







 本文介绍了Hystrix,它可解决分布式系统中服务雪崩问题,作用包括服务降级、熔断和限流。详细阐述了服务降级的多种实现方式,如单独配置、统一fallback及结合openFegin,还说明了服务熔断的过程和配置,最后总结了服务降级和熔断的异同点。
本文介绍了Hystrix,它可解决分布式系统中服务雪崩问题,作用包括服务降级、熔断和限流。详细阐述了服务降级的多种实现方式,如单独配置、统一fallback及结合openFegin,还说明了服务熔断的过程和配置,最后总结了服务降级和熔断的异同点。
文章目录
一、Hystrix是什么?
GitHub上面给出的解释:

简而言之就是,现如今的分布式系统之中,不可避免的会出现A服务调用B服务,B服务调用C服务。。。这种链式的调用被称作“扇出”,而这些服务中的调用中若是某一个服务出故障或者超时,就会影响其他服务的调用,进而拖垮整个系统,这也就是“服务雪崩”。比如A->B->C,其中B服务可接受的请求响应时间为2s,但是C服务需要处理的业务逻辑时间为3s,那么B服务就会因为迟迟拿不到C服务响应而出错,进而导致所有进入B服务的请求报错。
针对这种“服务雪崩“的情况,Hystrix应运而生。
Hystrix的作用:
GithHub解释:
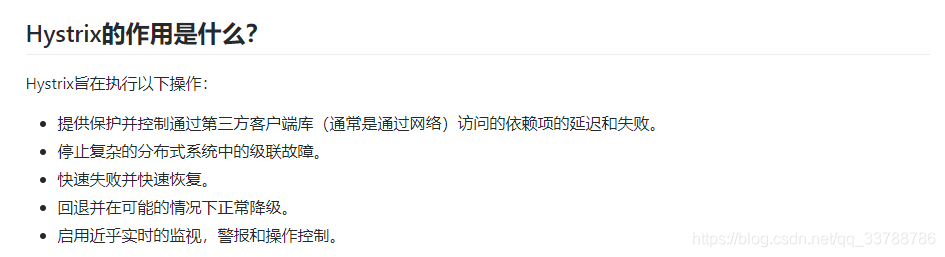
说白了,也就是服务降级,服务熔断,服务限流。
服务降级:当服务因为超时,运行出错,或者线程池/信号池满了,不能立即向调用方响应时,就应该向调用方返回一个可以接受,较为合理的Fallback响应。
服务熔断:在某段时间内 服务的调用异常达到一定频率,服务就会熔断,进行服务降级,然后在窗口期之内监控到服务调用恢复正常,就会自动恢复服务。简而言之就是,降级->熔断->恢复
服务限流:通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务
二、服务降级
1.pom引入

2.编写Controller
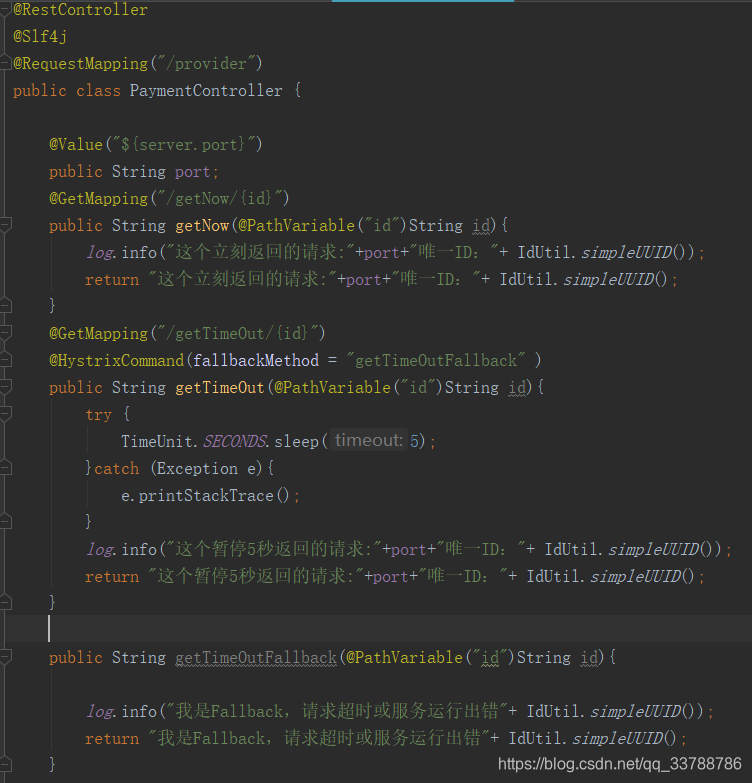
@HystrixCommand注解表明了此方法在调用时出现超时,出错等异常情况,那么就进行服务降级,调用fallbackMethod所指向的方法,默认的服务降级超时时间为1s。
3.修改主启动类
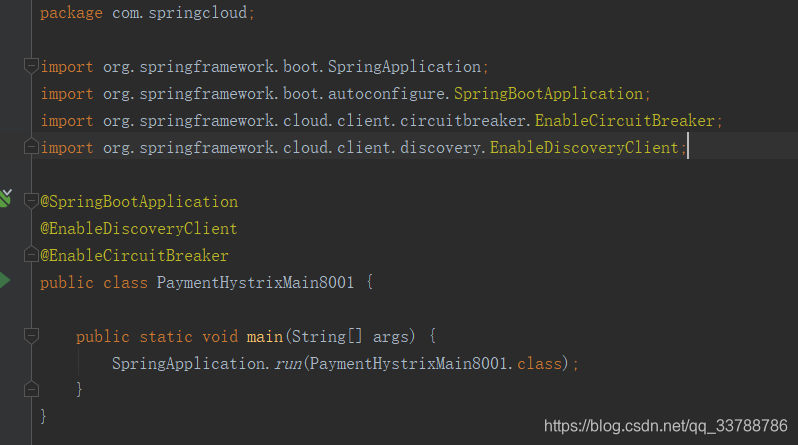
添加@EnableCircuitBreaker开启服务降级熔断机制。
4.测试
在没有配置任何Hystrix时程序程序正常访问,需要等待5秒钟,返回结果。(正常情况我在此就不展示接结果了)
配置服务降级熔断之后

访问触发Fallback返回结果。
当然也可以修改访问超时时间
@HystrixCommand(fallbackMethod = "getTimeOutFallback",commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "3000")
})
三、服务降级(统一fallback)
其实不难想象,如果没有调用的方法都要配置有个Fallback的话就会造成代码过量,而且难于管理。
所以迫切的需要提供一个统一的fallback,如果有需要的特殊化的fallback那就自行定义。
1.代码改造
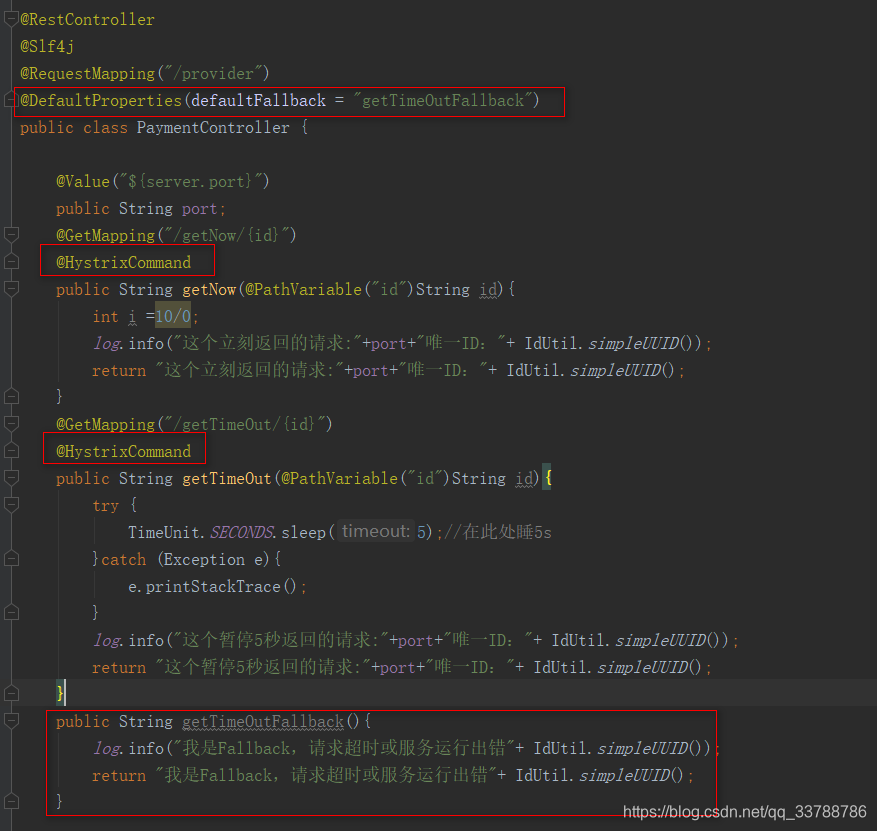
如图所示:
在Controller方法上定义@DefaultProperties(defaultFallback = “getTimeOutFallback”)指明默认的服务降级都走getTimeOutFallback方法作为fallback,需要服务降级处理的方法上只需要添加@HystrixCommand即可,如果有特殊fallback那么可以自行配置。
2.测试


两个方法访问时都调用的同一个fallback。
四、服务降级(结合openFegin)
其实在真实的项目中,服务降级更多的是在服务消费端使用,因为服务降级更多的是保证自己服务可以正常的运行,所以服务降级一般都从外围服务开始。而openFegin是服务间调用的组件,与Hystrix整合良好。下面实例说明。
1.搭建注册中心服务
(注册中心搭建可以参考我写的Spring cloud之Eureka组件集成学习.)
2.搭建消费服务
(1)pom引入
(2)配置文件
添加如下配置

(3)修改主启动类
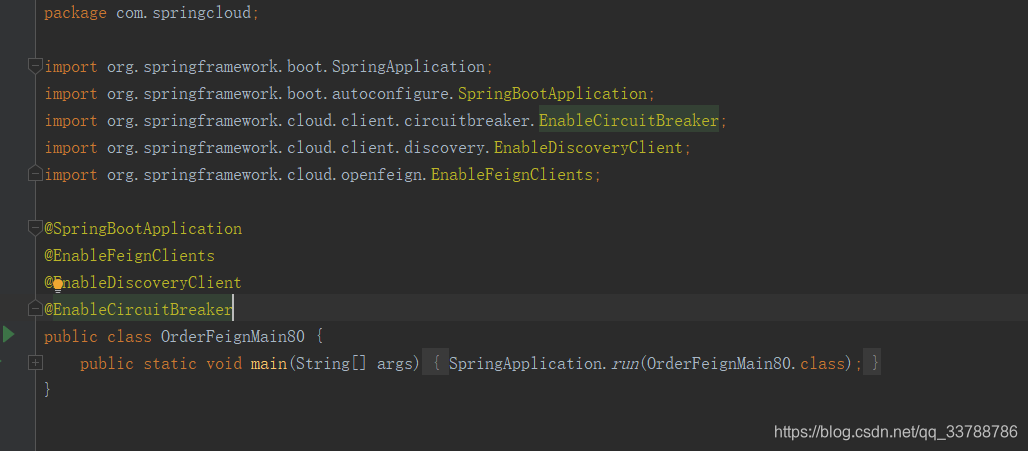
添加@EnableFeignClients和@EnableCircuitBreaker注解
(4)编写feginService和fallbcak
PaymentFeignService
@Component
@FeignClient(value = "CLOUD-PAYMENT-HYSTRIX-SERVICE",fallbackFactory = PaymentFeignServiceImpl.class )
public interface PaymentFeignService {
@GetMapping("/provider/getNow/{id}")
public String getNow(@PathVariable("id") String id);
}
其中fallbackFactory就是服务降级的fallback所调用的类。其实这里配置为fallback也是可以的,只不过fallbackFactory可以看到调用时候的报错信息,而fallback所配置的类必须为feginservice的实现类。
PaymentFeignServiceImpl
@Component
public class PaymentFeignServiceImpl implements FallbackFactory<PaymentFeignService> {
@Override
public PaymentFeignService create(Throwable throwable) {
return new PaymentFeignService(){
@Override
public String getNow(String id) {
return "这个是fegin的fallback";
}
};
}
}
(5)编写controller
@RestController
@Slf4j
@RequestMapping("/order")
public class OrderController {
@Resource
public PaymentFeignService paymentFeignService;
@GetMapping("/getPayment/{id}")
public String getPayment(@PathVariable("id") String id){
log.info("查询PayMent信息");
String result =paymentFeignService.getNow(id);
log.info("返回结果:"+result);
return result;
}
}
3.测试

测试通过。
五、服务熔断
上面提到过。服务熔断整个过程就是服务降级->服务熔断->服务恢复的过程,所以服务熔断其实是具有类似于自我恢复的过程,而就服务熔断来说,更多的是为了保护自身服务运行时出现的异常情况进而导致服务雪崩。
1、修改paymentController
@GetMapping("/getNow/{id}")
@HystrixCommand(fallbackMethod = "getNowFallback",commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60")
})
public String getNow(@PathVariable("id")String id){
if("0".equals(id)){
int i= 10/0;
}
return "这个立刻返回的请求:"+port+"唯一ID:"+ IdUtil.simpleUUID();
}
public String getNowFallback(@PathVariable("id")String id){
return "我是Fallback,请求超时或服务运行出错"+ id;
}
circuitBreaker.enabled:是否激活断路器(默认是激活的,看到这里是不是有点小疑惑呢,一会说。)
circuitBreaker.requestVolumeThreshold: 请求数(默认是10)
circuitBreaker.sleepWindowInMilliseconds: 窗口期(默认是5s)
circuitBreaker.errorThresholdPercentage: 错误率(默认是50%)
代码中的配置可以简单理解为:在10s中的窗口期内,通过10次请求,6次及以上出错,断路器会打开。
那么在下一个窗口期内它会监控请求的成功率,若是符合要求,会关闭断路器,服务恢复正常,不符合继续打开,下次窗口期再看。所以说熔断的过程就是:打开断路器->半开断路器->关闭断路器。
2、测试
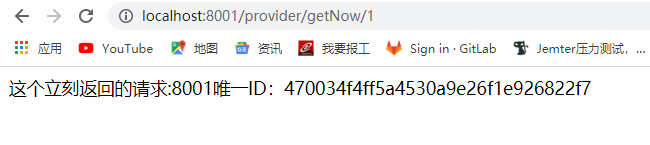
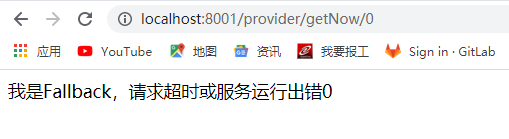
代码里面做了判断,如果入参为0则会fallback,其余数字都会正常返回。
正常请求返回:
报错返回:
熔断之后的返回接口:
在频繁点击报错之后,服务熔断,即便我输入的参数不等于0,他的返回为错误,那么说明此前断路器已经打开,当我请求数字为15的时候,断路器处于半开状态,只要达到一定值,那么服务会恢复正常
3、刚才提到的小疑惑(其实是自己的疑惑)
在上面编写服务降级的实例时,启用了@HystrixCommand,配置了超时时间,告诉大家这就是服务降级,但是在刚才提到的服务熔断中说到,@HystrixCommand的注解中,断路器时默认激活的,而且在文章的开头有提到服务降级和服务熔断是有区别的,那么这就可能导致大家有些混乱了(其实是我自己在初次学习的时候,发现既然说的是两个概念,即便是熔断包含了降级,但是实例不应该分开吗?)
在我掐着秒钟测试完默认情况下的断路器之后,才发现我上面写的不够严谨,应该将断路器关闭,毕竟服务降级本身更倾向于,减轻系统压力,而服务熔断倾向于维护某一个微服务自身。
不过呢,上述实例在理解降级和熔断机制上不会给大家造成太大的困扰,所以就没有改了。
(以上观点仅个人见解,欢迎大家指正,没有冒犯他人的意思。狗头保命)
六、总结
下面引用一下在大多数博客大大的文章里面的看到的话:
服务降级和服务熔断的异同点
相同点:
目的很一致:都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
最终表现类似:对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
区别:
触发原因不太一样:服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
管理目标的层次不太一样:熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









