






模型model在概率分布log_softmax文本序列值和标签labels值能正确匹配成功输出直接使用 == 运算符可能不够灵活,因为在实际应用中,我们可能希望允许一定程度的差异(例如拼写错误、标点符号差异、大小写差异等)。下面是一些建议来优化比较方法:
1.使用编辑距离(Levenshtein Distance):
编辑距离是衡量两个字符串之间差异的一种指标,它表示将一个字符串转换为另一个字符串所需的最少单字符编辑(插入、删除或替换)次数。在Python中,可以使用 python-Levenshtein 库来计算编辑距离。

在这个函数中,max_distance 是一个阈值,表示允许的最大编辑距离。
2.使用正则表达式或模糊匹配:
对于某些应用,可能需要更复杂的匹配逻辑,比如忽略大小写、标点符号或空格。你可以使用正则表达式或模糊匹配算法来实现这一点。
3.使用序列编码和相似度度量:
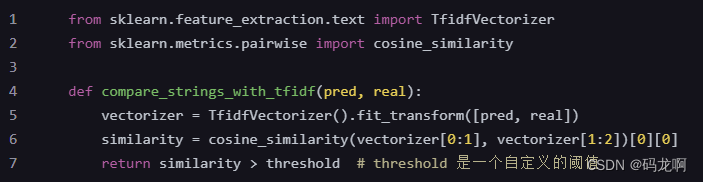
将字符串转换为某种向量表示(例如词袋模型、TF-IDF、word2vec、BERT等),然后计算这些向量之间的相似度(如余弦相似度)。这种方法可以捕获字符串之间的语义相似性,而不仅仅是字面上的相似性。
4.使用字符级别的模型:
如果你的目标是处理字符级别的差异(如拼写错误),你可以考虑使用基于字符级别的深度学习模型(如基于LSTM或Transformer的序列到序列模型)来预测或纠正文本。
5.混合方法:
你可以根据具体的应用场景和需求,结合使用上述方法。例如,你可以先使用编辑距离来过滤掉差异很大的序列,然后再使用TF-IDF或BERT等方法来进一步评估序列之间的相似性。
6.自定义比较函数:
根据你的具体需求,你可以编写自定义的比较函数来定义什么是“正确的”预测。这可以包括考虑多种因素,如字符级别的差异、语义相似性、上下文信息等。
在优化比较方法时,请务必注意评估你的优化是否真正提高了模型的性能。你可以使用交叉验证或留出验证集来评估你的比较方法在不同数据集上的表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









