







 本文详细介绍了如何使用OpenCV的opencv_createsample.exe和opencv_traincascade.exe工具进行图像样本分类,包括正负样本准备、vec描述文件生成及分类器训练流程。并通过实例展示了级联分类器的检测效果。
本文详细介绍了如何使用OpenCV的opencv_createsample.exe和opencv_traincascade.exe工具进行图像样本分类,包括正负样本准备、vec描述文件生成及分类器训练流程。并通过实例展示了级联分类器的检测效果。
最近项目上需要用到机器学习,特利用OpenCV自带的可执行程序对图像样本进行分类处理。
利用OpenCV中opencv_createsample.exe和opencv_traincascade.exe对图像进行分类的主要步骤可分为以下几个部分:
1.准备正样本和负样本
我准备的正样本为30*30的bmp图(8位),特别注意的是正样本大小要一致!
并将其放到pos文件夹下,利用windows自带的批处理程序,生成pos.dat文件(pos路径下),pos文件格式如下:
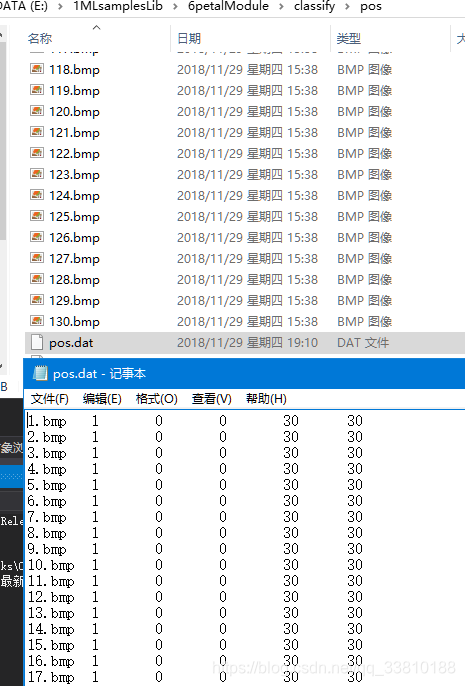
同样地,将负样本放在新建的neg文件夹下,并生成neg.dat文件(.dat格式可以更改的)
2.生成vec描述文件
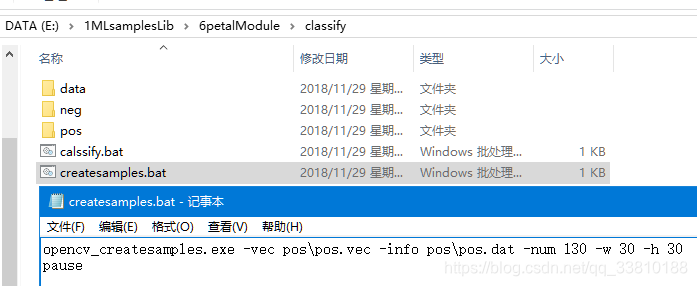
将pos文件夹下的所有样本生成.vec文件,该部分可以在pos和neg文件夹的同级目录下新建createsamples.bat文件(批处理文件),文件中内容如下:
opencv_createsamples.exe -vec pos\pos.vec -info pos\pos.dat -num 130 -w 30 -h 30
其中pos.vec文件放在pos文件夹中,-num为正样本的数目,-w 宽度 -h 高度
可以在后面添加pause,以便批处理后暂停查看处理信息,具体如下:
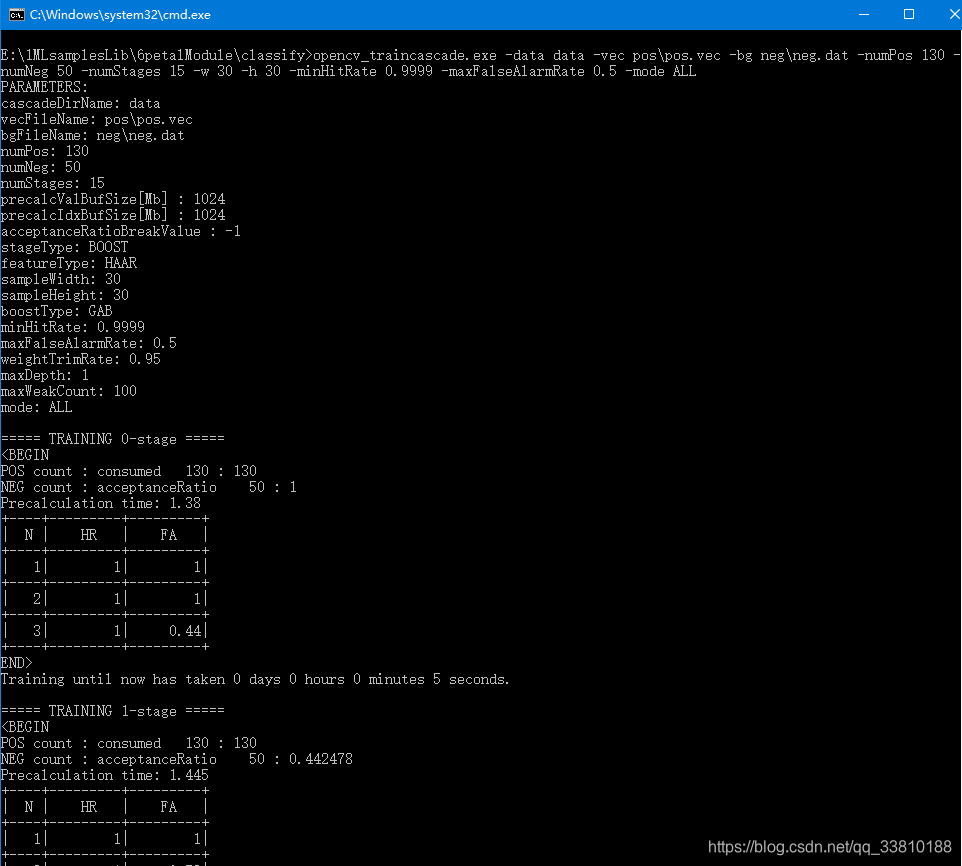
生成后的效果图如下:
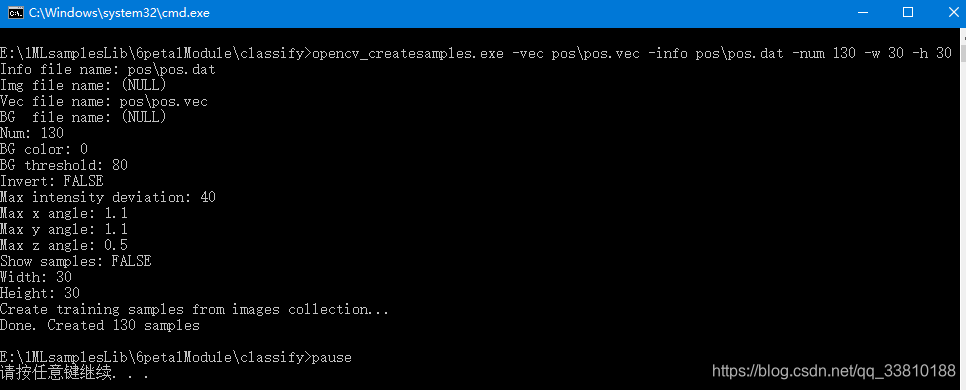
若上述报错,一定要仔细查找出错原因,否则后续无法正常进行!
3.生成分类器
首先要在pos文件夹和neg文件夹同级目录下新建data文件夹(以便存储生成的分类器文件),同时新建calssify.bat批处理文件,其内容如下:
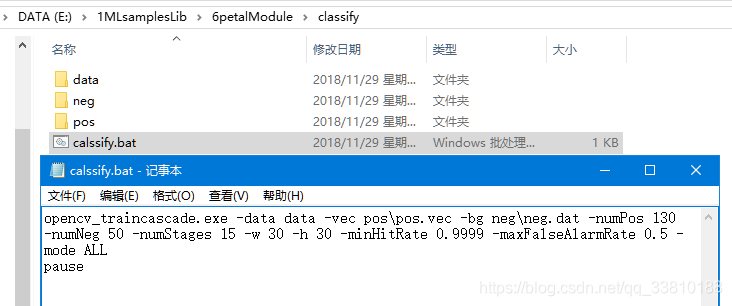
特别注意上述的路径!后续生成过程出现问题,很大一部分原因是路径出现问题!其参数说明如下:
-------------------------------------------
-data data 分类生成的文件放置的位置(在刚才新建的data文件夹里)
-vec pos\pos.vec 加载vec文件(pos.vec文件在pos文件夹里)
-bg neg\neg.dat 加载负样本文件
-numPos 130 正样本的数量
-numNeg 50 负样本的数量(neg文件夹下有50张负样本)
-numStages 15 样本训练的层数(层数多,耗时长,建议15~20)
-w 30 -h 30 样本大小
-minHitRate 0.9999 最小命中率(训练目标的准确度)
-maxFalseAlarmRate 0.5 最大误检率(每一层的训练值小于该值,即可进行下一层的训练)
-mode ALL 特征检测的方式(ALL表示haar全方位检测)
此外还有:
-mem 可用于设置电脑使用内存
-numStages 训练分类器的级数,强分类器的个数
-precalcValBufSize 缓存大小,用于存储预先计算的特征值,单位MB
-precalcldxBufSize 缓存大小,用于存储预先计算的特征索引,单位MB
-featureType 特征检测类型(默认Haar特征,还有LBP和HOG特征)
-------------------------------------------
训练后效果图如下:
中间省略。。。
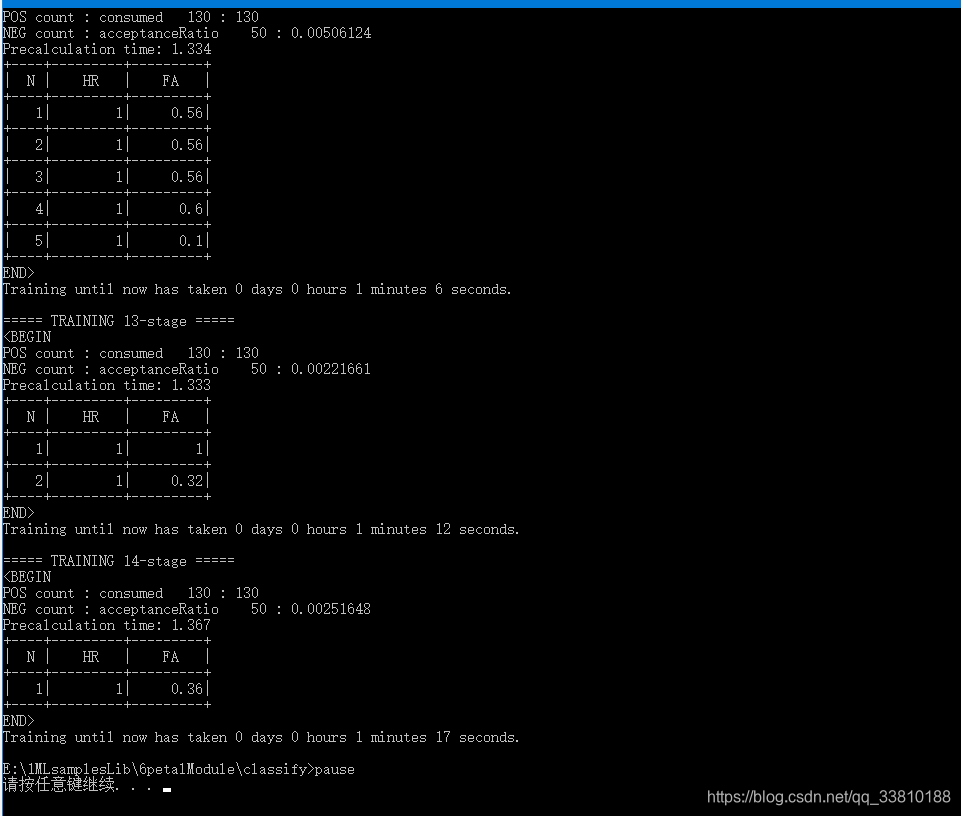
训练的stage较多,一部分原因是参数设置,另外一部分原因是样本大小。
-----------------------------------------------------------------
生成完毕后,可在data文件夹下看到生成的.xml文件(分类器数据),后续进行样本预测可用cascade.xml文件。
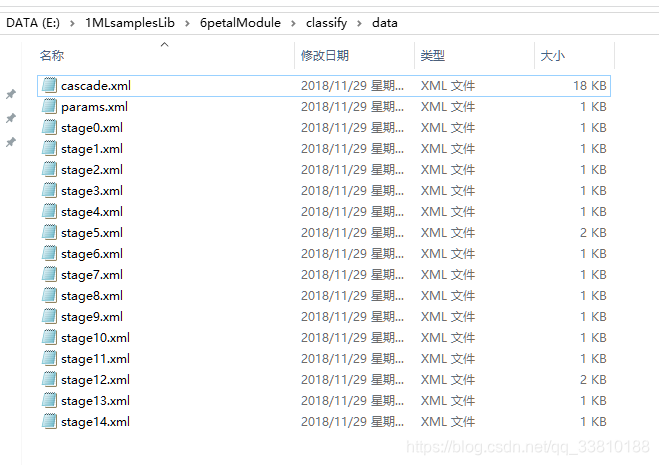
整个处理过程,速度还是很快的(我的数据很少),期间容易出错的地方包括:
1.各文件的路径(相对路径关系);
2.pos.dat文件中数据的排列格式(当然后缀不一定要取.dat,也可以.txt)
3.样本过大,比如全是60*60的,且参数设置严格,训练非常耗时,可能需要十几个小时!,样本最好为20*20(我的为30*30);
-----------------------------------------------------------------
注意事项:
1.正负样本数量搭配最好满足 1:(2.5~3.0);
2.负样本的尺寸最好比正样本尺寸大很多,例如正样本为20*20,负样本为1024*960;
3.负样本之间需要有较大的差异性;
4.numPos最好要小于.vec文件中正样本的数量,一般取0.9倍的正样本数量;
5.正样本中样本图案像素数量要大于背景图像像素数量(即正样本要集中体现样本图案!);
6.-numNeg 中负样本的数量可以超过实际负样本的数量(通常这样的效果较好!);
7.训练的速度 LBP>HOG>HARR(HARR的速度非常慢!);
-----------------------------------------------------------------
-----------------------------------------------------------------
下面展示利用级联分类器进行特定目标检测的效果。
1.正样本总数774个,大小为30*30;

2.负样本总数2690个,大小为120*120;

3.训练采用的配置参数如下:特征模式为LBP;特征集为CORE;级联层数20级;每一级正样本数600个;每一级负样本数5000个;最小检出率为0.9999;最大虚警率0.5。
4.训练耗时半小时左右(i7处理器、8G内存);
5.训练完成后,将.xml加载到检测中,检测函数对象.detectMultiScale中scaleFactor为1.1,minNeighors为1,flags为4,minSize和maxSize分别为21*21、30*30。参数具体含义可以参考opencv官方文档。
6.被检测对象如下:

7.不同对象被检测的效果如下:






以上述检测结果可看出,其检测的效果并没有想象中的那么好!有的特征没有检测出来,更有误检存在!(上中、下左、下右三幅图全检OK,其余三幅存在问题!)。
在工业检测中,上述的精度很难满足实际的应用要求!直观判断,出现问题主要是因为样本的选取,其次是训练参数的设置。
后续将进一步理解级联分类器,致力于提高其检测精度!

















 2287
2287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









