







一、安装配置
单机模式
(1)下载zoopeeker的压缩包并上传到linux服务器,解压。
(2)进入conf目录,将zookeeper.cfg改为zoo.cfg。
(3)进入bin目录,sh zkServer.sh start打开服务器。
(4)通过sh zkServer.sh status查看,Mode:standalone说明单机模式启动。通过jps -vm可以看到zookeeper包启动了.
(5)sh zkCli.sh可以启动客户端。CONNECTED表示连接成功。
集群模式(生产中使用)
(1)进入conf目录,修改zoo.cfg文件。
server.A = B:C:D :
A表示这个是第几号服务器,
B 是这个服务器的 ip 地址;
C 与 Leader 服务器交换信息的端口;
D 选举的端口号
server.1=192.168.1.32:2188:2888
server.2=192.168.1.30:2188:2888
server.3=192.168.1.34:2188:2888
(2)指定myid服务号,进入/tmp/zookeeper目录。
echo "1" >/tmp/zookeeper/myid
(3)进入bin目录,sh zkCli.sh -server 192.168.1.32:2181,192.168.1.30:2181,192.168.1.34:2181连接集群的服务器。
二、集群角色
Leader:主节点,负责响应所有对zookeeper状态变更的请求。会将每个状态更新请求进行排序和编号,以保证整个集群内部消息处理的FIFO,写操作都走leader。
注:leader只有一个。
Follower:响应本服务器上的读请求外,follower还要处理leader 的提议,并在leader提交该提议时在本地也提交。
Observer:可以处理读请求,目的:提高吞吐量,不参与投票,不参加选举不响应提议。
三、命令介绍

四、Zookeeper核心概念
Znode:数据节点,类似文件系统的层级树状结构。字节数组。
节点类型:持久(无序)、临时(无序)、持久有序和临时有序。
create -e /lc 2020创建临时节点
zookeeper默认节点的名称就是zookeeper
stat:记录了Znode的三个数据版本
version(当前ZNode的版本)
cversion(当前ZNode子节点的版本)
cversion(当前ZNode的ACL版本)
| 状态属性 | 说明 |
|---|---|
| czxid | 节点创建时的zxid |
| mzxid | 节点最新一次更新发生时的zxid |
| ctime | 节点创建时的时间戳. |
| mtime | 节点最新一次更新发生时的时间戳. |
| dataVersion | 节点数据的更新次数. |
| cversion | 其子节点的更新次数 |
| aclVersion | 节点ACL(授权信息)的更新次数. |
| ephemeralOwner | 如果该节点为ephemeral节点, ephemeralOwner值表示与该节点绑定的session id. 如果该节点不是ephemeral节点, ephemeralOwner值为0. 至于什么是ephemeral节点 |
| dataLength | 节点数据的字节数. |
| numChildren | 子节点个数. |
dubbo注册中心zk节点是临时节点:断开服务就无法找到。
watcher:事件监听器,是Zookeeper中的一个很重要的特性。Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。
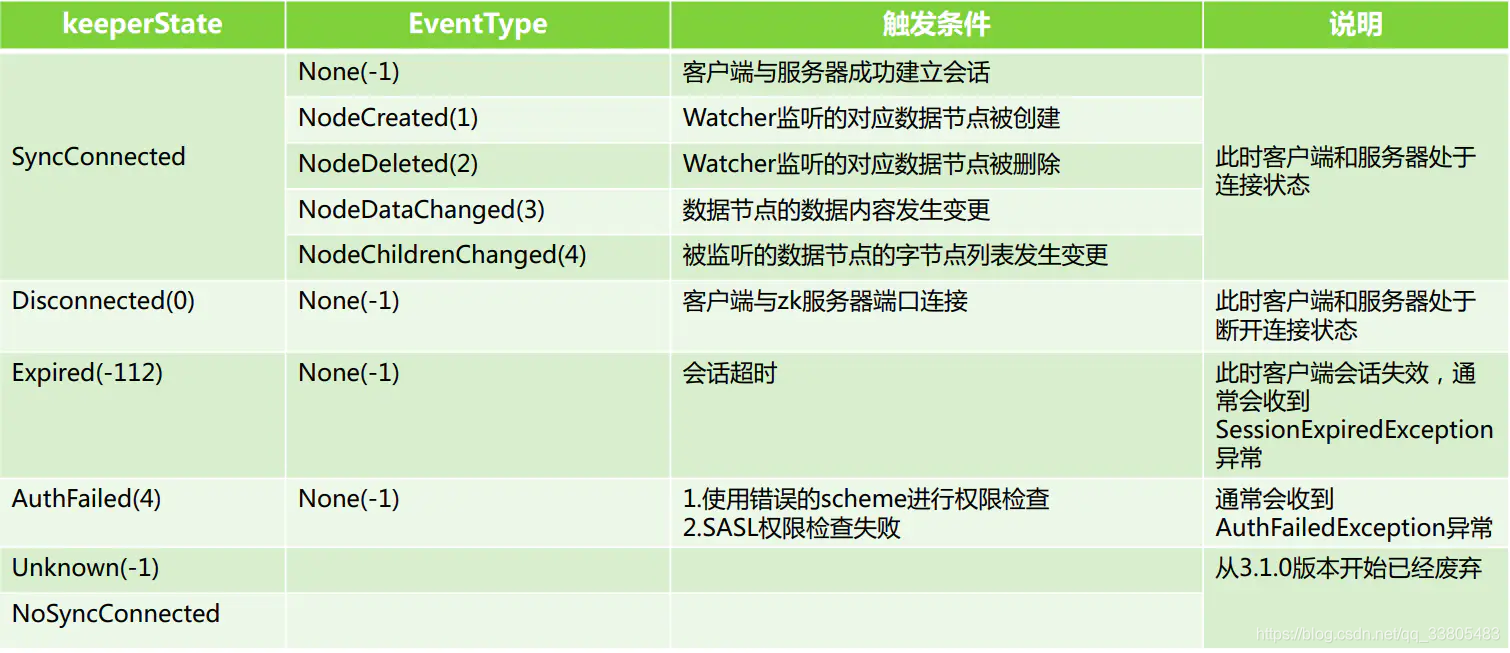
watcher只能监听到某个节点以及它的子节点,对于孙子节点是无法监听的。而且触发一次后会失效,需要重新建立监听事件。
ACL:权限管理。
world:默认方式,相当于全世界都能访问
auth:代表已经认证通过的用户(cli中可以通过addauth digest user:pwd 来添加当前上下文中的授权用户)
digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
ip:使用Ip地址认证
在本机中设置了密码之后依然可以通过get获取到数据,这是由于当前session的原因。其它集群中的机子无法直接get获取到数据。
高性能
主写从读,适合读多写少的场景。
顺序访问
对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。 这个编号也叫做时间戳——zxid(Zookeeper Transaction Id)
五、leader选举
Paxos算法:共识算法、选举
分布式一致性算法:
最终一致性:DNS
强一致性:Paxos、Raft、ZAB
ZAB协议
1、初始化leader选举,投票
给自己投票 myid zxid
2、每个服务器接受投票
(1 0)(2,0)(3,0) > myid 谁最大谁就是leader,2号是leader。和启动顺序有关系
3、处理投票
别的服务器 pk
4、统计投票
过半的票数
5、服务器状态变更
leader,其他改为follower
服务器状态:looking、leader、follower、observer

















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









