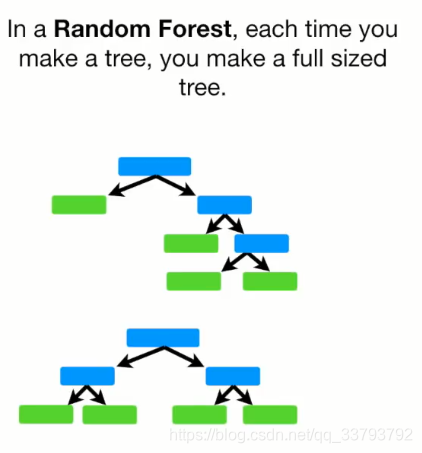
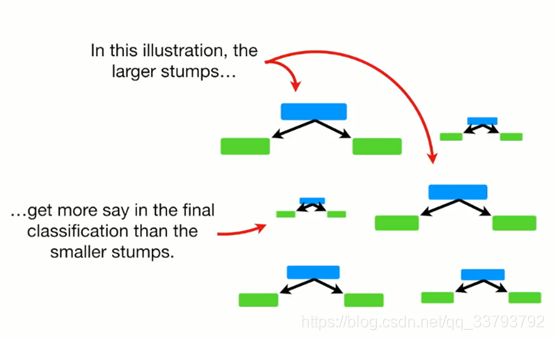
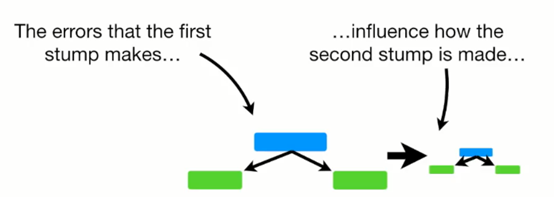
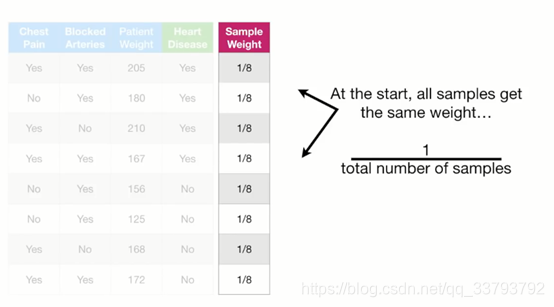
随机森林与Adaboost之间的区别 随机森林里的树为满二叉树 而Adaboost里的树为树桩(只有根节点和2个叶子节点) 在进行预测时 随机森林中的每棵树拥有同样的话语权 而adaboost中每棵树的话语权都是不一样的 随机森林哪棵树先进行预测无所谓 但adaboost有影响 如何构造第一个弱分类器(树桩) 先给每个样本一个初始的权重=1/样本总数 确定选用哪个特征:Gini系数 分别计算左右两边的纯度:1-(预测正确的比例)2-(预测错误的比例)2 然后加权平均 例如Chest Pain这个特征: 左边:1-(3








 本文探讨了Adaboost与随机森林的区别,并详细介绍了如何构建Adaboost的第一个弱分类器,包括权重初始化、特征选择和错误率计算。接着,解释了如何通过调整样本权重来构造后续的弱分类器,并说明了Adaboost分类过程。
本文探讨了Adaboost与随机森林的区别,并详细介绍了如何构建Adaboost的第一个弱分类器,包括权重初始化、特征选择和错误率计算。接着,解释了如何通过调整样本权重来构造后续的弱分类器,并说明了Adaboost分类过程。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






