






中科院3区文章
摘要
人类通常基于过去的经验和观察做出决策,而在机器人操作领域,机器人的动作预测往往仅依赖当前观察。这使得机器人在当前观察不理想时,容易忽视环境变化,或者决策失效。为解决机器人学中的这一关键挑战,受人类认知过程的启发,我们提出一种融合历史学习和多视角注意力机制的方法,以提升机器人操作性能。基于时空注意力机制,该方法不仅结合当前和过去步骤的观察,还融入历史动作,以便更好地感知机器人行为变化及其对环境的影响。我们还采用基于互信息的多视角注意力模块,自动聚焦于有价值的视角,为决策融入更有效的信息。此外,受人类视觉系统同时处理全局上下文和局部纹理细节的启发,我们设计了融合语义和纹理特征的方法,帮助机器人理解任务,增强其处理细粒度任务的能力。在 RLBench(《Rlbench: The Robot Learning Benchmark & Learning Environment》[27] )和真实场景中的大量实验表明,我们的方法能有效处理各种任务,展现出显著的稳健性和适应性。
1. 引言
尽管从演示中学习(LfD)在机器人领域取得了显著成果 [1,2] ([1]《Recent advances in robot learning from demonstration》;[2]《Survey of imitation learning for robotic manipulation》),但学习一种由语言引导的操作策略,从视觉观察中预测 3D 末端执行器的姿态仍极具挑战性。一方面,对于一些复杂的操作任务,如制作咖啡,模仿人类演示通常涉及一系列按顺序执行的子任务,可将其表述为长期马尔可夫决策过程(MDP)。这些任务不仅需要理解抽象的语言指令,还要求具备执行多种基本行为的能力,这些行为共同促成整个操作任务的完成。不幸的是,传统的模仿学习方法 [3] (《Imitation learning: A survey of learning methods》),如行为克隆 [4] (《Behavioral cloning from observation》),往往陷入累积复合误差的困境,在遇到长期动作序列时,性能会急剧下降。为应对长期任务中的挑战,一些研究 [5,6] ([5]《League: Guided skill learning and abstraction for long-horizon manipulation》;[6]《Accelerating reinforcement learning with learned skill priors》)将技能学习应用于将这些任务分解为子任务,随后任务规划算法将这些子任务组合形成长期任务。然而,这种方法并非端到端的,需要根据特定场景预先收集相关技能。单个技能的稳健性有限,会降低长期任务的整体性能。基于大语言模型(LLM)[7 - 10] ([7]《Llm-based human-robot collaboration framework for manipulation tasks》;[8]《Smart-llm: Smart multi-agent robot task planning using large language models》;[9]《Enhancing the LLM-Based Robot Manipulation Through Human-Robot Collaboration》;[10]《Language models as zero-shot trajectory generators》)的机器人操作发展迅速,其中目标检测技术首先从场景中提取物体,然后将特定任务的提示发送给像 GPT - 4 [11] (《GPT-4 technical report》)这样的大语言模型来控制机器人。此类方法依赖目标检测的准确性和大语言模型的推理能力,而大语言模型在许多场景中可能会产生幻觉 [12] (《Exploring and evaluating hallucinations in llm-powered code generation》),导致不可预测的行为。我们的方法采用端到端的方式处理长期任务,利用基于时空注意力的网络融合历史信息,从而提高长期任务的性能。
另一方面,由于视觉观察固有的部分可感知性,仅依赖特定视角的 RGB 图像可能会遗漏关键信息,导致执行动作出现显著偏差。例如,当抽屉把手在相机视野内被机器人手臂遮挡时,智能体往往难以快速定位核心部件的位置,从而导致异常动作。虽然多视角系统通过结合多个视角缓解了这一问题,但也带来了新的挑战。机器人或环境造成的遮挡会产生盲点 [13] (《Mv-reid: 3d multi-view transformation network for occluded person re-identification》),需要智能融合方法来尽量减少信息损失。此外,为每个任务动态确定最具信息性的视角优先级至关重要,但传统的静态加权方法 [14] (《Deep multi-view learning methods: A review》)往往缺乏这一点。而且,多视角处理会带来较高的计算和内存需求,因为不同视角会积累冗余数据。
为了更好地编码空间遮挡并提高空间推理能力,一些方法 [15,16] ([15]《Dexpoint: Generalizable point cloud reinforcement learning for sim-to-real dexterous manipulation》;[16]《Multi-modal geometric learning for grasping and manipulation》)集成了从点云导出的 3D 感知表示,通过提供 2D 图像无法单独提供的深度和结构信息,提高了末端执行器姿态预测的空间精度。然而,这些方法通常依赖非结构化的点云数据,由于其不规则性,直接处理具有挑战性。为此,常采用手动定义的网格或体素化策略 [17,18] ([17]《Evaluation of Denoising and Voxelization Algorithms on 3D Point Clouds》;[18]《Voxel-based representation of 3D point clouds: Methods, applications, and its potential use in the construction industry》),将点云转换为高分辨率的 3D 特征表示。虽然这些转换在捕捉空间细节方面有效,但计算成本高昂,特别是在高分辨率下,会增加内存需求和处理时间。
最近,一些方法 [19,20] ([19]《ULIP: Learning a unified representation of language, images, and point clouds for 3D understanding》;[20]《R3m: A universal visual representation for robot manipulation》)提出了通用表示的概念,利用在广泛多样的真实世界数据上预训练的视觉模型,改进语义特征提取,使机器人能够更广泛地理解任务上下文。通过捕捉丰富的真实世界特征,这些通用模型增强了机器人解释场景语义的能力,最终实现更明智的决策和任务理解。然而,这些预训练模型的一个显著局限性是,它们对高度专业化或复杂操作环境的适应性降低,例如涉及螺丝和电子连接器等细粒度组件的精密装配任务。在这些场景中,通用表示可能缺乏精确操作所需的细节和上下文。
针对这些局限性,我们提出了一种新颖的机器人操作框架,强调历史信息集成、分层特征融合和多视角注意力机制。我们的贡献如下:
第一,我们引入时空注意力机制,将时间信息与当前状态融合,使模型能够利用先前的动作和观察来改进决策。通过结合先前时间步的视觉观察,机器人可以感知环境的动态变化。过去动作的投影使机器人能够识别自己的动作轨迹,从而实现行为的自我纠正,并有助于减轻累积误差的影响。
第二,我们提出分层特征融合机制,将全局语义特征与来自多模态输入(如 RGB 图像和点云)的局部纹理细节相结合。这种融合使机器人能够提取全局语义特征以理解任务,同时关注精确操作所需的细粒度物体细节。
第三,为了克服单视角和传统多视角视觉输入的局限性,我们提出基于互信息的多视角注意力机制,为不同相机动态分配权重,以突出包含更多信息特征的视角。此外,在基于 3D 点云数据的动作输出阶段,我们优先选择包含最有价值信息的视角,以进行更准确的预测。流程如图 1 所示。
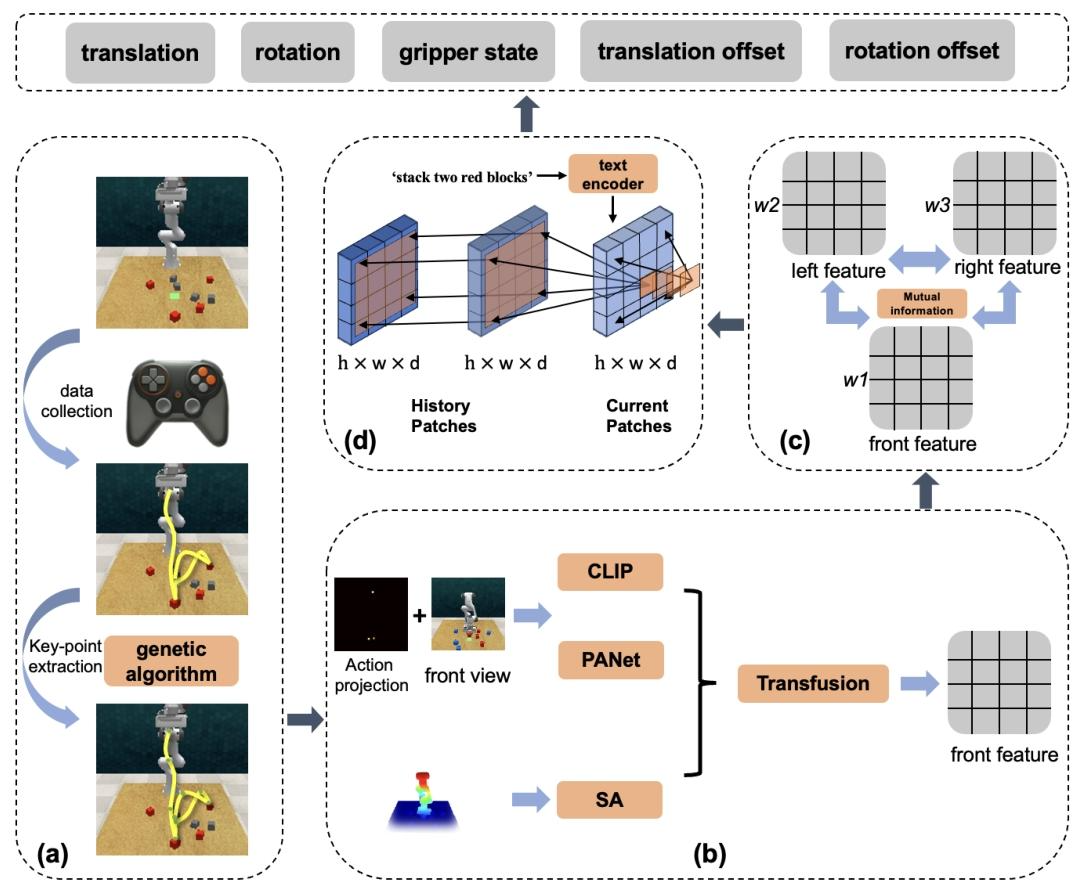
图 1. (a)部分是轨迹处理模块。使用游戏手柄手动收集演示,然后基于关键点分析和遗传算法提取宏观步骤。(b)部分从视觉输入中提取分层特征,并通过融合(transfusion)进行合并。融合后的视觉特征在(c)部分进行处理,利用互信息减少视觉特征冗余,并计算每个视角的权重。然后对多视角信息进行加权融合。在(d)部分,融合后的多视角特征通过时空注意力网络,网络输出机器人要执行的动作。输出动作由末端执行器的 3D 姿态、位置偏移和夹爪状态组成。
2. 相关工作
2.1 语言条件下的多任务操作
在机器人操作中,基于学习的方法 [21] (《A survey on learning-based robotic grasping》)已成为强大的工具,特别是在传统视觉伺服技术 [22] (《Visual servo control. I. Basic approaches》)难以应对的动态环境中。多任务操作受到越来越多的关注,元学习 [23] (《A perspective view and survey of meta-learning》)、强化学习 [24] (《Reinforcement learning: A survey》)和模仿学习等方法常被用于同时训练多种任务,促进知识转移并形成通用模型。语言指令在引导智能体理解任务要求和区分不同任务方面起着关键作用。像 CLIP [25] (《Learning transferable visual models from natural language supervision》)和 Bert [26] (《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)这样的大语言模型的兴起,显著影响了自然语言处理,使从语言指令中提取更有效特征成为可能。为进行基准测试,我们选择 RLBench [27] (《Rlbench: The Robot Learning Benchmark & Learning Environment》),并利用其内置的演示生成功能,同时为每个任务设计语言命令。
2.2 用于操作的视觉表示
在机器人操作中,理解环境信息至关重要。视觉表示可分为 2D 和 3D 两种类型,各有独特优势:2D 表示,包括 PANet [28] (《Panet: Few-shot image semantic segmentation with prototype alignment》)、UNet [29] (《U-net: Convolutional networks for biomedical image segmentation》)和 ResNet [30] (《Deep residual learning for image recognition》),能提供丰富的语义和纹理特征;3D 表示,包括 PointNet++[31] (《Pointnet++: Deep hierarchical feature learning on point sets in a metric space》)、C2FARM [32] (《Coarse-to-fine q-attention: Efficient learning for visual robotic manipulation via discretisation》)和 PERACT [33] (《Perceiver-actor: A multi-task transformer for robotic manipulation》),则提供全面的结构信息。在机器人操作领域,预训练视觉模型近来成为热门话题。这些模型利用来自真实世界和模拟环境的大量数据集获取通用特征,支持各种下游任务,显著节省时间和资源。此类模型包括 CLIP [25] (《Learning transferable visual models from natural language supervision》)、R3M [20] (《R3m: A universal visual representation for robot manipulation》)和 SGR [34] (《A Universal Semantic-Geometric Representation for Robotic Manipulation》)。我们的研究利用预训练的视觉语言模型提取全局语义特征,使用分层特征提取网络提取局部纹理特征,并将 2D 视觉特征与 3D 结构信息相结合以进行动作预测。
2.3 机器人 Transformer
Transformer 架构 [35] (《Attention is all you need》)在自然语言处理、计算机视觉和机器人操作等领域取得了重大进展。其在机器人学中的应用涵盖多个领域,如腿部运动 [36] (《Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers》)、路径规划 [37] (《Differentiable spatial planning using transformers》)和视觉语言导航 [38] (《Understanding natural language commands for robotic navigation and mobile manipulation》)。Transformer 的通用性凸显了其处理复杂机器人任务的能力,展示了在不同场景中的适应性和有效性。虽然出现了几种基于 Transformer 的方法,但它们很少充分利用 Transformer 在复杂多模态场景中利用历史数据增强动作预测的卓越能力。PERACT 利用感知器 Transformer(Perceiver Transformer)[33] (《Perceiver-actor: A multi-task transformer for robotic manipulation》)基于当前体素观察预测动作,实现了更高的效率和稳健性。Gato [39] (《A generalist agent》)是一个多模态、多任务的通用智能体。然而,Gato 严重依赖大型数据集,如积木堆叠任务需要 15,000 个情节,Metaworld 任务需要 94,000 个情节。相比之下,我们的方法仅需 50 - 100 个演示就能完成常见任务。
2.4 多视角机器人操作
多视角机器人操作因其能提供更丰富的视觉信息,实现更精确和稳健的操作任务而备受关注。使用多个视角有助于减少遮挡,增强感知,并提高机器人动作的准确性,特别是在复杂和杂乱的环境中。人们提出了多种方法来利用多视角设置改进场景理解和操作精度。Xie 和 Song [40] (《Multi-view Registration of Partially Overlapping Point Clouds for Robotic Manipulation》)提出了一种用于部分重叠点云的多视角配准方法,这对机器人操作中的精确 3D 重建至关重要。他们的点到平面配准模型利用位姿图最小化多视角配准中的累积误差,增强了在复杂环境中处理遮挡和噪声数据的能力,实现了精确的物体抓取和放置。Lin 等人 [41] (《Multi-view fusion for multi-level robotic scene understanding》)引入了一种用于多层次机器人场景理解的多视角融合框架。他们的系统集成 2D RGB 图像和 3D 点云,为机器人操作任务创建丰富的场景表示。通过结合用于避障的密集 3D 重建、用于未知物体的原始形状拟合以及用于已知物体的全 6 自由度物体姿态估计,他们的方法提升了抓取和物体重排等任务的性能。Seo 等人 [42] (《Multi-view masked world models for visual robotic manipulation》)提出了一种新颖的多视角掩码自动编码器,可从随机视角学习重建掩码像素,显著提高了机器人的感知能力。该技术捕捉视角内和跨视角信息,在无需相机校准的情况下改进多视角控制和真实机器人任务转移。Song 等人 [43] (《Learning precise 3d manipulation from multiple uncalibrated cameras》)探索了从多个未校准相机学习精确 3D 操作的方法。通过利用无需预校准的相机配置,他们的方法简化了多视角集成过程,通过基于学习的方法直接优化任务性能,提高了操作精度。我们引入基于互信息的注意力机制,动态选择并突出最具信息性的视角,减少冗余,确保机器人的动作基于对环境全面而高效的表示。
3. 方法
3.1 问题定义
我们提出的方法旨在开发一种多模态、多视角、对历史敏感的策略框架,表示为![]() , 。这个策略融合了历史观察
, 。这个策略融合了历史观察![]() 、动作
、动作![]() 以及一系列语言指令
以及一系列语言指令![]() 。在这种情况下,m 表示为每个任务分配的语言指令数量,t 代表当前步骤。此外,s 表示过去步骤的数量。值得注意的是,在当前步骤小于 2 的场景中,策略仅依赖当前观察。这是因为在任务开始时,环境变化的影响可忽略不计,仅使用当前观察就足够了。
。在这种情况下,m 表示为每个任务分配的语言指令数量,t 代表当前步骤。此外,s 表示过去步骤的数量。值得注意的是,在当前步骤小于 2 的场景中,策略仅依赖当前观察。这是因为在任务开始时,环境变化的影响可忽略不计,仅使用当前观察就足够了。
我们旨在输出机器人要执行的动作,动作空间由末端执行器的姿态![]() 和夹爪状态
和夹爪状态![]() (打开或关闭)定义。参数
(打开或关闭)定义。参数![]() 表示位置,而
表示位置,而![]() 以四元数格式指定方向。
以四元数格式指定方向。
对于每个指定任务,我们准备了一系列全面的语言指令。步骤 t 的观察包括从 K 个视角获取的 RGB 图像![]() 和点云数据
和点云数据![]() ,在模拟中 k 等于 3,在真实世界实验中 K 等于 2。这里,
,在模拟中 k 等于 3,在真实世界实验中 K 等于 2。这里,![]() 都有三个通道,在我们的模拟实验中,其
都有三个通道,在我们的模拟实验中,其
3.2 增强视觉表示
在 4.5 节的消融实验中我们发现,仅依靠 CLIP 特征或 PANet 进行 RGB 图像特征提取会导致成功率降低,在对精度要求较高的任务中尤为明显。例如,单独使用预训练的 CLIP 模型会显著降低插栓任务的成功率。尽管这些通用视觉模型在捕捉环境语义上下文和识别可执行任务方面很有效,但它们往往缺乏识别对精确操作至关重要的细粒度环境细节所需的分辨率。
为克服这一限制,我们提出一种新颖的特征提取方法,将全局语义特征与局部纹理特征相结合。这种双特征设计使机械臂不仅能理解任务,还能执行成功完成任务所需的精确动作。
如图 3 所示,在某一时刻的特定视角下,RGB 图像经过 PANet 和 CLIP 模型处理后,我们提取局部纹理特征(![]() )和全局语义特征(
)和全局语义特征(![]() )。局部纹理特征
)。局部纹理特征![]() 的维度为
的维度为![]() ,而全局语义特征
,而全局语义特征![]() 是长度为的一维向量
是长度为的一维向量![]() 。为融入空间信息,我们将末端执行器的姿态投影到 2D 平面上,并对该投影进行缩放以匹配
。为融入空间信息,我们将末端执行器的姿态投影到 2D 平面上,并对该投影进行缩放以匹配![]() 的维度。然后,我们将姿态投影和
的维度。然后,我们将姿态投影和![]() 沿通道维度连接起来,形成 RGB-A 特征
沿通道维度连接起来,形成 RGB-A 特征![]() 。随后,将全局语义特征
。随后,将全局语义特征![]() 扩展为
扩展为![]() 的维度,得到
的维度,得到![]() 。最后,我们将
。最后,我们将![]() 沿通道维度连接起来,应用卷积和池化操作,得到最终的 RGB-A 特征
沿通道维度连接起来,应用卷积和池化操作,得到最终的 RGB-A 特征![]() ,它有效地融合了局部纹理细节和全局语义信息。
,它有效地融合了局部纹理细节和全局语义信息。
图 3. RGB 图像由 PANet 和 CLIP 模型处理,以获得局部纹理特征()和全局语义特征()。这些特征与末端执行器姿态的 2D 投影相结合,形成 RGB-A 特征()。同时,使用 PointNet++ 的集合抽象(SA)模块处理多视角点云数据,以提取点云特征()。这些视觉和点云特征的融合增强了机器人与复杂环境交互的能力。
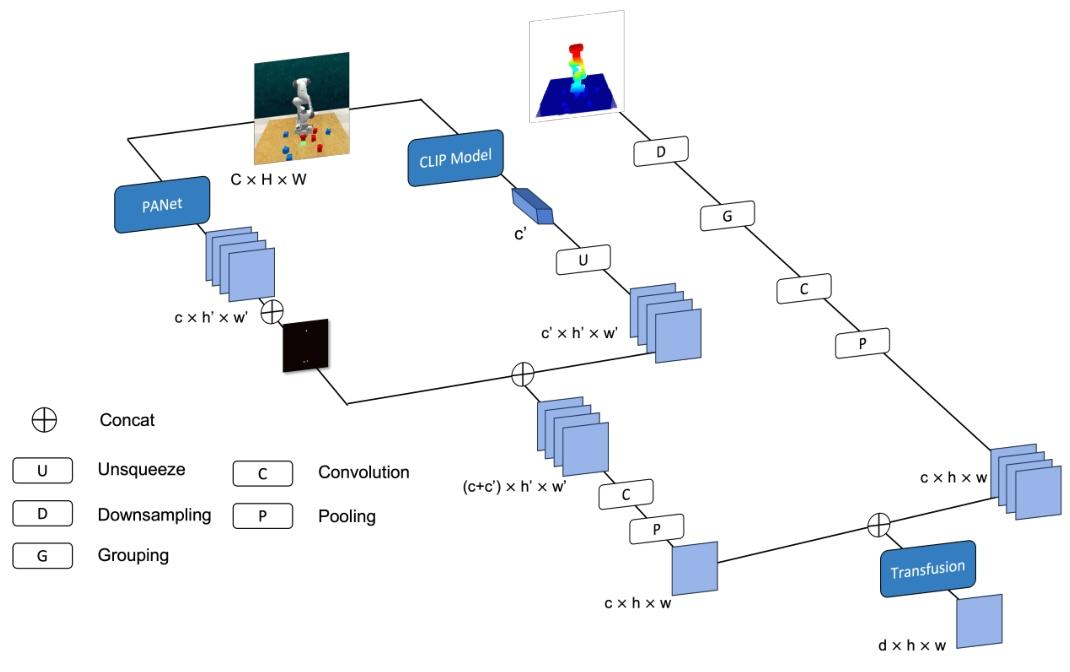
此外,我们将多视角点云数据![]() 整合到一个统一的全局点云数据集 P 中。使用 PointNet++ 中的集合抽象(SA)模块对全局点云进行处理,该模块包括下采样、分组和特征提取,从而得到一组经过优化的点云特征 FP。与其他基于点云的方法相比,仅使用 SA 模块处理点云数据的计算成本显著降低。受 TransFusion [44](《TransFusion: Multi-Modal Fusion Network for Semantic Segmentation》)方法的启发,我们应用交叉注意力机制融合这些元素,得到
整合到一个统一的全局点云数据集 P 中。使用 PointNet++ 中的集合抽象(SA)模块对全局点云进行处理,该模块包括下采样、分组和特征提取,从而得到一组经过优化的点云特征 FP。与其他基于点云的方法相比,仅使用 SA 模块处理点云数据的计算成本显著降低。受 TransFusion [44](《TransFusion: Multi-Modal Fusion Network for Semantic Segmentation》)方法的启发,我们应用交叉注意力机制融合这些元素,得到![]() ,其中
,其中![]() 。
。
3.3 基于互信息的多视角注意力机制
在多视角视觉任务中,每个视角都可以提供关于环境的独特信息,但并非所有视角都同样有用。为了最大限度地利用有价值的视角,我们引入一种基于互信息的注意力机制,它能动态选择并突出最具信息性的视角,减少冗余,确保机器人的动作基于对环境全面而高效的表示。
在某一时刻,给定从多个视角提取的一组特征图![]() ,我们旨在将它们合并为一个具有代表性的特征图,该特征图保留每个视角中最有价值的信息。然而,挑战在于确保融合后的特征图既具有信息性又无冗余。传统的融合方法通常对每个视角应用相同或固定的注意力,这可能会导致信息冗余,尤其是当多个视角捕捉到场景的相似部分时。
,我们旨在将它们合并为一个具有代表性的特征图,该特征图保留每个视角中最有价值的信息。然而,挑战在于确保融合后的特征图既具有信息性又无冗余。传统的融合方法通常对每个视角应用相同或固定的注意力,这可能会导致信息冗余,尤其是当多个视角捕捉到场景的相似部分时。
为解决这个问题,我们提议使用互信息 mutual information(MI)来衡量不同视角之间共享和独特的信息。对于两个特征图![]() ,互信息
,互信息![]() 量化了它们共享的信息量。互信息高表明存在冗余,而互信息低则表明两个视角包含互补信息。两个特征图之间的互信息由下式给出:
量化了它们共享的信息量。互信息高表明存在冗余,而互信息低则表明两个视角包含互补信息。两个特征图之间的互信息由下式给出:
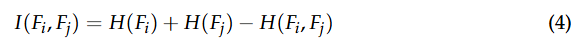
其中![]() 分别表示特征图和的熵,
分别表示特征图和的熵,![]() 是它们的联合熵。这个度量使我们能够量化不同视角之间共享的信息量,并利用这些信息来指导注意力机制。
是它们的联合熵。这个度量使我们能够量化不同视角之间共享的信息量,并利用这些信息来指导注意力机制。
为了使融合过程形式化,我们首先计算互信息矩阵 M,其中每个元素![]() 表示特征图和之间的互信息:
表示特征图和之间的互信息:

这个矩阵提供了所有视角信息冗余的全局概况。利用这个矩阵,我们根据每个视角提供的独特信息量为其分配动态注意力权重![]() 。这些权重通过优化学习得到,目标是最小化融合特征图中的冗余。具体来说,我们定义基于互信息的损失函数如下:
。这些权重通过优化学习得到,目标是最小化融合特征图中的冗余。具体来说,我们定义基于互信息的损失函数如下:
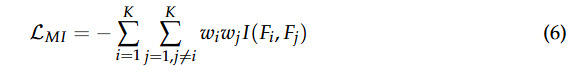
在这个公式中,![]() 表示特征图和之间的互信息,它量化了两个视角之间共享的信息量。互信息值高表明两个特征图提供冗余信息,而较低的值则表明更多的互补信息。
表示特征图和之间的互信息,它量化了两个视角之间共享的信息量。互信息值高表明两个特征图提供冗余信息,而较低的值则表明更多的互补信息。
权重![]() 是分配给每个视角的注意力权重,在训练过程中动态学习。通过在损失函数中包含这些权重的乘积,该公式旨在惩罚互信息高且注意力权重也大的特征图对。其背后的逻辑是,如果两个视角提供冗余信息,它们相应的权重应该降低。相反,提供更多互补信息的视角将被分配更高的权重。
是分配给每个视角的注意力权重,在训练过程中动态学习。通过在损失函数中包含这些权重的乘积,该公式旨在惩罚互信息高且注意力权重也大的特征图对。其背后的逻辑是,如果两个视角提供冗余信息,它们相应的权重应该降低。相反,提供更多互补信息的视角将被分配更高的权重。
通过最小化这个损失函数,我们鼓励注意力机制为提供独特信息的视角分配更高的权重,同时减少冗余视角的贡献。权重在训练过程中通过反向传播动态更新,使模型能够适应不同的场景配置和视角排列。
一旦学习到注意力权重,最终融合的特征图将计算为各个特征图的加权和:

这种加权融合确保最终的特征图捕捉到每个视角中最相关和互补的信息。通过专注于最大化视角之间的互信息,我们的注意力机制减少了冗余,增强了机器人在复杂环境中的感知和行动能力。
这种基于互信息的注意力机制的关键优势在于它能够动态适应场景内容和视角排列。与对所有视角应用相同注意力的传统方法不同,我们的方法有选择地突出最具信息性的视角,从而得到更高效和更具信息性的表示。这种改进的表示不仅增强了机器人的感知能力,还提高了其在需要与环境进行精确交互的任务中的决策能力。基于互信息的注意力机制确保机器人专注于最有价值的视角,有效地减少冗余并最大化互补信息的利用。
3.4 对历史敏感的决策网络
首先,我们引入 Transformer 架构中固有的注意力机制:
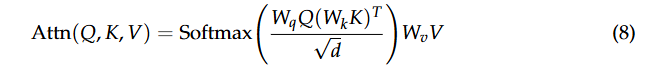
其中![]() 表示可训练参数。在我们提出的方法中,采用交叉注意力机制将 RGB-A 特征与点云数据融合,形成利用自注意力机制的对历史敏感的决策网络的基础。
表示可训练参数。在我们提出的方法中,采用交叉注意力机制将 RGB-A 特征与点云数据融合,形成利用自注意力机制的对历史敏感的决策网络的基础。
在增强视觉表示(EVR)模块和多视角注意力(MVA)模块之后,时刻 t 的集成特征图 ![]() 有效地将初始的图像
有效地将初始的图像![]() 分割为
分割为![]() 个离散的图像块。最初,经过 CLIP 模型处理的语言指令要经过文本预处理、标记化和嵌入处理。得到的嵌入向量被展平,随后通过卷积神经网络融入每个图像块的通道中,从而将语言信息嵌入到特征图中。此外,步骤位置编码和图像块位置编码都被注入到这个特征图的每个通道中,整合了关键的时间和空间信息。通过填充和因果编码机制的设计,并利用 Transformer 的自注意力机制,我们使每个图像块能够与当前步骤以及过去几个步骤的其他图像块进行交互,最终得到包含历史信息的特征图
个离散的图像块。最初,经过 CLIP 模型处理的语言指令要经过文本预处理、标记化和嵌入处理。得到的嵌入向量被展平,随后通过卷积神经网络融入每个图像块的通道中,从而将语言信息嵌入到特征图中。此外,步骤位置编码和图像块位置编码都被注入到这个特征图的每个通道中,整合了关键的时间和空间信息。通过填充和因果编码机制的设计,并利用 Transformer 的自注意力机制,我们使每个图像块能够与当前步骤以及过去几个步骤的其他图像块进行交互,最终得到包含历史信息的特征图 ![]() 。
。
![]() 随后与由 PANet 提取的多级特征图连接,并逐层进行上采样,只关注最有价值信息的视角,将特征图重构为其原始维度
随后与由 PANet 提取的多级特征图连接,并逐层进行上采样,只关注最有价值信息的视角,将特征图重构为其原始维度![]() 。如图 4 所示,位置解码器(本质上是一个具有单个输出通道的卷积层)将特征图转换为
。如图 4 所示,位置解码器(本质上是一个具有单个输出通道的卷积层)将特征图转换为![]() 。当与最具信息性视角的点云数据相结合并在通道维度上聚合时,热图生成精确的位置坐标
。当与最具信息性视角的点云数据相结合并在通道维度上聚合时,热图生成精确的位置坐标![]()
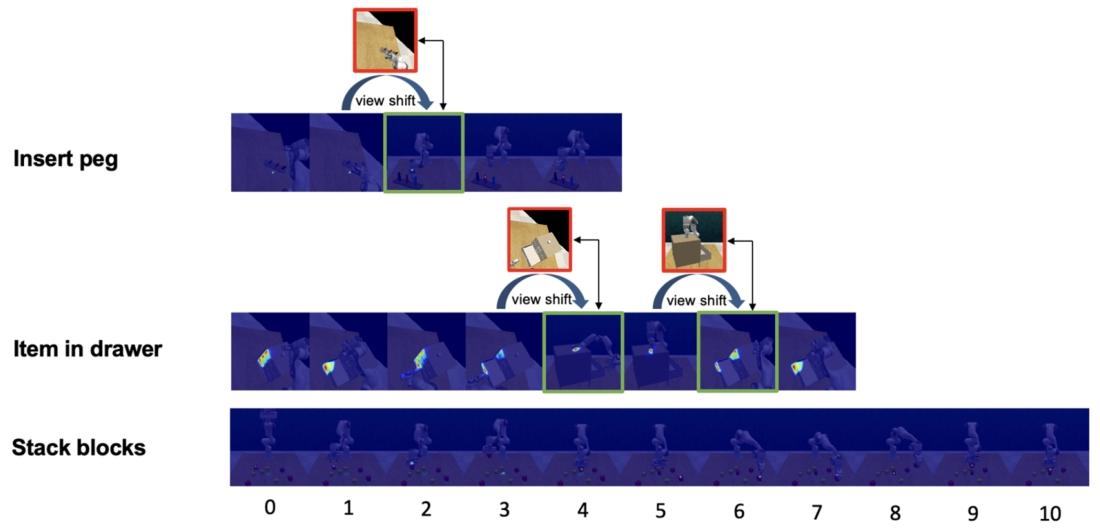
图 4. 双头箭头连接视角转换前后(红色框和绿色框)的视角。在插栓任务中,由于机器人手臂在第 2 步遮挡了左肩部视角的目标物体,视角从左肩部视角转换为前视图。在抽屉取物任务中,多视角注意力模块在第 4 步和第 5 步认为前视图更有价值。在堆叠积木任务中,视角没有变化。
随后,![]() 进行连接,一个由双卷积层、一个池化层和一对全连接层组成的解码器产生一个七维输出
进行连接,一个由双卷积层、一个池化层和一对全连接层组成的解码器产生一个七维输出![]() 。鉴于点云数据主要表示场景中实际存在的点,并且考虑到机器人手臂需要访问物体周围虚拟点的场景,参数
。鉴于点云数据主要表示场景中实际存在的点,并且考虑到机器人手臂需要访问物体周围虚拟点的场景,参数![]() 用于定义位置偏移,从而使机器人手臂能够熟练地导航并到达这些虚拟空间点
用于定义位置偏移,从而使机器人手臂能够熟练地导航并到达这些虚拟空间点
3.5 训练细节
我们的模型通过行为克隆进行训练。对于任务的每个变体,例如打开中间抽屉和打开底部抽屉在同一任务下被视为不同的实体,我们收集一组N个成功的轨迹,记为。这个过程包括利用遗传算法提取关键点,随后从大量步骤中识别出宏观步骤。每个演示,用表示,由一系列这些识别出的宏观步骤组成,表示一批演示。
我们最终的损失函数包括位置损失、旋转损失、夹爪损失和互信息损失。动作损失(位置、旋转和夹爪损失)确保模型根据专家演示准确预测机器人的动作,而互信息损失确保在特征融合过程中最小化多视角之间的冗余信息。组合损失函数定义如下:
其中:
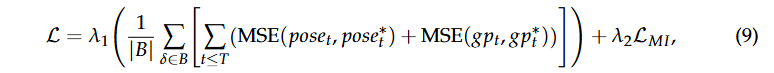

训练过程如算法 1 所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









