




 本文介绍了如何使用Python实现对话系统的Embedding Average评价指标,该方法通过计算句子中每个词向量的平均值来获取句子的特征向量。接着,利用余弦相似度来衡量两个句子的相似性。文章提供了从GloVe官网下载预训练词向量的步骤,并给出了具体的Python代码示例。
本文介绍了如何使用Python实现对话系统的Embedding Average评价指标,该方法通过计算句子中每个词向量的平均值来获取句子的特征向量。接着,利用余弦相似度来衡量两个句子的相似性。文章提供了从GloVe官网下载预训练词向量的步骤,并给出了具体的Python代码示例。
Embedding Average 向量均值法是通过句子中的词向量计算一个句子特征向量的方法,通过对句子中每一个词的向量求均值来计算句子的向量。这种方法在除对话系统之外的很多NLP领域内都应用过(例如计算文本相似度的任务),公式中![]() 表示句子
表示句子r中所有词组的词向量均值:
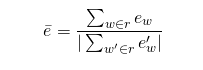
对比r与
Embedding Average 向量均值法是通过句子中的词向量计算一个句子特征向量的方法,通过对句子中每一个词的向量求均值来计算句子的向量。这种方法在除对话系统之外的很多NLP领域内都应用过(例如计算文本相似度的任务),公式中![]() 表示句子
表示句子r中所有词组的词向量均值:
对比r与
 457
3276
457
3276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















