







val lines = sc.textFile(“hdfs://xxxx.txt”)
lines.count(统计RDD中的元素个数)Driver Program:
从spark上层来看:
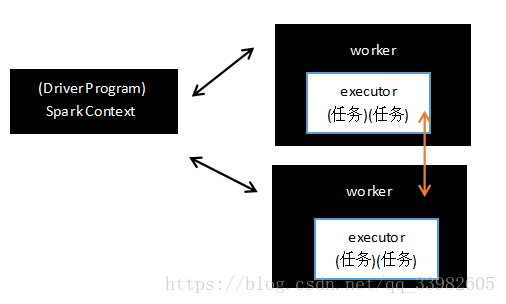
每一个spark应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作.
我们在类中所写的main方法就属于驱动器程序,driver program通过一个SparkContext来访问Spark,这个对象代表对计算集群的一个链接。
如果你使用spark Shell来写代码的话,那么driver program就是spark Shell本身,且Spark Shell启动时自动创建了SparkContext对象
Executor:
如果要执行spark算子等操作,那么driver program会自动将操作发送到各个执行器(->executor)节点(->worker)上。
那么不同的节点会分工进行计算,然后将数据返回给driver program


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









