







 在尝试使用pdfminer时遇到了ModuleNotFoundError。问题出在同时安装了pdfminer和pdfminer3k,解决方案是卸载两者并安装pdfminer.six。在卸载并正确安装pdfminer.six后,命令行不再报错,但PyCharm中依然存在问题。原因是Anaconda的两个不同安装路径导致的混淆。通过在特定Anaconda的scripts文件夹中运行安装命令解决了PyCharm的报错问题。
在尝试使用pdfminer时遇到了ModuleNotFoundError。问题出在同时安装了pdfminer和pdfminer3k,解决方案是卸载两者并安装pdfminer.six。在卸载并正确安装pdfminer.six后,命令行不再报错,但PyCharm中依然存在问题。原因是Anaconda的两个不同安装路径导致的混淆。通过在特定Anaconda的scripts文件夹中运行安装命令解决了PyCharm的报错问题。
最开始输入
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
报错:
Traceback (most recent call last):
File "G:/Python_Prj/ReadPDF/pdf.py", line 7, in <module>
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
ModuleNotFoundError: No module named 'pdfminer'
在命令行窗口键入conda info查看一下版本信息
pdfminer和pdfminer3k分别对应于python2.x和python3.x
C:\Users\Administrator>conda info
active environment : None
user config file : C:\Users\Administrator\.condarc
populated config files :
conda version : 4.6.14
conda-build version : 3.16.3
python version : 3.7.1.final.0
base environment : E:\ProgramData\Anaconda3 (writable)
channel URLs : https://repo.anaconda.com/pkgs/main/win-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/free/win-64
https://repo.anaconda.com/pkgs/free/noarch
https://repo.anaconda.com/pkgs/r/win-64
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/msys2/win-64
https://repo.anaconda.com/pkgs/msys2/noarch
package cache : E:\ProgramData\Anaconda3\pkgs
C:\Users\Administrator\.conda\pkgs
C:\Users\Administrator\AppData\Local\conda\conda\pkgs
envs directories : E:\ProgramData\Anaconda3\envs
C:\Users\Administrator\.conda\envs
C:\Users\Administrator\AppData\Local\conda\conda\envs
platform : win-64
user-agent : conda/4.6.14 requests/2.20.1 CPython/3.7.1 Windows/10 Windows/10.0.17134
administrator : True
netrc file : None
offline mode : False
由于之前瞎试,我把pdfminer和pdfminer3k都pip了
我是直接在命令行窗口install和uninstall的
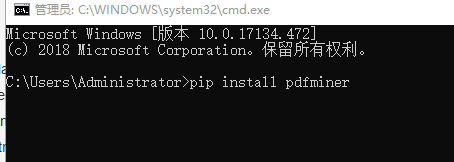
后来在github上看到,最新的python3.7只需要pdfminer.six就行
github链接
github链接2
划重点:python3.7+pdfminer.six
在卸载了pdfminer和pdfminer3k后
输入
pip install pdfminer.six
安装好了之后试一下,命令行没有报错了。

我以为终于弄好了!
但是
我的pycham里面持续给我报错
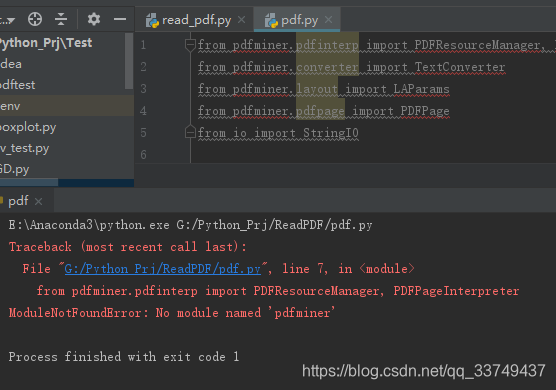
找到anaconda的安装路径,在E:\Anaconda3\Lib\site-packages这个目录下并没有找到pdfminer.six
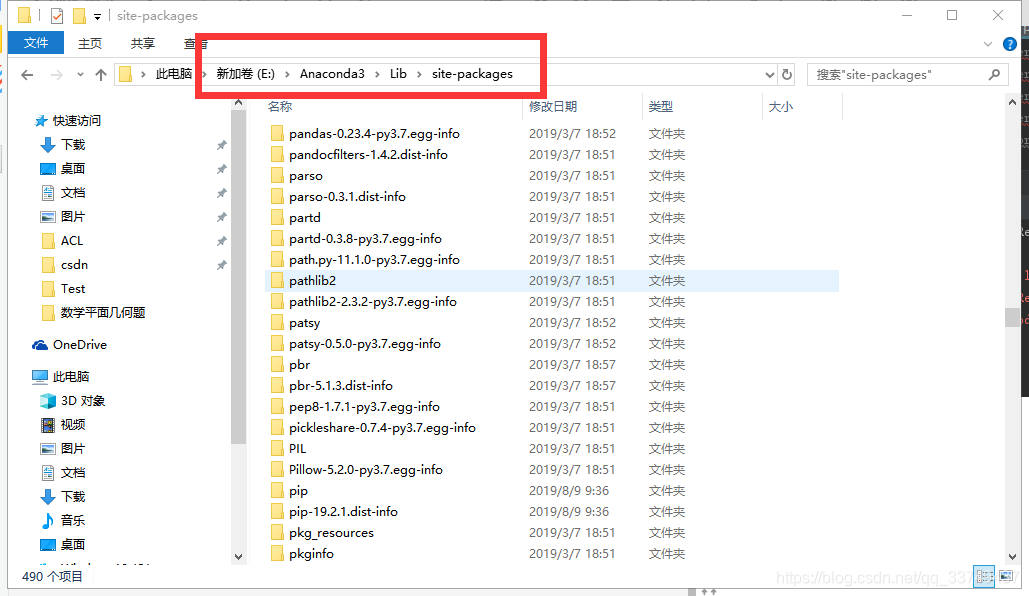
怎么查看哪里出了错呢?
命令行窗口
python
import numpy as np
np.__path__
然后结果发现我在命令行窗口出来的路径不是我记忆中anaconda的安装路径
崩溃。
仔细查看一遍,原来我在E:\ProgramData\Anaconda3 又装了一次anaconda
这样子就很烦,会很容易混淆,但是我又懒得卸载删除了。
总结一下
不在命令行窗口直接安装的话,需要在哪个anaconda下安装说明东西,就进入anaconda下scripts文件夹,直接在红框那里面输入命令,这个是没有安装pdfminer.six的,所以我直接输入pip install pdfminer.six
然后pycharm里面就不报错了,主要pycharm配置anaconda路径是这个,更改好了不报错
我是在jupyter里面写的程序
在指定文件夹下面打开jupyter notebook:
- 在文件夹下空白处按住shift键,单击鼠标右键,
- 选择“在此处打开 powershell 窗口”;或者在文件夹地址栏里输入 powershell 然后回车
- 进入 powershell,敲入 jupyter notebook

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









