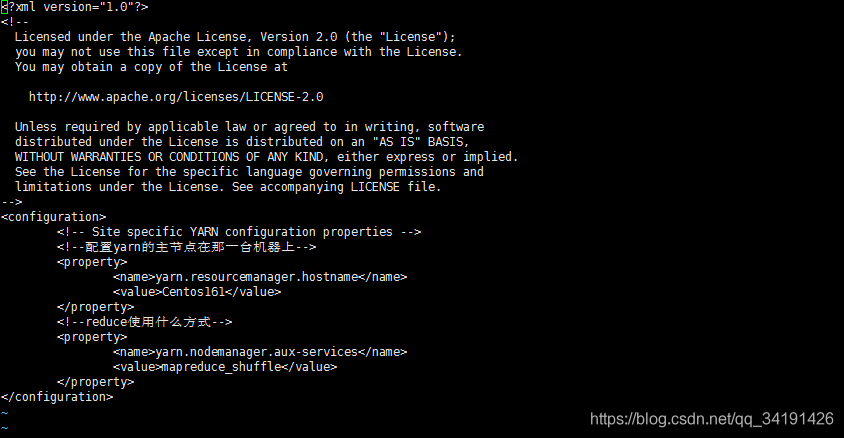
yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!--配置yarn的主节点在那一台机器上-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Centos161</value>
</property>
<!--reduce使用什么方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves
配置dataNode服务器

5. 配置hadoop的环境
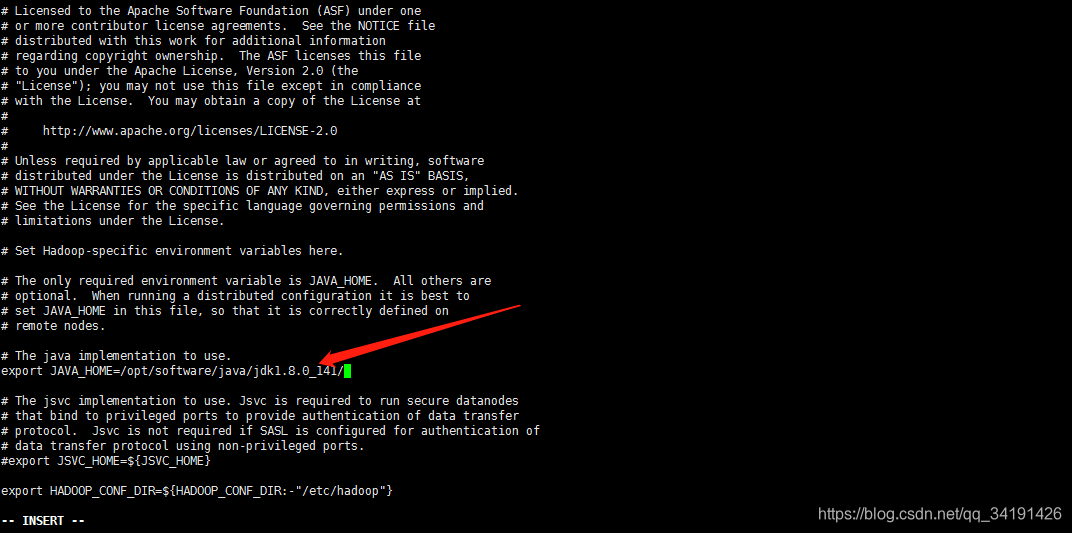
vi /opt/software/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
vi /etc/profile
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
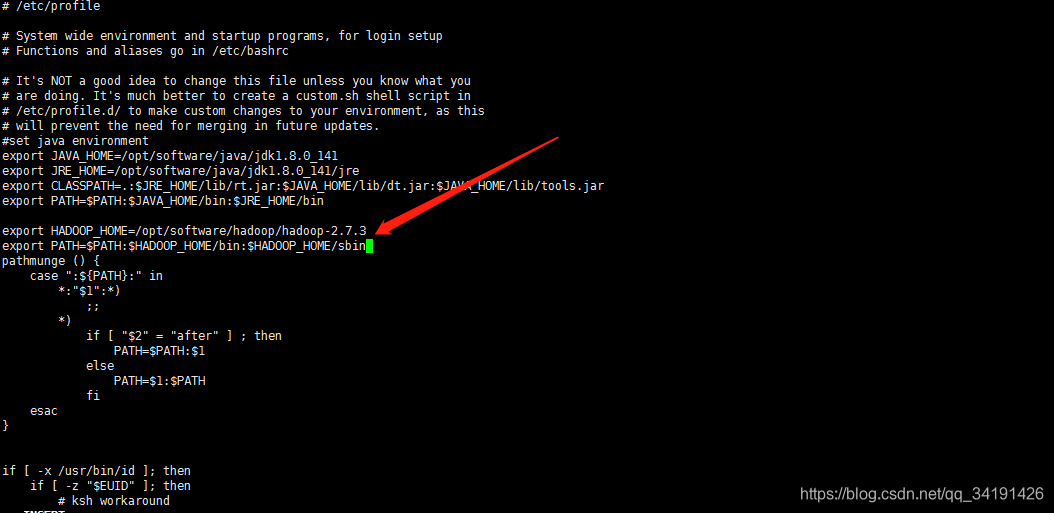
source /etc/profile
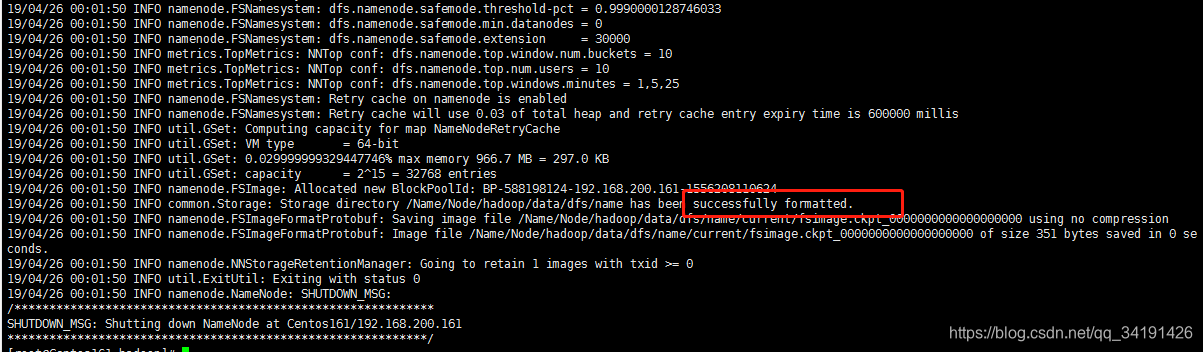
- 格式化nameNode
hadoop namenode -format
- 启动namenode
hadoop-daemon.sh start namenode
jps查看进程

- 开放50070端口
/sbin/iptables -I INPUT -p tcp --dport 50070 -j ACCEPT
-
浏览器访问
192.168.200.161:50070
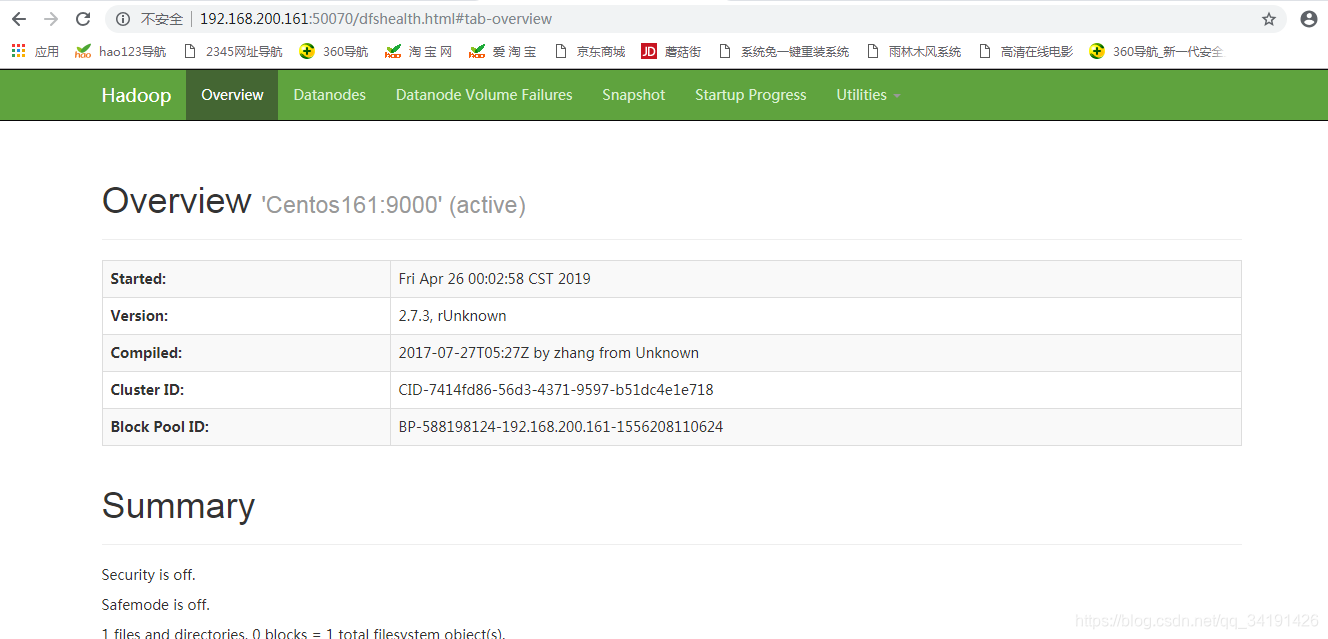
-
关闭namenode
hadoop-daemon.sh stop namenode

-
把hadoop的安装目录和环境配置分发到其他机器上
scp -r /opt/software/hadoop root@Centos162:/opt/software/
scp -r /opt/software/hadoop root@Centos163:/opt/software/
scp -r /etc/profile root@Centos162:/etc/
scp -r /etc/profile root@Centos163:/etc/ -
在其他机器上启动dataNode
hadoop-daemon.sh start datanode

-
查看日志内容
cat /opt/software/hadoop/hadoop-2.7.3/logs/hadoop-root-datanode-Centos162.log -
免密登录
在nameNode主机上设置免密登录
ssh-keygen
ssh-copy-id Centos161 需要登录那一台免密
ssh-copy-id Centos162
ssh-copy-id Centos163 -
启动主机nameNode
start-all.sh
从主节点看:

从其他节点看:
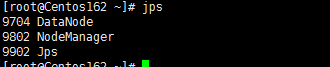
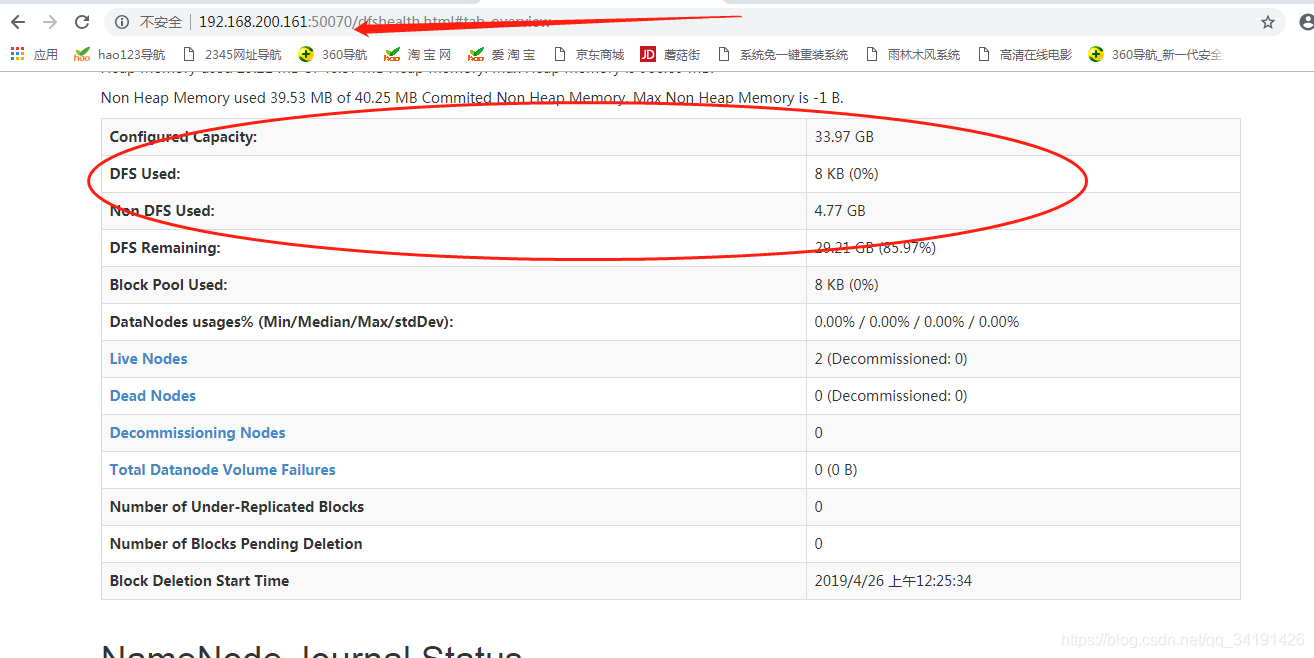
访问192.168.200.161:50070

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









