






线程递增的策略
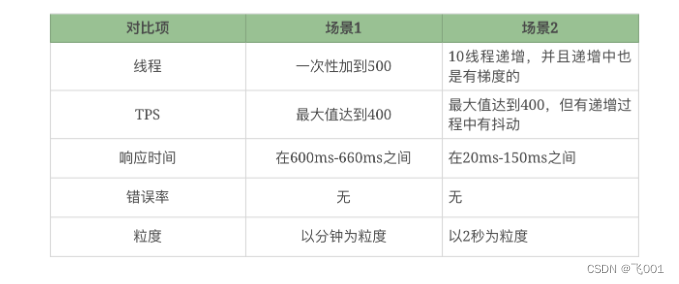
TPS 都是达到 400,但两个场景中线程递增的策略不同,产生的响应时间完全不同。虽然都没有报错,但是第一种场景是完全不符合真实的业务场景的,他们的区别如下
-
线程应该是递增的,而场景 1 直接一次性到500线程
-
在场景的执行过程中,响应时间应该是从低到高的,而在场景 1 中不是这样
-
在两个场景的TPS 的上限都达到了 400TPS。但是在场景 2 中,只要 40 个线程即可达到,但场景 1 中居然用到了 500 线程
-
显然场景2比场景1压力大很多,所以响应时间才那么长
仅在改变压力策略(其他的条件比如环境、数据、软硬件配置等都不变)的情况下,系统的最大 TPS 上限是固定的
场景 2 使用了递增的策略,在每个阶梯递增的过程中,出现了抖动,这就明显是系统设置的不合理导致的。设置不合理有两种可能性:
-
资源的动态分配不合理,像后端线程池、内存、缓存等等
-
数据没有预热
秒杀场景设计
说到秒杀场景,有人觉得用大线程并发是合理的,其实这属于认识上的错误,因为即使线程数增加得再多,对已经达到 TPS 上限的系统来说,除了会增加响应时间之外,并无其他作用。
所以描述系统的容量是用系统当前能处理的业务量( TPS),而不是压力工具中的线程数。我们前期一定是做好了系统预热的工作的,在预热之后,线程突增产生的压力,也是在可处理范围的。这时,我们可以设计线程突增的场景来看系统瞬间的处理能力。如果不能模拟出秒杀的陡增,就是不合理的场景。
线程递增策略
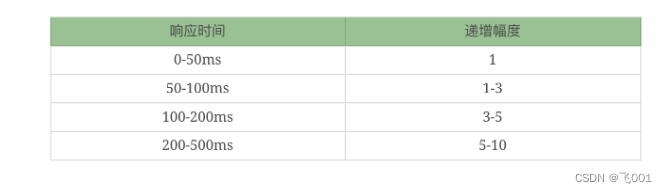
这里给出我做性能场景递增的经验值,当然这里也不会是放在哪个系统中都适合的递增幅度,你还是要根据实际的测试过程来做相应的判断。有了这些判断之后,相信大家都能做出合理的场景来了
-
场景中的线程递增一定是连续的,并且在递增的过程中也是有梯度的
-
场景中的线程递增一定要和 TPS 的递增有比例关系,而不是突然达到最上限
瓶颈的精准判断
对性能瓶颈做出判断是性能分析的第一步,有了问题才能分析调优
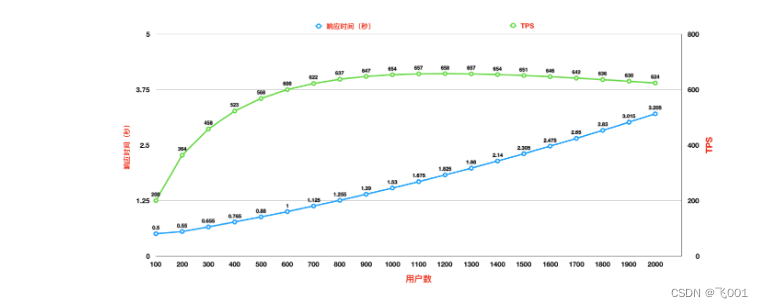
看图可知:
-
随着用户数的增加,响应时间也在缓慢增加。TPS 前期一直都有增加,但是增加的幅度在变缓,直到变平
-
瓶颈在第二个压力阶梯上已经出现了。因为响应时间增加了,TPS 增加得却没有那么多
-
到第三个阶梯时,显然增加的 TPS 更少了,响应时间也在不断地增加,所以,性能瓶颈在加剧,越往后就越明显。
为什么不看响应时间就下此结论呢?其实响应时间是用来判断业务有多快的,而 TPS 才是用来判断容量有多大的。
结论:随着系统的压力增大,系统的瓶颈就是在响应时间增加时,tps不再增加
性能衰减的过程
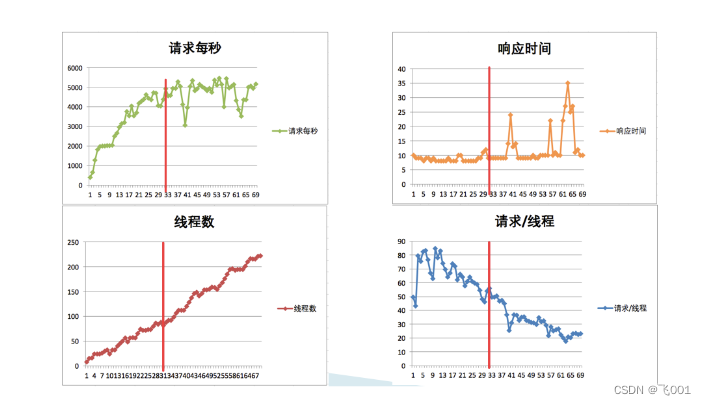
先看一个压力过程中产生的结果图,在递增的压力过程中,随着用户数的增加.性能是在不断地衰减的,如下图所示
-
通过红线的大致比对可以知道,当每线程每秒的请求数降到 55 左右的时候,TPS 就达到上限了,大概在 5000 左右,再接着往上增加线程已经没有用了,响应时间开始往上增加了
-
要每线程每秒的 TPS 开始变少,就意味着性能瓶颈已经出现了。但是瓶颈出现之后,并不是说服务器的处理能力(这里我们用 TPS 来描述)会下降,应该说 TPS 仍然会上升,在性能不断衰减的过程中,TPS 就会达到上限。
-
性能瓶颈其实在最大 TPS 之前早就已经出现了
TPS=每线程每秒TPS * 线程数 如果一个系统没有瓶颈,理论上来说每线程每秒TPS 是固定不变的,在增大线程数时,TPS也要同比例增大,如果没有同比例增大,意味着每线程每秒TPS是在降低的,也就是系统有瓶颈了,只是这个瓶颈可能不够明显
响应时间的拆分
服务内部拆分
在性能分析中,响应时间的拆分通常是一个分析起点,因为在性能场景中,不管是什么原因,只要系统达到了瓶颈,再接着增加压力,肯定会导致响应时间的上升,直到超时为止。所以我们需要找到它在哪个阶段时间变长了,我们先来看服务内部拆分
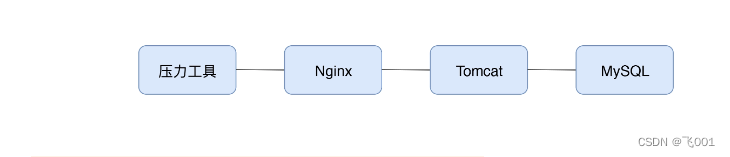
-
查看 Nginx 上的时间
日志里就可以通过配置 requesttimeupstream_response_time 得到日志如下信息,前面是请求时间的 28ms,后面是后端响应时间的 28ms。
14.131.17.129 - - [09/Dec/2019:08:08:09 +0000] "GET / HTTP/1.1" 200 25317 0.028 0.028
-
Tomcat 上去看时间
请求时间消耗了 28ms,响应时间消耗了 27ms。
172.18.0.1 - - [09/Dec/2019:08:08:09 +0000] "GET / HTTP/1.1" 200 25317 28 27 http-nio-8080-exec-1
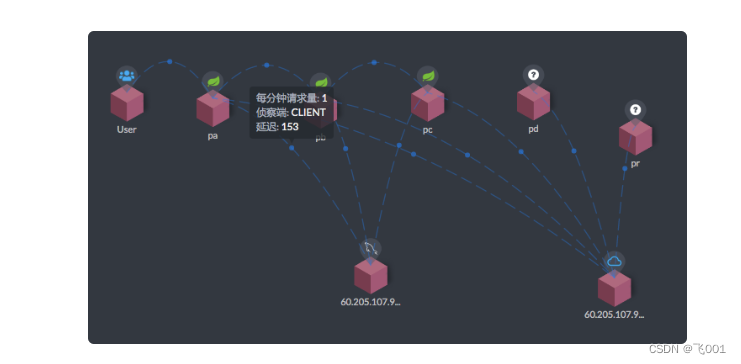
服务之间拆分
下面这张图就需要链路监控工具来拆分时间了

每个服务之间的调用时间,都需要查看监控或者日志,这就是时间拆分的一种方式
场景的比对
当你觉得系统中哪个环节不行的时候, 又没能力分析它,你可以直接做该环节的增加,看tps是否增加,如果增加,说明该节点有问题。
本篇总结:
-
首先,要准确的判断瓶颈点。通过什么来判断呢?TPS曲线。TPS曲线能够告诉我们系统是否有瓶颈,以及瓶颈是否与压力有关。为什么不需要响应时间曲线来判断呢?因为响应时间主要是用来判断业务快慢的。
-
我们要确定我们设置的性能场景是正确的,线程是逐渐递增的,而不应该一上来就上几百个线程。原因:1、直接上几百个线程不符合一般情况下的真实场景。2、即使是秒杀场景也有个“数据预热”的过程(我的理解,数据预热跟线程递增应该差不多,有一个由小到大逐渐增加的过程)3、对于TPS已经到达上限的系统来说,除了响应时间的增加,没有其他作用
-
我们要拥有能判断性能衰减的能力。如何判断?分段计算每线程每秒的TPS,如果这个数值开始变少,那么性能瓶颈就出现了。此时再随着线程的增加,性能逐渐衰减,TPS逐渐达到上限。 然后,我们知道性能开始衰减了
-
那么是什么原因导致的衰减?此时就需要对响应时间进行拆分,拆分的前提需要熟悉系统的架构,拆分的目的是要知道每个环节消耗的时间,拆分的方法可以通过日志,可以通过监控工具,也可以通过抓包(抓包应该需要和日志配合吧?以老师的例子来说,能抓到tomcat的请求和响应时间吗?我感觉不能……)
-
再然后,最重要的地方到了,我们要逐步构建自己的分析决策树。随着性能分析经验的累加,我们需要整理并总结每次遇到的性能问题以及相对应的解决方法,同时我们还要不断扩充自己的知识库:系统架构、操作系统、数据库、缓存、路由等等,并将这些知识与经验结合起来。重新梳理,由大到小,由宏观到细节,去画出自己的分析决策树。
-
当我们刚开始进行性能分析,没有思路的时候,那就可以通过这种替换法来帮助我们快速定位问题。当然,这种方法比较适合简单的系统,如果系统很复杂,这样替换不一定方便了。


















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









