






摘要
我们介绍了图像目标表示(IGOR),旨在学习人类和各种机器人之间统一且语义一致的动作空间。通过这种统一的潜在动作空间,IGOR 能够在大规模机器人和人类活动数据之间实现知识迁移。我们通过将初始图像与其目标状态之间的视觉变化压缩为潜在动作来实现这一点。IGOR 允许我们为互联网规模的视频数据生成潜在动作标签。这种统一的潜在动作空间使得我们能够在机器人和人类执行的各种任务中训练基础策略和世界模型。我们证明了:
(1)IGOR 学习了人类和机器人之间语义一致的动作空间,表征了代表物理交互知识的各种可能物体运动;
(2)IGOR 可以通过联合使用潜在动作模型和世界模型,将一个视频中的物体运动“迁移”到其他视频中,甚至跨越人类和机器人;
(3)IGOR 可以通过基础策略模型学习将潜在动作与自然语言对齐,并将潜在动作与低级策略模型集成以实现有效的机器人控制。我们相信 IGOR 为人类到机器人的知识迁移和控制开辟了新的可能性[^1]。
1 引言
为具身人工智能(AI)学习基础模型一直受到缺乏交互数据的限制。与文本或视频数据不同,这些数据丰富可用,交互数据则稀缺得多。研究工作致力于创建大规模交互数据集,例如 Open-X-Embodiment(Collaboration et al., 2023[^2],《Open X-Embodiment: Robotic learning datasets and RT-X models》)和 DROID(Khazatsky et al., 2024[^3],《Droid: A large-scale in-the-wild robot manipulation dataset》)。基于多任务交互数据,提出了一系列通用代理(或基础策略模型),例如 RT-1(Brohan et al., 2022[^4],《Rt-1: Robotics transformer for real-world control at scale》)、Robocat(Bousmalis et al., 2023[^5],《Robocat: A self-improving generalist agent for robotic manipulation》)、RT-2(Brohan et al., 2023[^6],《Rt-2: Vision-language-action models transfer web knowledge to robotic control》)、Octo(Team et al., 2024[^7],《Octo: An open-source generalist robot policy》)和 OpenVLA(Kim et al., 2024[^8],《Openvla: An open-source vision-language-action model》)。然而,交互数据的量级仍然比互联网文本或视频数据小几个数量级。鉴于基础模型的成功依赖于扩大数据集规模并从这些大规模数据集中提取知识,设计能够有效利用互联网规模视频数据的具身 AI 基础模型的方法至关重要。
互联网规模的视频数据包含了人类活动的丰富顺序记录,以及人类通过与现实世界互动执行各种任务的完美示范。当人类大脑从视频中提取信息时,并非逐帧进行,而是将帧之间的差异模块化为一个单词,例如“移动”、“打开”、“关闭”。我们将这些高度压缩、模块化的动作称为潜在动作,它们在不同任务中共享。这里的问题是,是否可以从包含人类和机器人执行各种真实具身 AI 任务的视频数据集中恢复潜在动作?尽管近期工作如 Genie(Bruce et al., 2024[^9],《Genie: Generative interactive environments》)和 LAPO(Schmidt & Jiang, 2023[^10],《Learning to act without actions》)尝试从视频中恢复此类潜在动作,但它们主要关注 2D 平台游戏,其中每个潜在动作对应一个特定的控制按钮。动作空间高度针对特定场景设计,无法与各种具身 AI 任务中复杂的人类和机器人动作空间相提并论。进一步的问题是,能否学习一个统一且语义一致的潜在动作空间,允许在不同任务和体现(包括人类和各种机器人)之间迁移知识?
在本文中,我们提出了图像目标表示(IGOR),它学习一个在不同任务和体现之间共享的统一且语义一致的潜在动作空间,从而在互联网规模的视频数据之间实现知识迁移。我们提出了一个潜在动作模型,旨在捕捉各种具身 AI 任务中机器人和人类的动作。IGOR 将图像与其目标状态之间的视觉变化压缩为潜在动作,这些潜在动作也是通过从初始 图像达到目标来定义的子任务的嵌入。IGOR 通过最小化目标状态的重建损失进行训练,该目标状态是基于图像和潜在动作预测的。IGOR 的核心观点是,如果压缩得当,具有相似视觉变化的图像 - 目标对将具有相似的嵌入。
我们认为,除了用于人类指令理解的文本嵌入和用于状态理解的图像 / 视频嵌入之外,用于潜在动作学习和子任务理解的图像 - 目标表示是另一个关键构建块,可能对具身 AI 的下一代泛化具有巨大潜力。
有了潜在动作模型,我们可以将互联网规模的人类视频数据转换为带有潜在动作标签的交互数据,这大大扩展了构建具身 AI 基础模型可用的数据。这种统一的潜在动作空间使我们能够在机器人和人类执行的几乎所有任务上训练基础策略和世界模型。具体来说,我们在大规模视频数据上带有文本标签的数据上训练一个基础策略模型。该模型使用文本描述任务并做出决策,生成要执行的下一个潜在动作。此外,我们在相同的数据集上训练一个基础世界模型,学习模拟执行基础策略模型的结果。图像 - 目标表示可以被视为视觉空间中的原子控制单元。它们既作为基础策略模型在视觉轨迹规划中预测的潜在动作,也作为机器人特定的低级策略要执行的子任务。
我们在带有动作移除 actions removed 的人类视频数据和机器人数据上训练模型,并将 RT-1 数据集保留用于 OOD 评估。首先,我们定性评估潜在动作模型,发现具有相似潜在动作的图像 - 目标对具有相似的视觉变化,对应于语义一致的运动,即使在 OOD 场景中也是如此。然后,我们通过从视频中提取潜在动作,并将这些潜在动作(或动作序列)应用于其他视频的初始帧,使用世界模型生成剩余帧,来评估世界模型。我们发现,与潜在动作模型和世界模型一起,IGOR 成功地将一个视频中的物体运动“迁移”到其他视频中,如图 2 所示。
图2:我们从实心线框中的图像目标对中提取潜在动作,并将潜在动作应用于不同的初始帧,从而通过世界模型生成后续视频,如相应的虚线盒中所示。上半部分说明了来自具有不同对象类别的现实世界视频的示例,而下半场则证明了从人类到机器人臂的概括。完整的视频可在我们的网站上找到

我们还将不同的潜在动作应用于同一初始图像,并发现世界模型已经学会了图像中物体的各种可能运动,表明它吸收了物理交互知识。对于基础策略模型,我们展示了其通过迭代展开基础策略和世界模型使用潜在动作遵循多样化语言指令的能力。我们进一步将其与低级策略集成,并展示了基于 IGOR 的策略训练可以在低数据量情况下提高在 Google Robot 任务上的性能,使用 SIMPLER(Li et al., 2024[^11],《Evaluating real-world robot manipulation policies in simulation》)模拟器。
2 方法论
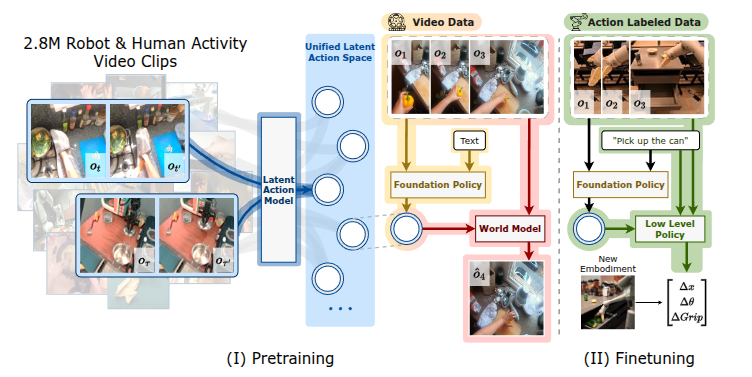
图1:基于图像目标(IGOR)体现AI的训练框架。IGOR通过压缩来自机器人和人类活动的数据的图像和目标状态之间的视觉变化来了解人类和机器人的统一潜在动作空间。通过标记潜在的动作,Igor促进了从互联网规模的人类视频数据中学习基金会政策和世界模型,涵盖了各种体现的AI任务。在语义上一致的潜在作用空间,伊戈尔可以实现人类对机器人的概括。基础政策模型在潜在行动级别充当高级控制器,然后将其与低级政策集成在一起,以实现有效的机器人控制。
2.1 潜在动作模型
潜在动作模型的主要目标是以无监督的方式从未标记的开放域视频中标记潜在动作。给定一系列视频帧 ![]() ,目标是推导出潜在动作
,目标是推导出潜在动作 ,它仅捕获在时间步 t 发生的变化的关键信息,移除其他冗余信息。与以往工作(Schmidt & Jiang, 2023[^10],《Learning to act without actions》)和(Bruce et al., 2024[^9],《Genie: Generative interactive environments》)不同,这些工作主要关注 2D 平台游戏,其中每个潜在动作 at 对应一个特定的控制按钮,我们旨在开发一个更具通用性的模型。我们的模型旨在处理开放世界场景的显著复杂性,其中潜在动作可能不对应于任何特定的基础动作。这带来了几个额外的挑战。
首先,潜在动作模型不能仅仅关注像素变化的绝对位置,而必须学会捕捉在不同场景中保持一致的语义运动。此外,由于时间冗余,动作通常在长上下文中是稀疏的,这可能导致模型直接从历史中推断 ,绕过对更具信息量的潜在动作 at 的需求。
为解决这些问题,我们提出了一个新颖的模型架构。我们的潜在动作模型由逆动力学模型(IDM)和正向动力学模型(FDM)组成。IDM 被训练以根据完整的观测序列 o1:t+1 预测潜在动作 at。我们不是直接使用原始观测,而是首先对输入
![]() 应用随机裁剪 c1。对于 I 的架构,我们首先通过视觉变换器(ViT)(Dosovitskiy et al., 2021[^12],《An image is worth 16x16 words: Transformers for image recognition at scale》)为每一帧提取特征,然后采用时空变换器(ST - transformer)(Bruce et al., 2024[^9],《Genie: Generative interactive environments》; Xu et al., 2021[^13],《Spatial-temporal transformer networks for traffic flow forecasting》)作为主干网络,并使用时间因果掩码。然后使用可学习的读出令牌提取并压缩视觉变化到 N 个令牌中。为了进一步压缩潜在动作中存储的信息,我们对每个令牌应用矢量量化,将其限制在一个大小为 ∣C∣ 的离散码本中。最终,我们得到潜在动作
应用随机裁剪 c1。对于 I 的架构,我们首先通过视觉变换器(ViT)(Dosovitskiy et al., 2021[^12],《An image is worth 16x16 words: Transformers for image recognition at scale》)为每一帧提取特征,然后采用时空变换器(ST - transformer)(Bruce et al., 2024[^9],《Genie: Generative interactive environments》; Xu et al., 2021[^13],《Spatial-temporal transformer networks for traffic flow forecasting》)作为主干网络,并使用时间因果掩码。然后使用可学习的读出令牌提取并压缩视觉变化到 N 个令牌中。为了进一步压缩潜在动作中存储的信息,我们对每个令牌应用矢量量化,将其限制在一个大小为 ∣C∣ 的离散码本中。最终,我们得到潜在动作 ![]() ,其中 D 是每个码的维度。我们将 at 称为潜在动作嵌入,或子任务嵌入,因为它们描述了将观测 ot 转换为下一个观测 ot+1 的信息。
,其中 D 是每个码的维度。我们将 at 称为潜在动作嵌入,或子任务嵌入,因为它们描述了将观测 ot 转换为下一个观测 ot+1 的信息。
对于 FDM ,我们建议使用单帧视觉变换器来重建 ot+1,与以往工作(Schmidt & Jiang, 2023[^10],《Learning to act without actions》)和(Bruce et al., 2024[^9],《Genie: Generative interactive environments》)不同,这些工作基于整个上下文 o1:t 重建下一帧。这种方法减少了模型直接从上下文中预测下一帧的可能性,从而绕过了潜在动作。通过仅基于单帧进行条件预测,它鼓励更多关于潜在动作 at 的信息流动。为了重建 ot+1,我们应用另一个随机裁剪 c2,并预测下一帧为
![]() 。通过使用不同的裁剪 c1 和 c2,模型被鼓励学习在不同轨迹上更具语义不变性的潜在动作。模型通过重建损失
。通过使用不同的裁剪 c1 和 c2,模型被鼓励学习在不同轨迹上更具语义不变性的潜在动作。模型通过重建损失 ![]() 和矢量量化中的承诺损失联合训练
和矢量量化中的承诺损失联合训练
2.2 基础世界模型
我们的基础世界模型是一个连续时间的校正流(Liu et al., 2023b[^14],《Flow straight and fast: Learning to generate and transfer data with rectified flow》; Esser et al., 2024[^15],《Scaling rectified flow transformers for high-resolution image synthesis》),它学习基于历史观测帧![]() 和未来潜在动作
和未来潜在动作![]() 预测未来的帧
预测未来的帧 ![]() 。为了实现这一目标,存在两个关键挑战:
。为了实现这一目标,存在两个关键挑战:
1)生成精确描述状态的逼真帧;
2)通过潜在动作控制生成的帧。
相应地,我们的基础世界模型从预训练的 Open-Sora(Zheng et al., 2024[^16],《Open-sora: Democratizing efficient video production for all》)开始。它由两个组件构成:一个 3D 变分自编码器(VAE),将原始观测编码到空间维度下采样 8 倍、时间维度下采样 4 倍的潜在空间;一个时空校正流变换器(ST-RFT),从文本条件生成潜在内容。为了实现从观测和动作的控制,我们对原始 Open-Sora 进行了两项修改:
1)我们将预训练模型的原始文本输入替换为我们从 LAM 获得的潜在动作 a1:T。对于最后一个动作,应用零填充。对于每一帧,我们将潜在动作映射到一个单独的令牌,并通过交叉注意力机制将其输入到 ST-RFT;
2)我们还使生成过程依赖于 FDM 的输出 ![]() ,它根据输入的潜在动作提供粗粒度的预测。对于
,它根据输入的潜在动作提供粗粒度的预测。对于 ![]() 的条件,我们使用相同的 3D VAE 将其编码到潜在空间,并直接将其添加到噪声输入中。
的条件,我们使用相同的 3D VAE 将其编码到潜在空间,并直接将其添加到噪声输入中。
形式上,校正流(Liu et al., 2023b[^14],《Flow straight and fast: Learning to generate and transfer data with rectified flow》; Albergo & Vanden-Eijnden, 2023[^17],《Building normalizing flows with stochastic interpolants》; Esser et al., 2024[^15],《Scaling rectified flow transformers for high-resolution image synthesis》)旨在直接回归一个向量场,该向量场在噪声分布和数据分布之间生成一个概率路径。
对于 n∈[0,1],我们定义两个分布之间的插值为:
![]()
其中 x0 是干净的数据,x1 是采样的噪声,xn 是噪声数据。在训练期间,我们训练一个向量值神经网络 xθ,使用 L2 损失:
![]()
而不是直接预测条件期望,我们遵循 Liu et al.(2023b[^14],《Flow straight and fast: Learning to generate and transfer data with rectified flow》)的方法,使用神经网络 vθ 参数化速度,并在以下损失上进行训练:
![]()
需要注意的是,我们的基础世界模型可以针对具有不同体现的机器人的不同动作空间进行微调。基础世界模型的微调留作未来工作。
2.3 基础策略模型和低级策略模型
策略模型的训练分为两个阶段。
在第一阶段预训练阶段,以原始观测帧 o1:t 和任务的文本描述 s 作为输入,基础策略模型在每一步预测由潜在动作模型中的 IDM 标记的潜在动作 ![]() )。
)。
这一阶段的训练数据集与潜在动作模型所使用的数据集相同,即包含大规模和多样化来源的视频。
在第二阶段微调阶段,我们在基础策略模型上添加了一个额外的预测组件,以预测真实连续的机器人动作,同时将原始观测以及第一阶段模型预测的潜在动作作为输入。在这一阶段,只有低级策略模型的预测组件在小规模且特定于任务的下游数据集上进行优化,而其他组件则保持冻结。 具体来说,与潜在动作模型类似,基础策略模型的主干也是一个配备有 ViT 图像编码器的 ST - transformer,并且以一个前馈层作为最终预测层。
文本描述 s 通过一个预训练的文本编码器编码为潜在表示,然后与由 ViT 编码器编码的观测表示进行拼接,作为模型的联合输入。 我们使用预测的隐藏输出与潜在动作之间的 L2 距离作为损失函数。给定一个包含 t 个观测的轨迹,训练目标可以表示为:
![]()
, 其中 P(⋅) 表示策略模型。
在第二阶段,我们训练低级策略模型以预测每个潜在动作内的真实连续动作,其中图像 - 目标潜在动作可以被视为通过从初始图像达到目标来定义子任务的表示。低级策略模型也是一个 ST - transformer,带有一个预测层。输入包括文本表示 s、观测 o1:t 以及由基础策略模型预测的潜在动作 ![]() ,它们在 patch 级别上进行拼接,作为模型的一部分输入。由基础策略模型预测的潜在动作
,它们在 patch 级别上进行拼接,作为模型的一部分输入。由基础策略模型预测的潜在动作 ![]() 也作为低级策略模型的子任务嵌入。我们表示每个潜在动作对应 τ 个真实机器人动作,并且潜在动作 at 对应于真实机器人动作
也作为低级策略模型的子任务嵌入。我们表示每个潜在动作对应 τ 个真实机器人动作,并且潜在动作 at 对应于真实机器人动作![]() 。用
。用 ![]() 表示低级策略模型,我们同样使用 L2 距离来训练第二阶段模型:
表示低级策略模型,我们同样使用 L2 距离来训练第二阶段模型:
![]()
其中只有低级策略的参数进行了优化。
3 实验
3.1 数据集
在预训练阶段,我们构建了一个包含多样化领域的大型数据集,包括来自各种体现的机器人数据和大量人类活动视频。
数据混合
对于机器人数据,我们选择了 Open-X Embodiment 数据集(Collaboration et al., 2023[^2],《Open X-Embodiment: Robotic learning datasets and RT-X models》)的一个子集,其中包含单臂末端执行器控制的数据,排除了 RT-1 数据集,用于分布外(OOD)评估。我们遵循 Team et al.(2024[^7],《Octo: An open-source generalist robot policy》)和 Kim et al.(2024[^8],《Openvla: An open-source vision-language-action model》)中的预处理和数据混合权重。总共,我们使用了大约 0.8M 个机器人轨迹。尽管我们的数据集包括真实机器人的数据,但在预训练期间,我们丢弃了相关的动作和本体状态,仅使用图像帧和文本指令。此外,我们还纳入了大规模开放世界视频,带有语言指令,包括人类日常活动的 Something-Something v2(Goyal et al., 2017[^18],《The" something something" video database for learning and evaluating visual common sense》),以及第一人称视频,如 EGTEA(Li et al., 2018[^19],《In the eye of beholder: Joint learning of gaze and actions in first person video》)、Epic Kitchen(Damen et al., 2020[^20],《The epic-kitchens dataset: Collection, challenges and baselines》)和 Ego4D(Grauman et al., 2022[^22],《Ego4d: Around the world in 3,000 hours of egocentric video》; Pramanick et al., 2023[^23],《Egovlpv2: Egocentric video-language pre-training with fusion in the backbone》)。总共,我们从这些数据集中提取了大约 2.0M 个人类活动视频片段,质量较高。总体而言,我们的预训练数据集包含了大约 2.8M 个轨迹和视频片段,每个轨迹都包含一个语言指令和一系列观测。
数据预处理
在实践中,我们发现视频质量对模型性能有很大影响。我们排除了因过度摇晃或快速相机移动而质量低下的视频,并对剩余视频应用了稳定化技术。为了确保潜在动作模型中帧之间的适当变化量,我们为机器人数据集和人类活动视频选择了最佳帧率。 在微调阶段,我们使用 RT-1 数据集,这是一个大规模的真实世界机器人体验数据集。我们从 RT-1 数据集中均匀采样 1% 的剧集用于微调,每个剧集包括一个语言指令、一系列图像观测和一系列低级动作。动作空间是 7 维的,包括机器人臂移动的 3 个维度 ΔPos、机器人臂旋转的 3 个维度 ΔRot 和机器人夹爪动作的 1 个维度 ΔGrp。更多细节请参见附录 A[^1]。
3.2 训练细节
我们首先在预训练数据集上预训练潜在动作模型。然后,我们使用预训练的潜在动作模型在预训练数据集上标记潜在动作,并在标记的数据集上预训练基础策略模型和基础世界模型。最后,我们在 RT-1 数据集上对预训练模型进行微调,以训练低级策略模型。 对于潜在动作模型,我们使用一个包含 N=4 个令牌的码本 codebook ,码本大小为 ∣C∣=32,每个令牌的嵌入大小为 D=128。我们在 RT-1 数据集上对低级策略模型进行微调时,使用子任务长度 。更多训练细节请参见附录 B[^1]。
3.3 定性结果:潜在动作
我们展示了从机器人和人类活动数据集中学到的潜在动作的定性结果。具体来说,我们回答了以下关于学到的潜在动作的问题:
-
相似的潜在动作是否反映了相似的视觉变化?
-
潜在动作是否能够在不同任务和体现(包括人类和机器人)之间编码语义一致的变化?如果是,我们是否能够通过潜在动作在视频之间迁移运动,跨越体现和任务?
-
基础策略模型是否能够正确遵循语言指令以解决任务?
具有相似潜在动作的图像 - 目标对的可视化
我们研究了在机器人操作数据集上,相似的潜在动作是否反映了相似的视觉变化。我们使用 RT-1 数据集,该数据集未包含在潜在动作模型的训练中,作为分布外样本进行评估。我们在图 3 中展示了 RT-1 数据集中图像 - 目标对之间最小欧几里得距离的潜在动作嵌入。
图3:在OOD RT-1数据集中具有相似潜在动作的图像目标对。在每一行中,我们选择最左的图像目标对,然后在潜在动作嵌入中检索3对。对在图像中显示了对的原始任务说明。我们发现每行都以语义共享相似的视觉变化,并且潜在动作在不同的原始语言任务上概括了。

我们观察到,具有相似嵌入的对确实具有相似的视觉变化,并且在语义上具有相似的子任务,例如“打开夹爪”、“向左移动”和“关闭夹爪”。此外,每个子任务出现在不同的原始语言任务中,表明潜在动作被重用,从而促进了模型学习的泛化[^1]。
潜在动作的可控制性
我们展示了潜在动作能够控制不同真实世界场景中多个对象的运动,并且潜在动作的效果可以泛化到不同的任务和体现。特别是,潜在动作的泛化能力使得 IGOR 能够成功地将人类运动视频迁移到机器人运动中,尽管它们在体现上存在很大差异。
-
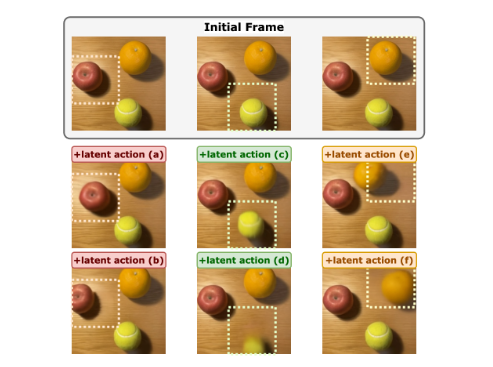
多个对象之间的对象可控制性:我们在图 4 中评估了潜在动作在相同图像中多个对象运动上的可控制性。我们使用基础世界模型对同一原始图像应用 6 种不同的动作,生成后续图像。我们观察到潜在动作模型和基础世界模型学会了控制多个对象中的特定对象的运动[^1]。
图4:多个对象之间潜在作用的可控性。最后两行通过将6种不同的潜在动作应用于初始帧来显示生成的图像。在虚线正方形中突出显示采用不同潜在动作的影响:(a,b)移动苹果,(c,d)移动网球,(e,f)移动橙色
-
跨越体现和任务的对象可控制性:我们在图 2 中展示了在不同场景设置中,包括体现和任务,潜在动作的语义一致性。
-
我们使用真实世界操作视频中的图像 - 目标对生成潜在动作,并将相同的动作集应用于其他具有基础世界模型的图像,以生成后续视频。结果表明,潜在动作在不同任务和体现之间具有语义一致性,包括人类和机器人。通过将从人类演示中提取的潜在动作应用于机器人臂,我们生成了机器人臂运动的视频。仅使用一个演示,机器人臂就能够成功地迁移人类行为,这为少样本人类到机器人的迁移和控制开辟了新的可能性[^1]。
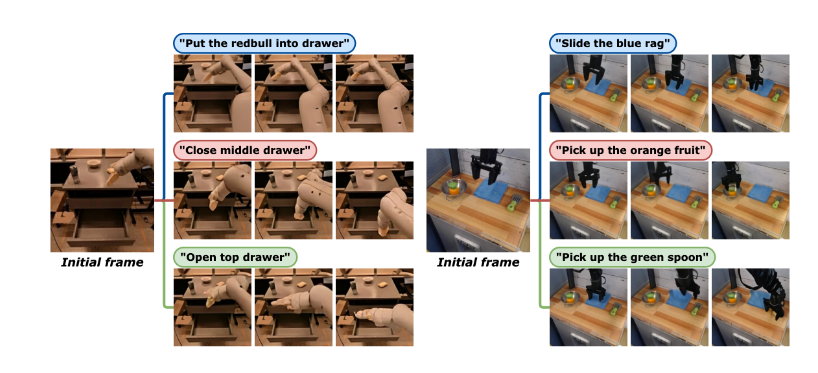
多样化指令下的反事实视频生成
我们分析了基础策略模型是否能够遵循人类指令。为此,我们使用基础世界模型从视觉上解释潜在动作的效果。从单一初始图像出发,基础策略和世界模型可以仅使用潜在动作联合生成遵循多样化指令的视频中的多样化行为。我们在图 5 中展示了从 RT-1 和 Bridge 数据集中的初始图像以及手动编写的指令生成的视频片段。结果表明,基础策略模型能够正确遵循不同的语言指令以解决任务[^1]。
图5:按照同一初始图像中的3个不同说明,通过基础策略和世界模型共同生成图像序列。
3.4 定量结果
在 SIMPLER 中的 Google Robot 任务评估
我们在 SIMPLER 模拟器下的低数据量情况下,使用仅从大规模 RT-1 数据集中采样的 1% 数据对低级策略学习阶段进行评估,评估我们的基于 IGOR 的训练框架在 Google 机器人任务上的性能[^1]。
-
评估设置:我们在 RT-1 数据集上对不同模型在相同数量的数据上进行微调后,测试它们控制 Google 机器人遵循语言任务的能力,其中所有机器人都使用低级末端执行器控制动作,并且观测为 RGB 图像。我们在三个任务上评估成功率:“拿起可乐罐”、“靠近移动”和“打开 / 关闭抽屉”[^1]。
-
基线方法:我们将我们的方法与具有相同低级策略模型架构的 ST - Transformer 进行比较,但不将潜在动作嵌入与观测特征嵌入进行拼接[^1]。
-
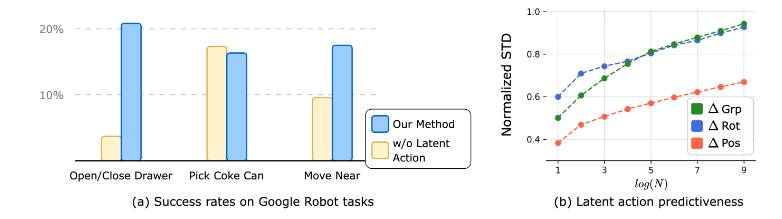
结果:我们在图 6(a)中展示了不同方法的成功率。从图中可以看出,IGOR 的成功率高于或等于从头开始训练的模型,显示出学到的潜在动作对真实机器人动作的泛化能力[^1]。
潜在动作对机器人动作的预测性
我们分析了我们学到的潜在动作是否能够预测真实的机器人动作。在 RT-1 数据集上,我们随机采样了 M=15,000 对图像,并计算它们的潜在动作嵌入。对于每对图像,我们在 RT-1 数据集中找到 N 个最近邻的图像对,这些图像对的潜在动作嵌入最接近,并计算 N 个邻居在每个动作维度上的真实机器人动作的标准差,相对于整个 RT-1 数据集中每个维度上机器人动作的标准差进行归一化。通过改变 N,我们评估更接近的潜在动作是否对应更相似的下游动作[^1]。
结果如图 6(b)所示。较小的 N 导致较低的归一化标准差,并且所有归一化标准差都低于 1.0,这表明潜在动作能够预测真实的机器人动作,包括机器人的移动、旋转和夹爪动作。此外,结果还表明潜在动作对机器人移动的预测性高于旋转和夹爪动作,这表明 IGOR 学习到的动作空间更多地反映了机器人移动的信息,而不是机器人臂的旋转和夹爪动作[^1]。
图6:(a)。 igor的成功率和在更简单的模拟器下从scratch methods上培训了从刮擦方法培训的低级政策,对RT-1的1%数据进行了填充。 (b)。潜在行动对机器人动作的预测。 X轴:log(n),其中n是潜在动作嵌入中最近的邻居数。 Y轴:相对于动作动作(橙色),旋转动作(蓝色)和握把动作(绿色)的归一化标准偏差。
3.5 消融研究
我们提供了关于潜在动作模型预训练数据集的额外消融研究,结果表明使用机器人和人类活动数据集的混合数据集有助于潜在动作模型的泛化。详细的消融研究结果在附录 C[^1] 中提供。
4 相关工作
基础代理机器人
开放式的任务不可知训练和高容量神经网络架构被认为是基础模型成功的关键。在这一背景下,提出了一系列作为机器人基础策略模型的通用代理(Brohan et al., 2022[^4],《Rt-1: Robotics transformer for real-world control at scale》);Bousmalis et al., 2023[^5],《Robocat: A self-improving generalist agent for robotic manipulation》);Brohan et al., 2023[^6],《Rt-2: Vision-language-action models transfer web knowledge to robotic control》);Team et al., 2024[^7],《Octo: An open-source generalist robot policy》);Kim et al., 2024[^8],《Openvla: An open-source vision-language-action model》)。RT-1(Brohan et al., 2022[^4],《Rt-1: Robotics transformer for real-world control at scale》)贡献了一个大规模多任务数据集和一个机器人变换器架构,促进了跨多个任务的泛化评估。RoboCat 基于 Gato(Reed et al., 2022[^14],《A generalist agent》),进一步实现了多体现泛化。RT-2 突出了利用互联网规模数据训练的视觉 - 语言模型的重要性(Brohan et al., 2023[^6],《Rt-2: Vision-language-action models transfer web knowledge to robotic control》)。Octo(Team et al., 2024[^7],《Octo: An open-source generalist robot policy》)和 OpenVLA(Kim et al., 2024[^8],《Openvla: An open-source vision-language-action model》)可以被视为 RoboCat 和 RT-2 的开放版本,分别有一些额外的技术贡献。IGOR 与 RT-2 和 OpenVLA 类似,因为我们都在利用互联网规模的数据。不同之处在于,我们使用人类 / 机器人执行具身 AI 任务的视频数据(带文本标签),而他们使用文本数据和视觉问答数据来训练视觉语言模型。据我们所知,我们提出了第一个在子任务(即潜在动作)层面进行决策的基础策略模型[^1]。
图像 - 目标视觉变化跟踪
在具身 AI 中,跟踪视觉变化并建立图像与其目标状态之间的对应关系对于动态视觉理解至关重要。SiamMAE(Gupta et al., 2023[^12],《Siamese masked autoencoders》)提出使用图像和目标的孪生编码器来学习视觉对应关系。Voltron(Karamcheti et al., 2023[^24],《Language-driven representation learning on image-goal pairs》)介绍了在图像 - 目标对上进行语言引导的视觉表示学习。FLOWRETRIEVAL(Lin et al., 2024[^25],《Flowretrieval: Flow-guided data retrieval for few-shot imitation learning》)和 AVDC(Ko et al., 2023[^26],《Learning to act from actionless videos through dense correspondences》)利用图像和目标之间的光流来捕捉视觉变化和对应关系,而 Video-LaVIT(Jin et al., 2024[^27],《Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization》)利用运动向量。iVideoGPT(Wu et al., 2024[^28],《Ivideogpt: Interactive videogpts are scalable world models》)提出使用图像条件目标表示作为状态表示,在世界模型中进行预测。VPT(Baker et al., 2022[^29],《Video pretraining (vpt): Learning to act by watching unlabeled online videos》)提出使用逆动力学模型从交互数据中恢复视频中的潜在动作,以预测真实动作。也许与我们的方法最相似的是 LAPO(Schmidt & Jiang, 2023[^10],《Learning to act without actions》)和 Genie(Bruce et al., 2024[^9],《Genie: Generative interactive environments》)。这两项工作主要关注 2D 平台游戏,其中每个潜在动作对应一个特定的控制按钮。相比之下,我们旨在开发一个更具通用性的模型,以处理开放世界场景的显著复杂性,其中潜在动作可能不对应于任何特定的基础动作[^1]。
具身 AI 中的视频生成
视频生成是与具身 AI 密切相关的另一个研究主题。已经有人提出视频可以被视为现实世界决策的“新语言”(Yang et al., 2024b[^29],《Video as the new language for real-world decision making》)。许多世界模型的工作都建立在视频生成技术之上(Bruce et al., 2024[^9],《Genie: Generative interactive environments》; Wu et al., 2024[^28],《Ivideogpt: Interactive videogpts are scalable world models》; Hu et al., 2023[^30],《Gaia-1: A generative world model for autonomous driving》; Yang et al., 2024a[^31],《Learning interactive real-world simulators》; Xiang et al., 2024[^32],《Pandora: Towards general world model with natural language actions and video states》)。一些文本到视频的作品声称是现实世界的模拟器,例如 Sora(Brooks et al., 2024[^33],《Video generation models as world simulators》)和 WorldDreamer(Wang et al., 2024[^34],《Worlddreamer: Towards general world models for video generation via predicting masked tokens》)。Unipi(Du et al., 2023[^35],《Learning universal policies via text-guided video generation》)提出首先预测下一个目标状态,然后使用逆动力学模型推断真实机器人动作。相比之下,我们的基础策略模型首先预测潜在动作,该动作可以指定目标状态,然后使用潜在动作实现子任务级别的泛化。我们认为,与原始图像空间相比,前向预测在潜在动作空间中具有几个优势。例如,我们可以执行图像 - 目标表示的子任务理解,并且压缩后的潜在动作可能比整个图像更容易预测[^1]。
预训练视觉表示
预训练视觉表示旨在以自监督学习的方式训练图像 / 视频的表示(He et al., 2021[^36],《Masked autoencoders are scalable vision learners》; Xiao et al., 2022[^37],《Masked visual pre-training for motor control》; Radosavovic et al., 2022[^38],《Real-world robot learning with masked visual pre-training》; Majumdar et al., 2023[^39],《Where are we in the search for an artificial visual cortex for embodied intelligence?》; Radford et al., 2021[^40],《Learning transferable visual models from natural language supervision》; Nair et al., 2022[^41],《R3m: A universal visual representation for robot manipulation》; Ma et al., 2023[^42],《Vip: Towards universal visual reward and representation via value-implicit pre-training》; Oquab et al., 2023[^43],《Dinov2: Learning robust visual features without supervision》; Darcet et al., 2023[^44],《Vision transformers need registers》; Kirillov et al., 2023[^45],《Segment anything》; Assran et al., 2023[^46],《Self-supervised learning from images with a joint-embedding predictive architecture》; Bardes et al., 2024[^47],《Revisiting feature prediction for learning visual representations from video》),并且已被证明对具身 AI 中的状态理解非常有效。相比之下,IGOR 学习图像 - 目标表示用于子任务理解,我们相信这是另一个关键构建块,可能会显著增强具身 AI 中的泛化能力[^1]。
5 结论、局限性和未来工作
在本文中,我们提出了 IGOR,这是一个新颖的训练框架,迈出了学习人类和机器人在各种具身 AI 任务中统一动作空间的第一步。 从定性角度来看,我们证明了:
-
IGOR 学习了相似的表示,用于具有相似视觉变化的图像对[^1]。
-
学习到的潜在动作能够控制给定当前图像的下一个状态[^1]。
-
基础世界模型获取了关于物体及其可能运动的知识[^1]。
-
基础策略模型学会了遵循不同状态下的指令[^1]。
从定量角度来看,我们展示了:
-
在 RT-1 数据集上,具有相似潜在动作的图像 - 目标对与相似的低级机器人动作相关联[^1]。
-
IGOR 框架改进了策略学习,这可能是由于其能够通过利用互联网规模的数据预测下一个子任务,从而实现子任务级别的泛化[^1]。
IGOR 框架存在以下局限性:
我们无法区分由代理、其他代理(例如狗)或相机摇晃引起的视觉变化。为了解决这一问题,我们减少了相机摇晃的影响,并仅使用没有其他代理出现在视野中的第一人称视频[^1]。与其他表示学习方法一样,扩大数据集和模型规模是最直接且有效的方法。为了便于使用更多数据,将图像处理方法(如目标分割)与 IGOR 结合将是未来工作的一部分[^1]。为了更好地应用于具身 AI,基础世界模型也可以针对真实世界场景进行调整,以及进行其他改进,例如将潜在动作模型适应于多代理场景[^1]。
附录
A 数据集
我们在表 1 中展示了用于预训练的数据集。这些数据集总共包括大约 80 万个机器人轨迹和 200 万个经过过滤的人类活动视频剪辑。机器人数据比率为 来自(Team et al., 2024)

数据过滤
我们观察到,视频质量会显着影响动作模型,特别是对于人类活动视频。视频中过度的摇摆不定会引入与代理商行动无关的连续帧之间的视觉变化。我们通过视频计算摄像头运动,并过滤大约40%的开放世界视频数据。对于其余数据,我们进一步稳定视频。尽管我们仅保留了Open-World视频数据的60%,但我们发现动作模型急剧改善
B训练细节
B.1潜在动作模型训练
潜在的动作模型使用配备frozen DINO-v2 pretrained ViT image encoder的ST transformer。潜在的动作模型使用的补丁大小为14,而n = 4令牌和大小| c |=32的代码簿使用。,每个嵌入尺寸为d = 128。我们训练具有批量尺寸B = 512的潜在动作模型,140k步骤的训练迭代,学习速率为1.5E -4,用Adam Optimizer进行了训练。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









