







 本文详细介绍了如何利用selenium爬取京东网站的商品信息,包括界面分析、主页面查询、商品页面数据获取、翻页技巧以及在使用chromedriver过程中遇到的问题和解决方案,如翻页元素未找到、不可点击错误等。
本文详细介绍了如何利用selenium爬取京东网站的商品信息,包括界面分析、主页面查询、商品页面数据获取、翻页技巧以及在使用chromedriver过程中遇到的问题和解决方案,如翻页元素未找到、不可点击错误等。
目录
6-3-2 转跳页面错误 - 模拟点击转跳,却刷新数据的错误
一、界面分析
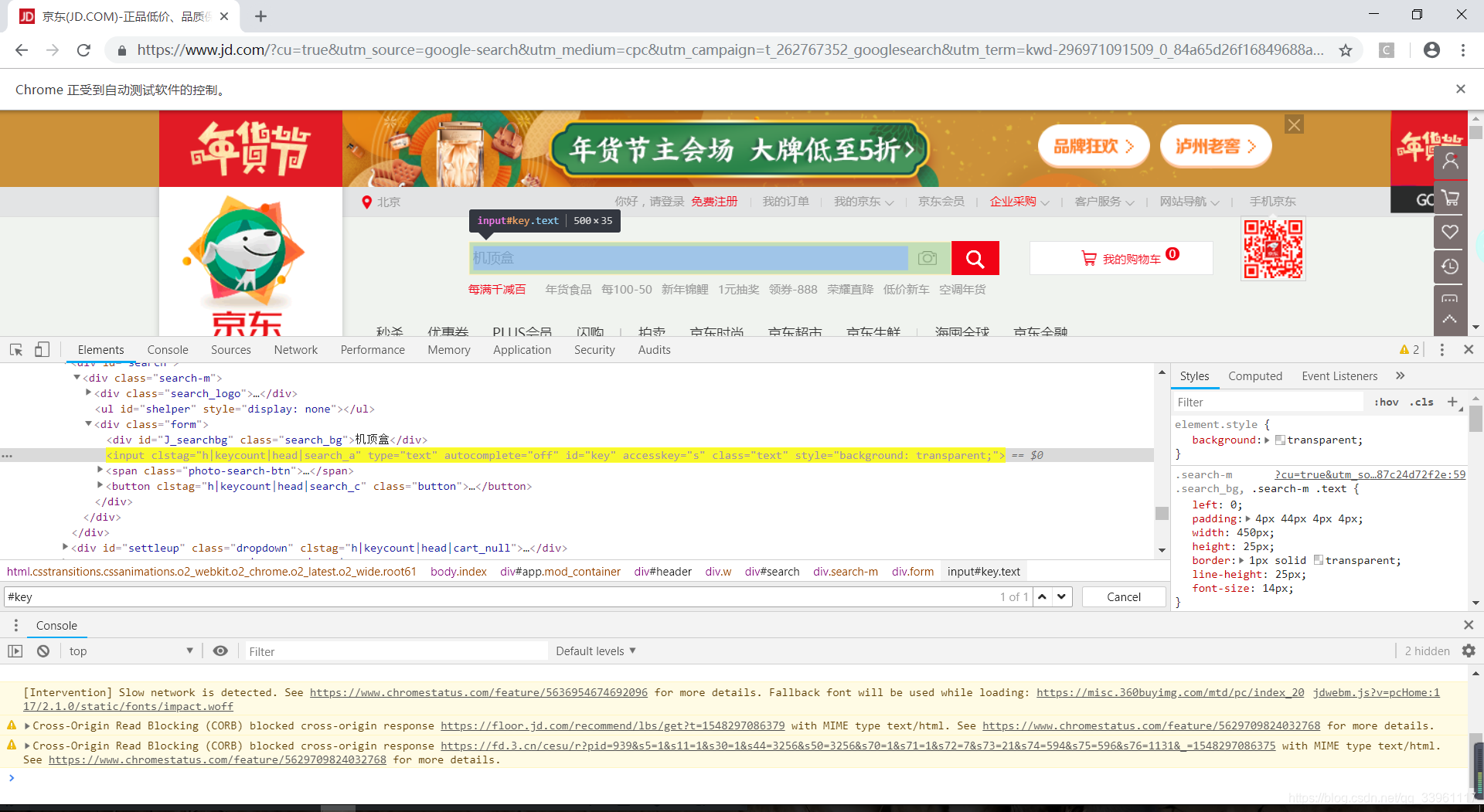
主页面有且只有一个id为key的输入框
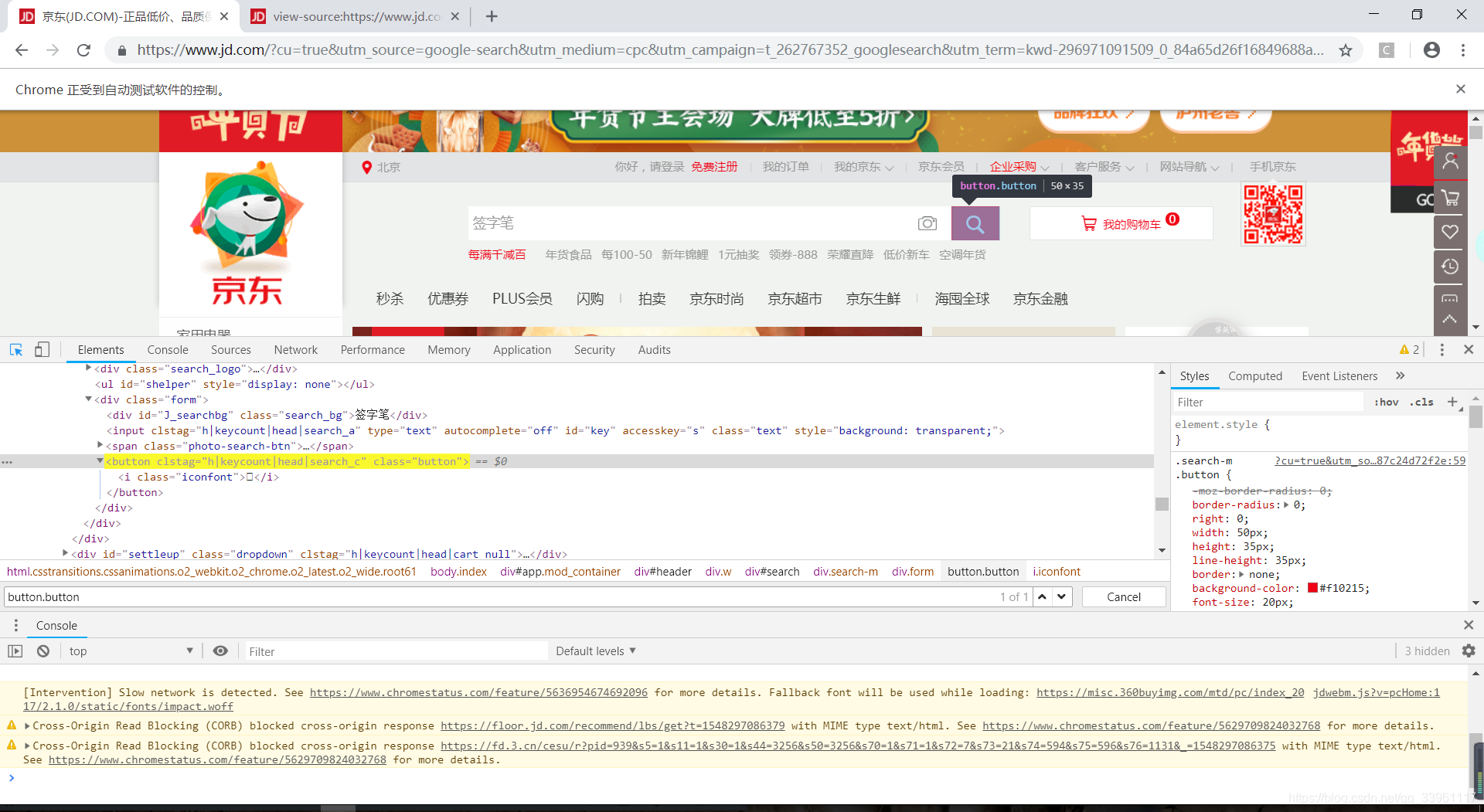
主页面有且只有一个button标签内class为button 的按钮
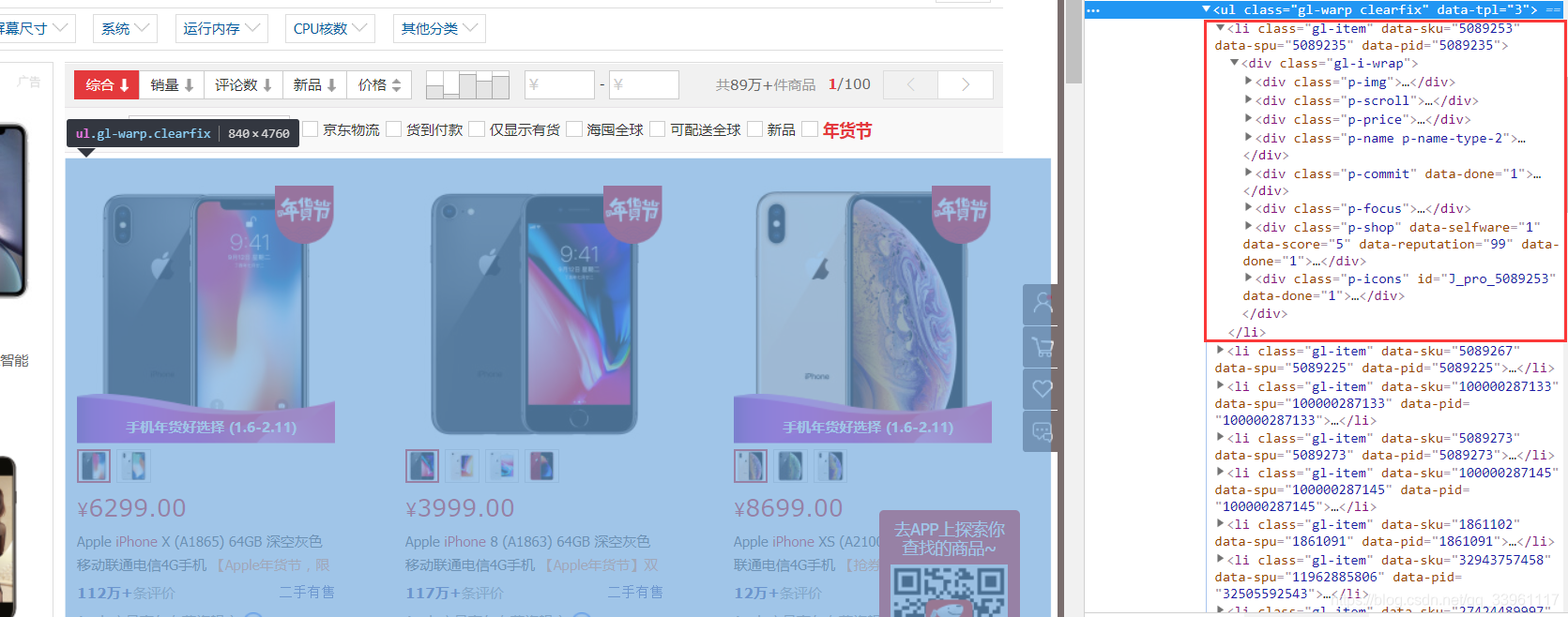
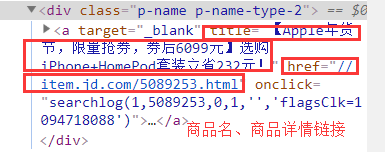
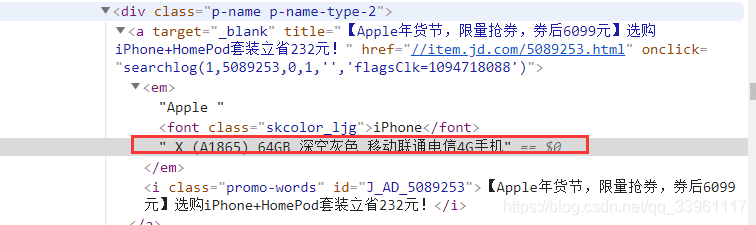
商品浏览页结构
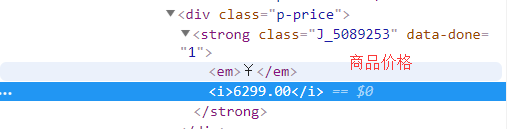
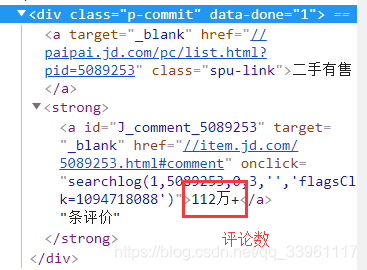
需求信息:商品名称、商品详情链接、商品价格、商品评论数量
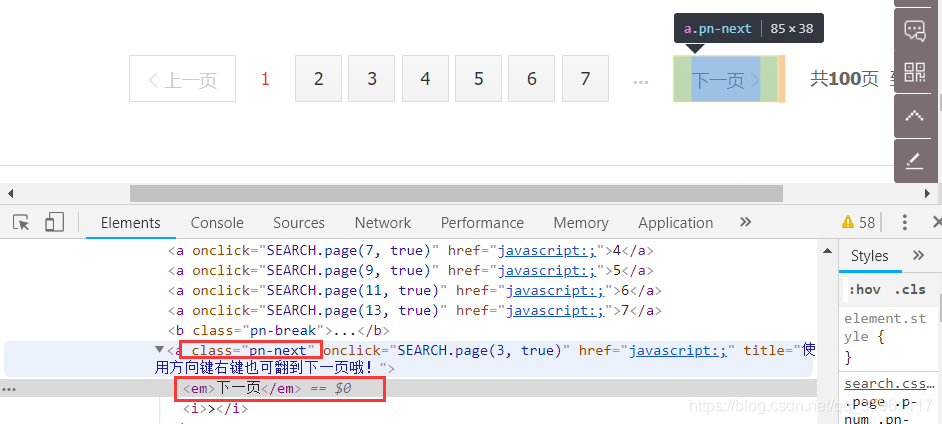
商品页面有且只有一个class固定为fp-next的下一页
上下俩个唯一class的按钮都可以进行翻页操作,任选一个进行模拟点击
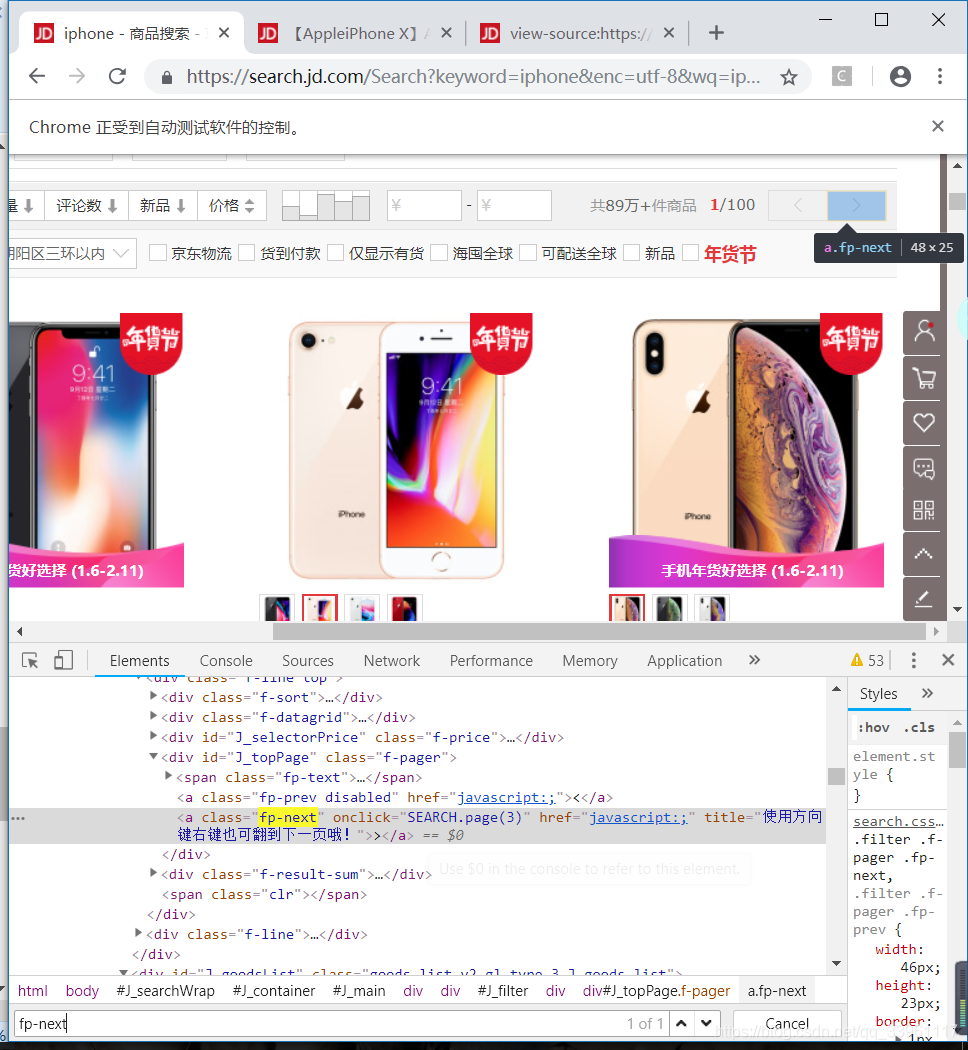
二、主页面查询,数据跳转商品页面
from selenium import webdriver from selenium.webdriver.common.keys import Keys #键盘按键操作 # 主页面信息查询跳转商品页面 url = 'https://www.jd.com/' keyword = 'iphone' driver = webdriver.Chrome() driver.get(url) driver.implicitly_wait(3) # 隐式等待,模拟浏览 try: input_info = driver.find_element_by_id('key') input_info.send_keys(keyword) input_info.send_keys(Keys.ENTER) finally: pass # driver.close()
三、商品页面获取商品信息
# 获取所有单个商品信息列表 goods = driver.find_eleme
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2983
2983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









