






基于对比预测编码学习基于 Transformer 的世界模型
本文作为会议论文发表于 2025 年 ICLR(International Conference on Learning Representations,国际学习表征会议)
马克西姆・布尔奇、拉杜・蒂莫夫特
德国维尔茨堡大学计算机视觉实验室、CAIDAS 和 IFI(Institute of Computer Science,计算机科学研究所)
maxime.burchi@uni-wuerzburg.de
摘要
DreamerV3 算法最近通过学习基于循环神经网络(Recurrent Neural Networks, RNNs)的精确世界模型,在各种环境领域取得了显著性能。随着基于模型的强化学习算法的成功,以及 Transformer 架构因其卓越的训练效率和良好的扩展性被迅速采用,诸如 STORM(Stochastic Transformer-based wORld Model,随机 Transformer 世界模型)等近期研究提出使用掩码自注意力机制的 Transformer 世界模型,取代基于 RNN 的世界模型。然而,尽管这些方法提高了训练效率,但与 Dreamer 算法相比,它们对性能的提升仍然有限,难以学习到具有竞争力的基于 Transformer 的世界模型。在这项工作中,我们表明先前方法中采用的下一状态预测目标不足以充分利用 Transformer 的表征能力。我们提出通过引入 TWISTER(Transformer-based World model wIth contraSTivE Representations,基于 Transformer 且具有对比表征的世界模型)来扩展世界模型的预测时间跨度,这是一种使用动作条件对比预测编码(action-conditioned Contrastive Predictive Coding)来学习高级时间特征表征并提升智能体性能的世界模型。TWISTER 在 Atari 100k 基准测试中达到了 162% 的人类归一化平均得分,在不使用前瞻搜索 look-ahead search 的最先进方法中创下了新纪录。我们将代码发布在GitHub - burchim/TWISTER: Learning Transformer-based World Models with Contrastive Predictive Coding. ICLR 2025。
1. 引言
近年来,深度强化学习(Deep Reinforcement Learning, RL)算法取得了显著突破。硬件系统计算能力的不断提升,使研究人员能够取得重大进展,他们使用深度神经网络(LeCun 等人,2015)作为函数逼近器,从图像(Mnih 等人,2013)或视频(Hafner 等人,2020)等高维观测中训练强大的智能体。随着卷积神经网络(Convolutional Neural Networks, CNNs)(LeCun 等人,1989)因其高效的模式识别能力在计算机视觉领域迅速普及,神经网络被应用于视觉强化学习问题,并在诸如 Atari 游戏(Mnih 等人,2015;Hessel 等人,2018)、围棋(Silver 等人,2018;Schrittwieser 等人,2020)、星际争霸 II(Vinyals 等人,2019)以及最近的我的世界(Baker 等人,2022;Hafner 等人,2023)等具有挑战性且视觉复杂的领域中,达到了人类甚至超越人类的性能。
在神经网络成功解决强化学习问题之后,基于模型的方法被提出,该方法通过梯度反向传播学习世界模型,以减少与环境进行必要交互的次数,从而获得强大的结果(Kaiser 等人,2020;Hafner 等人,2020;2021;2023;Schrittwieser 等人,2020)。世界模型(Sutton,1991;Ha 和 Schmidhuber,2018)将智能体的经验总结为一个预测模型,该模型可用于替代真实环境来学习复杂行为。拥有一个环境模型使智能体能够并行模拟多个合理的轨迹,通过规划提高泛化能力、样本效率和决策能力。
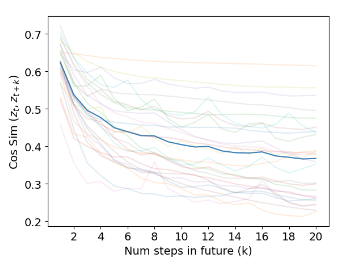
世界模型的设计通常倾向于循环神经网络(RNNs)(Hafner 等人,2019),因为它们能够有效地对时间关系进行建模。随着 Dreamer 算法(Hafner 等人,2020)的成功,以及 Transformer 架构(Vaswani 等人,2017)与 RNNs 相比具有卓越的训练效率和良好的扩展性,研究工作提出使用带有掩码自注意力机制的 Transformer 世界模型,取代 Dreamer 算法中基于单层循环的世界模型(Chen 等人,2022;Micheli 等人,2023;Robine 等人,2023)。然而,尽管这些方法提高了训练效率,但与 Dreamer 算法相比,它们对性能的影响仍然有限,难以学习到具有竞争力的基于 Transformer 的世界模型。Zhang 等人(2024)认为,这些发现可能归因于连续视频帧之间的细微差异。与神经语言建模(Kaplan 等人,2020)等其他领域相比,在潜在空间中预测下一视频帧的任务可能不需要复杂的模型,在神经语言建模中,对过去上下文的深刻理解对于准确预测下一个标记至关重要。如图 2 所示,世界模型相邻潜在状态之间的余弦相似度非常高,这使得世界模型预测下一状态比预测更远的状态相对更容易。这些发现促使我们通过扩展预测时间跨度来使世界模型目标复杂化,以学习更高质量的特征表征并提升智能体性能。
(图 1:近期发表的基于模型的方法在 Atari 100k 基准测试中的人类归一化平均和中位数得分。TWISTER 优于其他基于模型的方法。TWM(Transformer-based World Model,基于 Transformer 的世界模型)、IRIS(Micheli 等人,2023 提出的一种世界模型)、STORM 和 Δ -IRIS(Micheli 等人,2024 提出的一种世界模型)采用基于 Transformer 的世界模型,而 DreamerV3 使用基于 RNN 的模型。)
(图 2:TWISTER 潜在状态与未来状态
之间的余弦相似度,该相似度是在 Atari 100k 基准测试的所有 26 款游戏上进行聚合的。我们展示了 5 个随机种子的平均相似度。)
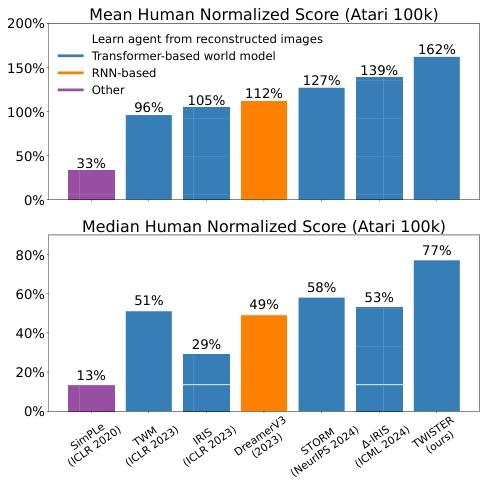
在这项工作中,我们表明先前方法中采用的下一潜在状态预测目标不足以充分利用 Transformer 的表征能力。我们引入 TWISTER,这是一种基于 Transformer 模型的强化学习算法,它使用动作条件对比预测编码(AC-CPC,action-conditioned Contrastive Predictive Coding)来学习高级时间特征表征并提升智能体性能。CPC(Contrastive Predictive Coding,对比预测编码)(Oord 等人,2018)最初作为预训练前置任务应用于语音、图像和文本领域。它在 DeepMind Lab 任务(Beattie 等人,2016)中也显示出有前景的结果,被用作 A3C(Asynchronous Advantage Actor-Critic,异步优势演员 - 评论家算法)智能体(Mnih 等人,2016)的辅助损失。受这些发现的启发,我们将 CPC 目标应用于基于模型的强化学习,通过使 CPC 预测依赖于未来动作序列。这种方法使世界模型能够使用对比学习准确预测未来时间步的特征表征。如图 1 所示,TWISTER 在常用的 Atari 100k 基准测试(Kaiser 等人,2020)中,在不使用前瞻搜索的最先进方法中创下了新纪录,实现了 162% 的人类归一化平均得分和 77% 的中位数得分。
2. 相关工作
2.1 基于模型的强化学习
基于模型的强化学习方法使用环境模型来模拟智能体的轨迹,通过规划提高泛化能力、样本效率和决策能力。随着深度神经网络在学习函数逼近方面的成功,研究人员提出使用梯度反向传播来学习世界模型。早期的工作主要集中在简单环境,如本体感受任务(Silver 等人,2017;Henaff 等人,2017;Wang 等人,2019;Wang 和 Ba,2020),使用低维观测,而最近的工作则侧重于从图像等高维观测中学习世界模型(Kaiser 等人,2020;Hafner 等人,2019)。
最早应用于图像数据的基于模型的算法之一是 SimPLe(Kaiser 等人,2020),它提出在像素空间中使用卷积自动编码器为 Atari 游戏学习一个世界模型。该世界模型学习根据先前的观测帧和选择的动作预测下一帧和环境奖励。然后,它用于从重建图像和预测奖励中训练近端策略优化(Proximal Policy Optimization,PPO)智能体(Schulman 等人,2017)。与此同时,PlaNet(Hafner 等人,2019)引入了一种使用门控循环单元(Gated Recurrent Unit,GRU)(Cho 等人,2014)的循环状态空间模型(Recurrent State-Space Model,RSSM),在潜在空间中学习世界模型,并使用模型预测控制进行规划。PlaNet 学习一个带有像素重建损失的卷积变分自动编码器(variational autoencoder,VAE)(Kingma 和 Welling,2013),将观测编码为随机状态表征。RSSM 学习根据先前的随机和确定性循环状态预测下一个随机状态和环境奖励。随着 PlaNet 在 DeepMind 视觉控制任务(Tassa 等人,2018)上的成功,Dreamer(Hafner 等人,2020)通过从世界模型表征中学习一个演员网络和一个价值网络改进了该算法。DreamerV2(Hafner 等人,2021)将该算法应用于 Atari 游戏,在世界模型中使用具有直通梯度(Bengio 等人,2013)的分类潜在状态,而不是具有重参数化梯度(Kingma 和 Welling,2013)的高斯潜在状态,以提高性能。DreamerV3(Hafner 等人,2023)通过一组架构更改,使用相同的超参数掌握了不同领域,以稳定跨任务的学习。该智能体对奖励和价值函数使用对称对数(symlog)预测,以解决不同领域之间的尺度差异问题。网络还采用层归一化(Ba 等人,2016)来提高鲁棒性和性能,同时扩展到更大的模型规模。它通过使用回报百分位数的指数移动平均(Exponential Moving Average,EMA)对回报和价值函数进行归一化,来稳定策略学习。通过这些修改,DreamerV3 在广泛的基准测试中优于专门的无模型和基于模型的算法。与 Dreamer 系列工作并行,Schrittwieser 等人(2020)提出了 MuZero,这是一种基于模型的算法,它将蒙特卡罗树搜索(Monte-Carlo Tree Search,MCTS)(Coulom,2006)与强大的世界模型相结合,在诸如国际象棋、将棋和围棋等精确规划任务中实现了超越人类的性能。该模型通过递归展开 K 步并预测与规划相关的环境量来学习。MCTS 算法使用学习到的模型模拟环境轨迹,并在根节点上输出动作访问分布。这个可能比神经网络策略更好的策略被用于训练策略网络。最近,Ye 等人(2021)提出了 EfficientZero,这是 MuZero 算法的一个样本高效版本,它使用自监督学习来学习一个时间一致的环境模型,并在 Atari 游戏上取得了强大的性能。
2.2 基于 Transformer 的世界模型
近期的工作提出使用基于 Transformer 的架构取代基于 RNN 的世界模型,利用自注意力机制处理过去的上下文信息。TransDreamer(Chen 等人,2022)使用掩码自注意力机制的 Transformer 状态空间模型(Transformer State-Space Model,TSSM)取代了 DreamerV3 的 RSSM,以想象未来的轨迹。该智能体在需要长期记忆和推理的隐藏顺序发现任务中进行评估。他们还在一些视觉 DeepMind 控制任务(Tassa 等人,2018)和 Atari 任务(Bellemare 等人,2013)上进行了实验,显示出与 DreamerV2 相当的性能。TWM(Robine 等人,2023)(基于 Transformer 的世界模型)提出了类似的方法,将状态、动作和奖励编码为自回归 Transformer 的不同连续输入令牌。解码器在重建输入图像时也不使用世界模型的隐藏状态,在图像重建中丢弃了过去上下文的时间信息。最近,STORM(Zhang 等人,2024)(随机 Transformer 世界模型)在 Atari 100k 基准测试中取得了与 DreamerV3 相当的结果,且训练效率更高。STORM 提出将状态和动作融合为 Transformer 网络的单个令牌,与 TWM 使用不同令牌的方法相比,这带来了更好的训练效率和最先进的性能。
另一类工作侧重于设计基于 Transformer 的世界模型,以从像素空间中重建的轨迹训练智能体。与 SimPLe 类似,智能体的策略和价值函数是从图像重建中训练的,而不是从世界模型的隐藏状态表征中训练。这需要为策略和价值函数学习辅助编码器网络。与从世界模型表征中学习智能体的受 Dreamer 启发的工作不同,这些方法还需要准确的图像重建才能有效地训练智能体。IRIS(Micheli 等人,2023)首先提出了一种世界模型,该模型由一个 VQ-VAE(Van Den Oord 等人,2017)将输入图像转换为离散令牌,以及一个自回归 Transformer 来预测未来令牌。IRIS 在 Atari 100k 基准测试(Kaiser 等人,2020)中进行了评估,在低数据条件下显示出有前景的性能。最近,Micheli 等人(2024)提出了 Δ -IRIS,使用先前的动作和图像作为编码器和解码器的条件,对时间步之间的随机增量进行编码。这提高了 VQ-VAE 的压缩比和图像重建能力,在 Crafter(Hafner,2021)基准测试中取得了最先进的性能,并在 Atari 100k 上取得了更好的结果。
表 1 比较了近期在潜在空间中学习世界模型的基于模型的方法与我们提出的方法的架构细节。与先前基于 Transformer 的方法类似,我们从编码器随机状态![]() 而不是
而不是![]() 重建图像观测,这防止了世界模型使用时间信息来促进重建。Transformer 网络使用相对位置编码(Dai 等人,2019),这简化了在想象和评估过程中世界模型的使用。绝对位置编码要求 Transformer 网络在当前位置大于训练期间看到的位置时,使用调整后的位置编码重新处理过去的潜在状态。我们还在世界模型训练阶段将智能体状态作为预测器网络的输入,以使演员 - 评论家学习更加直接。
重建图像观测,这防止了世界模型使用时间信息来促进重建。Transformer 网络使用相对位置编码(Dai 等人,2019),这简化了在想象和评估过程中世界模型的使用。绝对位置编码要求 Transformer 网络在当前位置大于训练期间看到的位置时,使用调整后的位置编码重新处理过去的潜在状态。我们还在世界模型训练阶段将智能体状态作为预测器网络的输入,以使演员 - 评论家学习更加直接。
(表 1:TWISTER 与其他近期在潜在空间中学习世界模型的基于模型的方法的比较。令牌指自回归世界模型使用的令牌。
是图像表征,而隐藏状态
是携带历史信息的世界模型隐藏状态。)
2.3 对比预测编码
对比预测编码(Contrastive Predictive Coding,CPC)由 Oord 等人(2018)提出,是一种基于对比学习的自回归模型表示学习方法。CPC 将时间信号编码为隐藏表征,并训练一个自回归模型,使用基于噪声对比估计(Noise-Contrastive Estimation,Gutmann 和 Hyvärinen,2010)的 InfoNCE 损失,最大化自回归模型输出特征与未来编码表征之间的互信息。CPC 能够学习有用的表征,在四个不同领域取得了强大的性能:语音音素分类、图像分类、文本分类任务,以及在 DeepMind Lab 3D 环境(Beattie 等人,2016)中的强化学习。虽然 CPC 作为预训练前置任务应用于语音、图像和文本领域,但它在 DeepMind Lab 任务中作为 A3C(Mnih 等人,2016)智能体的辅助损失显示出有前景的结果。在这项工作中,我们提议将 CPC 应用于基于模型的强化学习。我们引入动作条件 CPC(AC-CPC,action-conditioned CPC),使 CPC 预测依赖于未来动作序列,以帮助世界模型做出更准确的预测并学习更高质量的表征。我们将在 3.1 节更详细地描述我们对动作条件 CPC 的使用。
3. 方法
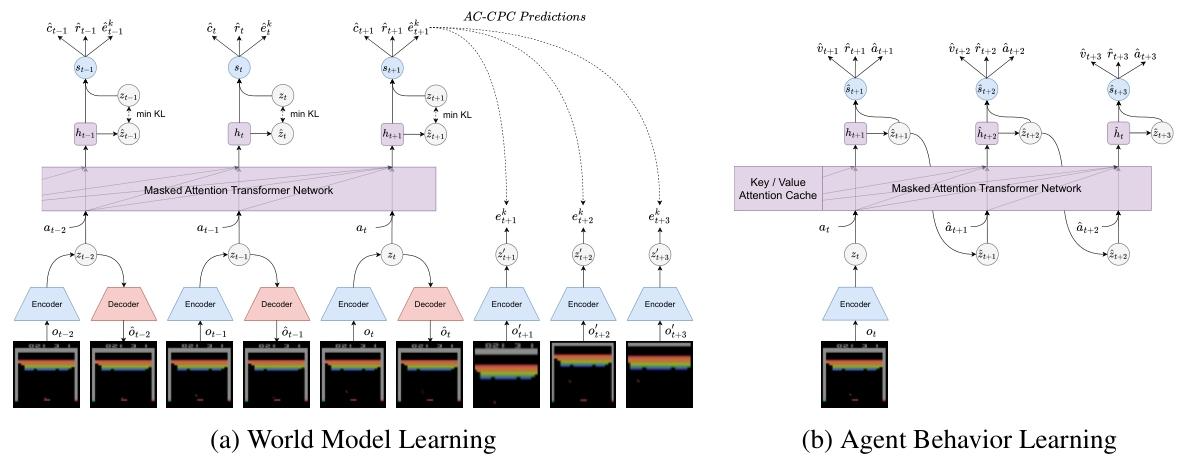
我们引入 TWISTER,这是一种基于 Transformer 模型的强化学习算法,使用动作条件对比预测编码来学习高级特征表征并提升智能体性能。TWISTER 由三个主要的神经网络组成:一个世界模型、一个演员网络和一个评论家网络。世界模型学习将图像观测转换为离散随机状态,并模拟环境以生成想象的轨迹。演员网络和评论家网络在潜在空间中使用世界模型生成的想象轨迹进行训练,以选择最大化未来奖励预期总和的动作。这三个网络使用重放缓冲区(replay buffer)同时训练,重放缓冲区对训练期间收集的过去经验序列进行采样。本节描述了我们提出的具有对比表征的基于 Transformer 的世界模型的架构和优化过程。与先前的方法类似,我们还详细介绍了在潜在空间中进行的评论家网络和演员网络的学习过程。图 3 展示了使用 AC-CPC 训练的基于 Transformer 的世界模型的概述,它还说明了在智能体行为学习阶段进行的想象过程。
(图 3:具有对比表征的基于 Transformer 的世界模型。世界模型通过最大化模型状态与从图像观测增强视图中获得的未来随机状态 之间的互信息,学习时间特征表征。编码器网络将图像观测转换为随机状态,解码器网络从学习重建图像,而掩码注意力 Transformer 网络根据选定的动作预测下一个情节延续、奖励和随机状态。)
3.1 世界模型学习
与先前的工作(Hafner 等人,2023;Robine 等人,2023;Zhang 等人,2024)一致,我们通过使用具有分类潜在变量的卷积 VAE 将输入图像观测![]() 编码为隐藏表征,在潜在空间中学习世界模型。隐藏表征被线性投影到包含 32 个类别、每个类别有 32 个类别的分类分布 logits 上,从中采样得到离散随机状态
编码为隐藏表征,在潜在空间中学习世界模型。隐藏表征被线性投影到包含 32 个类别、每个类别有 32 个类别的分类分布 logits 上,从中采样得到离散随机状态 。世界模型被实现为一个 Transformer 状态空间模型(TSSM)(Chen 等人,2022),使用掩码自注意力机制根据先前状态
![]() 和动作
和动作![]() 预测下一个随机状态
预测下一个随机状态![]() 。
。
Transformer 网络输出隐藏状态![]() ,它与随机状态连接形成模型状态
,它与随机状态连接形成模型状态![]() 。世界模型使用简单的多层感知器(Multi Layer Perceptron,MLP)网络预测环境奖励
。世界模型使用简单的多层感知器(Multi Layer Perceptron,MLP)网络预测环境奖励 ![]() 、情节延续 episode continuation
、情节延续 episode continuation ![]() 和 AC-CPC 特征
和 AC-CPC 特征 ![]() 。可训练的世界模型组件如下:
。可训练的世界模型组件如下:

Transformer 状态空间模型
我们使用带有相对位置编码(Dai 等人,2019)的掩码自注意力机制训练一个自回归 Transformer 网络。在训练、探索和评估过程中,为前一段或状态计算的隐藏状态序列会被缓存,以便在模型处理下一个状态时作为扩展上下文重复使用。这种编码和缓存机制使世界模型能够从任何状态想象未来轨迹,无需使用调整后的位置编码重新处理潜在状态。
世界模型损失
给定一个输入批次,包含 B 个长度为 T 的图像观测序列 ![]() 、动作
、动作![]() 、奖励
、奖励![]() 和情节延续标志
和情节延续标志 ![]() ,世界模型参数(
,世界模型参数()通过最小化以下损失函数进行优化:
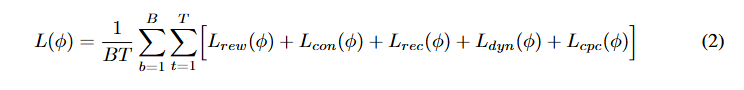
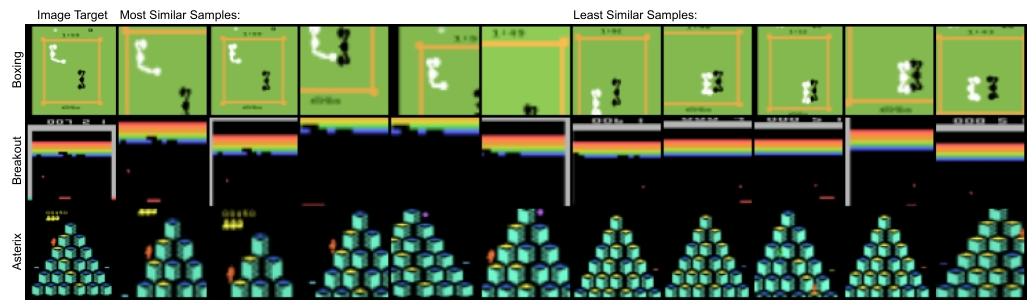
(图 4:世界模型进行的 AC-CPC 预测。我们展示了未增强的目标正样本,以及在增强图像视图批次中预测的最相似和最不相似样本。我们观察到,TWISTER 学会了利用诸如球的位置、游戏得分或智能体动作等观测细节,识别与未来目标状态最相似和最不相似的样本。AC-CPC 要求智能体关注观测细节,以准确预测未来样本,从而避免了重建损失忽略小物体的常见失败情况。)
![]() 用于训练世界模型预测环境奖励和情节延续标志,这些在行为学习阶段用于计算想象轨迹的回报。我们采用 DreamerV3(Hafner 等人,2023)中的对称对数交叉熵损失 symlog cross-entropy loss,它将奖励缩放并转换为独热编码目标,以确保在不同奖励幅度的游戏中稳健学习。重建损失
用于训练世界模型预测环境奖励和情节延续标志,这些在行为学习阶段用于计算想象轨迹的回报。我们采用 DreamerV3(Hafner 等人,2023)中的对称对数交叉熵损失 symlog cross-entropy loss,它将奖励缩放并转换为独热编码目标,以确保在不同奖励幅度的游戏中稳健学习。重建损失![]() 通过重建输入视觉观测
通过重建输入视觉观测![]() ,训练分类 VAE 为世界模型学习随机表征
,训练分类 VAE 为世界模型学习随机表征![]() :
:
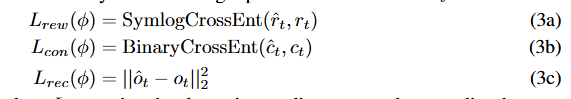
世界模型动力学损失![]() 训练动力学预测器网络,通过最小化预测器输出分布
训练动力学预测器网络,通过最小化预测器输出分布![]() 与下一个编码器表征
与下一个编码器表征![]() 之间的库尔贝克 - 莱布勒(Kullback–Leibler,KL)散度,从 Transformer 隐藏状态预测下一个随机状态表征。我们还添加了一个正则化项,以避免 KL 损失出现尖峰,并通过训练编码器表征使其更具可预测性来稳定学习。两个损失项都使用停止梯度操作符
之间的库尔贝克 - 莱布勒(Kullback–Leibler,KL)散度,从 Transformer 隐藏状态预测下一个随机状态表征。我们还添加了一个正则化项,以避免 KL 损失出现尖峰,并通过训练编码器表征使其更具可预测性来稳定学习。两个损失项都使用停止梯度操作符![]() 来防止目标的梯度反向传播,并分别用损失权重
来防止目标的梯度反向传播,并分别用损失权重![]() 进行缩放:
进行缩放:
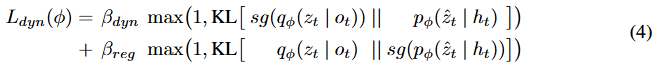
Transformer 网络使用动作条件对比预测编码学习特征表征。通过最大化模型状态![]() 与从图像观测增强视图中获得的未来随机状态
与从图像观测增强视图中获得的未来随机状态![]() 之间的互信息来学习这些表征。我们采用一种简单策略生成负样本:给定包含一个正样本的增强随机状态序列批次
之间的互信息来学习这些表征。我们采用一种简单策略生成负样本:给定包含一个正样本的增强随机状态序列批次![]() ,我们将其他
,我们将其他![]() 个样本视为负样本。世界模型使用 InfoNCE 学习区分正样本和负样本:
个样本视为负样本。世界模型使用 InfoNCE 学习区分正样本和负样本:
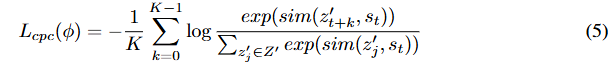
世界模型在增强样本批次中学习预测 K=10 个未来随机状态。我们将相似度计算为点积:![]() ,为每个步骤学习两个 MLP 网络
,为每个步骤学习两个 MLP 网络![]() 。与最初的 CPC 论文不同,该论文在连续特征状态上进行实验,我们的世界模型使用离散潜在状态。这需要学习一个表征网络
。与最初的 CPC 论文不同,该论文在连续特征状态上进行实验,我们的世界模型使用离散潜在状态。这需要学习一个表征网络![]() ,将离散化的随机状态
,将离散化的随机状态![]() 投影到对比特征表征
投影到对比特征表征![]() 。AC-CPC 预测器
。AC-CPC 预测器![]() 使用未来动作的连接序列
使用未来动作的连接序列![]() 作为条件,以减少不确定性并学习高质量的表征。
作为条件,以减少不确定性并学习高质量的表征。
3.2 智能体行为学习
智能体的评论家网络和演员网络使用世界模型生成的想象轨迹进行训练。为了将 TWISTER 与先前使用世界模型表征训练智能体的方法进行比较,我们采用 DreamerV3(Hafner 等人,2023)中的智能体行为学习设置。学习完全在潜在空间中进行,这使智能体能够处理大批量数据并提高泛化能力。我们将采样序列的模型状态在批次和时间维度上展平,使用世界模型生成![]() 个样本轨迹。在世界模型训练阶段计算的自注意力键值特征被缓存,以便在智能体行为学习阶段重复使用并保留过去的上下文。如图 3b 所示,世界模型使用 Transformer 网络和动力学网络头部预测未来 H=15 步,通过从演员网络的分类分布中采样来选择动作。与世界模型预测器网络类似,演员网络和评论家网络被设计为简单的 MLP,分别具有参数向量(
个样本轨迹。在世界模型训练阶段计算的自注意力键值特征被缓存,以便在智能体行为学习阶段重复使用并保留过去的上下文。如图 3b 所示,世界模型使用 Transformer 网络和动力学网络头部预测未来 H=15 步,通过从演员网络的分类分布中采样来选择动作。与世界模型预测器网络类似,演员网络和评论家网络被设计为简单的 MLP,分别具有参数向量()和(
):
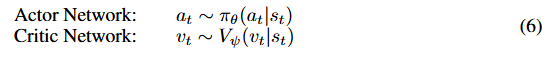
评论家学习
遵循 DreamerV3,评论家网络学习最小化对称对数交叉熵损失,该损失是关于从世界模型预测的奖励和情节延续标志的想象轨迹中获得的离散化λ - 回报 discretized λ-returns:
![]()
评论家网络不使用目标网络,而是依赖自身预测来估计超出预测范围的奖励。这需要通过向其自身 EMA 网络![]() 的输出添加正则化项来稳定评论家网络。公式(8)定义了评论家网络的损失:
的输出添加正则化项来稳定评论家网络。公式(8)定义了评论家网络的损失:
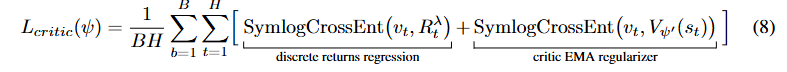
演员学习
演员网络学习选择最大化预测回报的动作,同时使用强化学习(Williams,1992)最大化策略熵,以确保在数据收集和想象过程中进行充分探索。演员网络的损失定义如下:
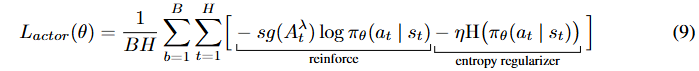
其中![]() 定义了使用归一化回报计算的优势。回报使用其第 5 和第 95 批次百分位数的指数移动平均统计进行缩放,以确保在所有 Atari 游戏中稳定学习:
定义了使用归一化回报计算的优势。回报使用其第 5 和第 95 批次百分位数的指数移动平均统计进行缩放,以确保在所有 Atari 游戏中稳定学习:
![]()
4. 实验
在本节中,我们描述了在常用的 Atari 100k 基准测试上的实验。我们在表 2 中将 TWISTER 与 SimPLe、DreamerV3 以及近期基于 Transformer 模型的方法进行比较。我们还对 TWISTER 的主要组件进行了多项消融研究。
4.1 Atari 100k 基准测试
Atari 100k 基准测试由 Kaiser 等人(2020)提出,用于在低数据条件下评估 Atari 游戏中的强化学习智能体。该基准测试包括 26 款 Atari 游戏,环境框架预算为 400k,在默认动作重复设置下,这相当于智能体与环境之间进行 100k 次交互。这些环境步骤数量相当于约两小时(1.85 小时)的实时游戏时间,与人类玩家达到合理良好性能所需的时间相似。目前的最先进水平由 EfficientZero V2(Wang 等人,2024)保持,它在每个时间步使用蒙特卡罗树搜索选择最佳动作。另一项近期值得注意的工作是 BBF(Schwarzer 等人,2023),这是一种无模型智能体,使用与我们的工作正交的学习技术,如周期性网络重置和超参数退火来提高性能。在这项工作中,为了确保公平比较并展示 AC-CPC 在学习世界模型方面的有效性,我们将我们的方法与不使用前瞻搜索技术的基于模型的方法进行比较。不过,将这些额外组件与 TWISTER 相结合,将是未来工作一个有趣的研究方向。
4.2 结果
表 2 将 TWISTER 与 SimPLe(Kaiser 等人,2020)、DreamerV3(Hafner 等人,2023)以及近期基于 Transformer 模型的方法(Robine 等人,2023;Micheli 等人,2023;Zhang 等人,2024;Micheli 等人,2024)在 Atari 100k 基准测试上进行比较。与先前工作一致,我们使用人类归一化指标,并比较所有 26 款游戏的平均和中位数回报。人类归一化分数是针对每个游戏,使用人类玩家获得的分数和随机策略获得的分数计算得出: 。我们还在图 5 中展示了人类归一化平均和中位数的分层引导置信区间。各个游戏的性能曲线可在附录 9 中找到。
TWISTER 在 Atari 100k 基准测试中实现了 162% 的人类归一化平均得分和 77% 的中位数得分,在不使用前瞻搜索技术的最先进基于模型的方法中创下新纪录。与 STORM 类似,我们发现 TWISTER 在与奖励相关的关键对象众多的游戏中表现出色,如《Amidar》《Bank Heist》《Gopher》和《Ms Pacman》。此外,我们观察到 TWISTER 在有小移动对象的游戏中性能有所提升,如《Breakout》《Pong》和《Asterix》。我们推测,AC-CPC 目标要求智能体在这些游戏中关注球的位置,以准确预测未来样本,从而避免了重建损失忽略小物体的失败情况。或者,IRIS 和 Δ -IRIS 通过从高质量重建图像中学习智能体来解决这个问题。它们通过 VQ-VAE 结构将图像观测编码到空间潜在空间中,这使得这些方法能够更好地捕捉细节并实现更低的重建误差,从而在这些游戏中取得良好效果。我们在附录 A.4 中展示了世界模型对各种 Atari 游戏的 CPC 预测。
(表 2:Atari 100k 基准测试中 26 款游戏的智能体得分和人类归一化指标。我们展示了 5 个随机种子的平均得分。加粗数字表示每个游戏中性能最佳的方法。)
(图 5:使用分层引导置信区间(Agarwal 等人,2021)计算的平均和中位数得分。TWISTER 实现了 1.62 的归一化平均得分和 0.77 的中位数得分。)
4.3 消融研究
为了研究 AC-CPC 对 TWISTER 性能的影响,我们在 Atari 100k 基准测试的所有 26 款游戏上进行消融研究,每次进行一项修改。我们对世界模型预测的 CPC 步骤数量进行实验。我们表明数据增强有助于使 AC-CPC 目标复杂化并提高其有效性。我们发现使 CPC 预测依赖于未来动作序列会带来更准确的预测并提高表征质量。我们还研究了世界模型设计对 AC-CPC 有效性的影响。表 3 展示了在 400k 环境步骤后主要消融实验获得的聚合得分。
(表 3:对 AC-CPC 损失、对比样本增强、基于未来动作的条件设定以及使用 DreamerV3 的 RSSM 进行消融实验。我们每次进行一项修改,并在 26 款 Atari 游戏上进行评估。各个游戏的详细结果可在附录 A.6 中找到。)

对比步骤数量
我们对多个 CPC 步骤数量进行实验,比较 Atari 100k 基准测试中所有 26 款游戏的人类归一化指标。图 6a 表明,当预测未来 10 步时,TWISTER 实现了最佳的人类归一化平均得分,对应于 0.67 秒的游戏时间。我们发现,在一定数量的步骤内,AC-CPC 对 TWISTER 性能有显著影响。我们观察到,随着预测的 CPC 步骤数量增加,人类归一化平均和中位数得分也增加。然而,当预测未来 15 步时,结果出现下降。中位数得分的差异表明中等得分游戏的性能下降。
(图 6:在 Atari 100k 基准测试上进行的消融实验。结果是在 5 个随机种子上平均得到的。我们研究了数据增强、动作条件设定和预测的 CPC 步骤数量对 TWISTER 性能的影响。我们还研究了世界模型设计对 AC-CPC 有效性的影响。)
世界模型架构
我们研究了世界模型设计对 AC-CPC 学习特征表征有效性的影响。图 6b 展示了用 DreamerV3 的 RSSM(Hafner 等人,2023)替换 TWISTER 的 TSSM 时,AC-CPC 对性能的影响。虽然在没有 AC-CPC 目标的情况下,这两种方法取得了相似的结果,但我们发现 AC-CPC 对 TWISTER 有显著影响,在大多数游戏中提高了性能。这些发现可以归因于 Transformer 由于几个关键架构差异,通常比 RNN 在学习特征表征方面更有效。自注意力机制无需循环即可对时间关系进行建模的能力,使 Transformer 架构在捕捉上下文和学习层次特征方面非常有效。另一方面,RNN 的循环性质可能导致梯度消失和收敛速度较慢,特别是在处理长序列时。
动作条件设定
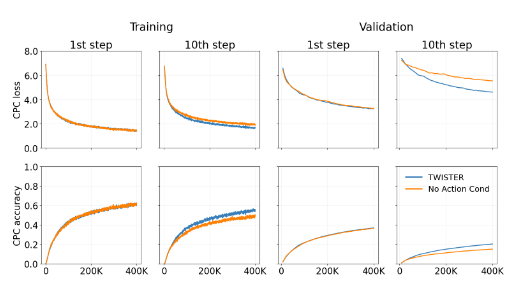
我们发现,使 CPC 预测头依赖于未来动作序列会带来更准确的预测和更高质量的表征。图 7 展示了所有 Atari 游戏的训练和验证序列上的聚合 CPC 损失和预测准确率。我们报告在对比损失中,正样本相似度高于负样本相似度的平均次数。如果不知道未来动作序列,世界模型就无法准确预测未来环境状态,这使得该任务在一定数量的 CPC 步骤之后几乎无法解决且适得其反。我们观察到,在不知道未来动作序列的情况下预测多个步骤时,与 TWISTER 相比准确率会下降。图 6c 展示了在去除 CPC 预测的未来动作条件时,26 款游戏的聚合人类归一化得分。我们发现,在去除未来动作条件时,CPC 目标并没有带来显著的性能提升。
(图 7:所有 26 款游戏的聚合 CPC 损失和预测准确率。我们使用一个包含 100k 样本的验证重放缓冲区,比较在未见过的轨迹上的 CPC 损失。这些轨迹是从用 5 个种子预训练的 DreamerV3 和 TWISTER 智能体的集合中获得的。)
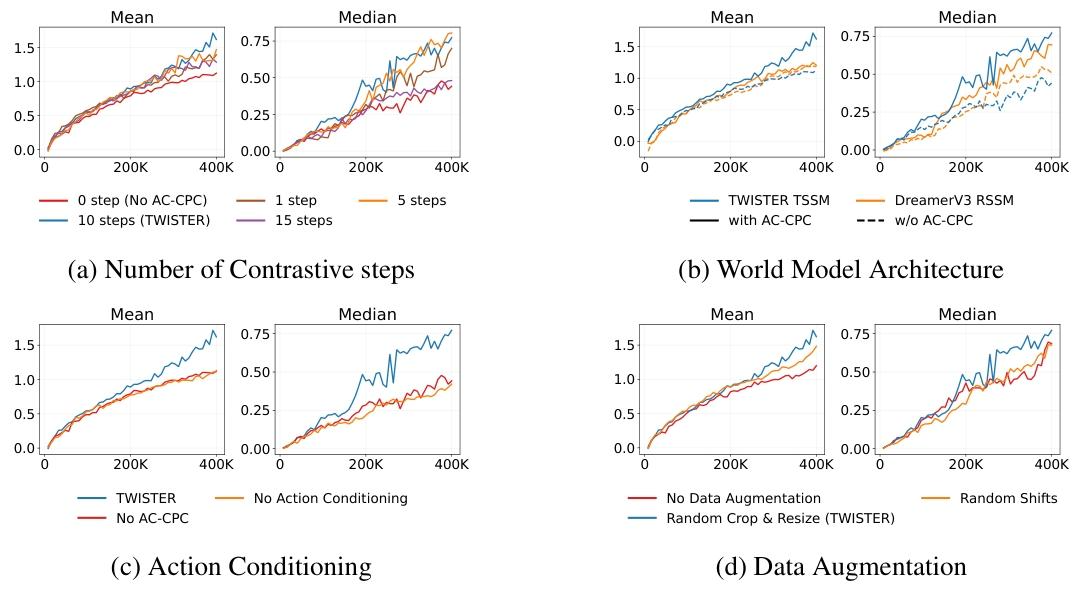
数据增强的效果
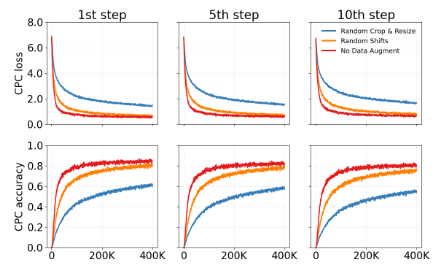
Kharitonov 等人(2021)研究了数据增强对 CPC 性能的影响。在他们的工作中,他们提出为 CPC 引入数据增强以学习更高质量的语音表征,从而获得更好的性能。在这项工作中,我们对对比样本应用图像增强,以使 AC-CPC 目标更加复杂,并使表征学习任务更具挑战性。在训练过程中,我们应用了基于图像的对比学习领域中常用的随机裁剪和调整大小增强方法,因为其效果显著(Chen 等人,2020)。随机裁剪的使用要求世界模型识别观测中的几个关键元素,以便准确预测正样本。我们还对随机平移(Yarats 等人,2021)进行了实验,将图像在高度和宽度上最多平移 4 个像素,但发现它对学习目标的影响较小。图 6d 展示了所研究增强技术的聚合人类归一化得分。我们发现随机裁剪和调整大小对提高最终性能最有帮助。对正样本和负样本不使用图像增强会降低 AC-CPC 对 TWISTER 性能的影响,导致平均得分和中位数得分较低。我们在图 8 中展示了数据增强对不同时间跨度的 AC-CPC 目标复杂性的影响。
(图 8:数据增强对 AC-CPC 目标复杂性的影响。我们聚合了所有 Atari 游戏在不同时间跨度上的 CPC 损失和预测准确率。)
5. 结论
我们提出了 TWISTER,这是一种基于 Transformer 模型的强化学习智能体,它使用动作条件对比预测编码来学习高级时间特征表征。TWISTER 在 Atari 100k 基准测试中,在不使用前瞻搜索的基于模型的方法中取得了新的最先进结果,人类归一化平均得分和中位数得分分别为 162% 和 77%。我们研究了学习对比表征对基于 Transformer 的世界模型的影响,发现 AC-CPC 目标显著有助于提高智能体性能。我们还表明,数据增强和未来动作条件设定在表征学习中起着重要作用,它们使 AC-CPC 目标更加复杂,并帮助模型进行准确的未来预测。根据我们的初步发现,我们希望这项工作能够激发研究人员进一步研究自监督学习技术在基于模型的强化学习中的益处。

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









