







Abstract
在人类环境中,机器人有望在给定简单的自然语言指令的情况下完成各种操作任务。然而,机器人操作极具挑战性,因为它需要细粒度的运动控制、长期记忆以及对以前看不见的任务和环境的泛化。为了应对这些挑战,我们提出了一种统一的基于transformer的方法,该方法考虑了多个输入。特别是,我们的 transformer 架构集成了 (i) 自然语言指令和 (ii) 多视图场景观察,而 (iii) 跟踪观察和动作的完整历史。这种方法能够学习历史和指令之间的依赖关系,并使用多个视图提高操作精度。我们在具有挑战性的 rlbench 基准和真实世界的机器人上评估我们的方法。值得注意的是,我们的方法可以扩展到 74 个不同的 rlbench 任务,并优于最先进的任务。我们还解决了指令条件任务,并证明了对以前看不见的变化的良好泛化。
Keywords: Robotics Manipulation, Language Instruction, Transformer
1 Introduction
人们可以自然地遵循语言指令并操纵对象来完成从烹饪到组装和修复的广泛任务。通过构建从先前看到的任务中学到的技能,也很容易推广到新的任务。因此,机器人技术的长期目标之一是创建通用的指令跟随 agents,可以推广到多个任务和环境。
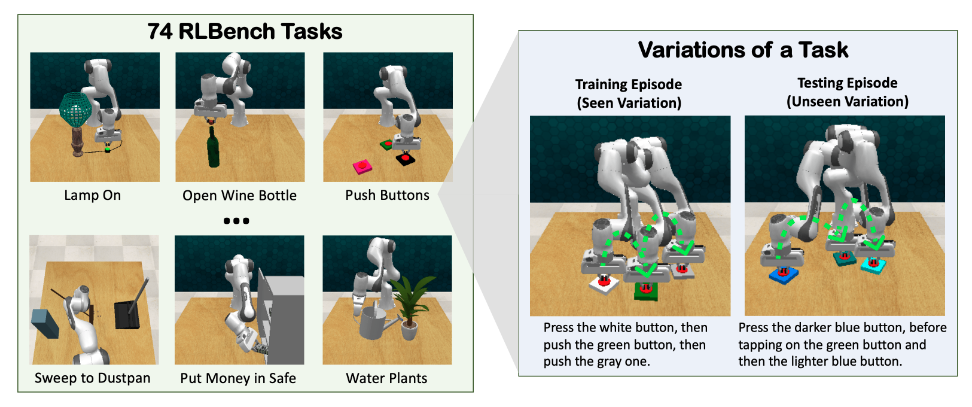
由于学习视觉和语言的通用表示方面取得了重大进展 [2, 3, 4, 5],最近的工作朝着这个目标取得了很大进展 [6, 7, 8, 9, 10]。例如,cliport [9] 利用 clip 模型 [5] 对单步视觉观察和语言指令进行编码,并为 10 个模拟任务学习单个 policy。bc-z [10] 使用预训练的句子编码器 [11] 泛化到多个操作任务。然而,一些挑战仍未得到充分探索。一个重要的挑战是顺序任务需要跟踪可能隐藏在当前观察中的对象状态,或者记住先前执行的操作。这种行为很难用最近主要依赖于当前观察的方法来建模[9,10]。另一个挑战涉及需要精确控制机器人末端执行器到达目标位置的操作任务。使用单视图方法[12]很难解决这样的任务,特别是在视觉遮挡和不同大小的物体的情况下,例如将钱放在安全图1(左)。虽然最近的一些方法通过将多视图图像转换为统一的 2d/3d 空间 [13, 14] 或通过多视图预测的后期融合 [15] 来组合来自多个相机的视图,但多个相机视图的学习表示是一个开放的研究问题。此外,视觉、动作和文本之间的跨模态对齐具有挑战性,特别是当训练和测试任务在对象和动作顺序方面有所不同时,见图 1(右)。大多数现有方法 [9, 10, 16, 17] 将指令压缩成一个全局向量来调节 policies [18],并且容易丢失有关不同对象的细粒度信息。
图 1:左:Hiveformer 可以适应在给定语言指令的情况下从 RLBench [19] 执行 74 个任务。右图:推送按钮任务的多种变化。
为了解决上述挑战,我们引入了 hiveformer——a History-aware instruction-conditioned multi-view transformer。它将指令转换为语言 tokens,给定一个预训练的语言模型 [5],并将视觉 tokens 与当前的视觉观察和本体感觉相结合。这些 tokens 被连接起来并馈送到多模态 transformer 中,该多模态 transformer 联合建模当前和过去观察之间的依赖关系、来自多台相机的视图之间的空间关系以及视觉和指令之间的细粒度跨模态对齐。基于我们的多模态transformer的输出表示,我们使用unet[20]解码器预测7自由度动作,即夹持器的位置、旋转和状态。
我们在三种设置中对 rlbench [19] 进行了广泛的实验:单任务学习、多任务学习和多变量泛化 (我们遵循 RLBench [19] 中的任务和变化定义。任务可以由共享相同技能但对象、属性或顺序上有所不同的多个变体组成,如图 1(右)所示)。我们的 hiveformer 在所有三种设置中都显着优于最先进的模型,证明了使用所提出的 transformer 从多个摄像头编码指令、历史和视图的有效性。此外,我们在 rlbench 的 74 个任务上评估我们的模型,这超出了 liu 等人使用的 10 个任务 [15]。我们根据所有任务的主要挑战将所有任务手动分组到 9 个类别中,并分析每个类别的结果以更好地理解。hiveformer 不仅在训练中看到的指令的多个任务设置中表现出色,而且还可以推广到表示任务不同变体的新指令,即使使用人工编写的语言指令。最后,我们评估了部署在真实机器人上的模型,并展示了出色的性能。有趣的是,当只有少量真实机器人演示可用时,在 rlbench 模拟器中预训练模型会产生显着的性能提升。
总而言之,我们的贡献有三方面:
- 我们引入了一种新的模型 hiveformer,以解决机器人任务中的各种挑战。它通过多模态transformer联合建模指令、多个视图和历史,用于机器人操作中的动作预测。
- 我们在 rlbench 上对我们的模型进行了广泛的消融,其中 74 个任务分为 9 个不同的类别。历史改进了长期任务,多视图设置对需要高精度或存在视觉遮挡的任务最有帮助。
- 我们证明了 hiveformer 在三个 rlbench 设置中优于最先进的技术,即单任务、多任务和多变量。使用合成指令训练的单个 hiveformer 能够解决多个任务和任务变化,可以推广到看不见的人工编写的指令,并在微调后在真实机器人上表现出出色的性能
2 Related Work
Vision-based robotic manipulation.
虽然早期解决视觉伺服[21,22]等机器人任务的方法是手动设计的,但需要处理物体和环境的巨大变化导致了基于学习的神经方法的出现[23,24,25,26]。深度神经网络[27,28]在操作单个任务[29]方面取得了令人印象深刻的结果,最近导致了更具挑战性的设置,如多任务学习[30,31,32,33]。通过发现哪些任务应该一起训练[15,34],确定跨任务的共享特征[35,36],元学习[37,38,39],目标条件学习[40,41]或反向强化学习[42],探索了不同的多任务方法。这些方法通常可以根据训练算法分为两类:
强化学习(rl)方法[43,44,45,46],从环境提供的奖励中学习policies;
行为克隆方法[47,48,49],使用监督学习从演示中学习。演示可以从人类[50]、机器人[23,51]或游戏互动[49]中获得。
机器人模拟器的出现,如gym[52]、operatorthor[53]、dm控制[54]、sapien[55]、causalworld[56]和rlbench[19],也大大加快了操作方法的发展。在这项工作中,我们使用行为克隆来训练policies,给定来自rlbench[19]的脚本演示,涵盖了许多具有挑战性的操作任务。
Instruction-driven vision-based robotic manipulation
在2D平面[57,58]或最近的3D环境[8,59,60]中的操纵越来越受到关注,并已转移到现实世界[9,10]。由于将语言植根于视觉场景很重要,现有的作品主要关注object grounding方面的挑战,例如基于referring expressions[61,62,63]和grounding spatial relationships[7,64,65]对对象进行定位。由于语言描述了高级操作,一些作品[60,66,67]考虑了一种将任务分解为子目标的分层方法。由于自然语言丰富多样,而训练资源有限,因此进一步的工作可以通过指令从收集的离线数据中学习[10,17],或者利用预先训练的视觉语言模型[4,5]进行动作预测[9,68]。为了进一步提高操作技能的精度,Mees等人[8]通过将输入图像与已知的相机参数融合,将指令与多个相机对齐。这些作品[6,8,9,10]大多是无状态的,因为它们只使用当前的观测来预测下一步的行动。相反,我们的工作建议对语言指令、历史和多视图观察进行联合建模。
Transformers
transformers[69]在自然语言处理[2]、计算机视觉[70]和相关领域[4,5,71]取得了重大进展。它们也被用于监督强化学习,如Decision transformer[72]或Trajectory transformer[73]。视觉和语言导航(vln)的最新研究[74,75,76]进一步证明,transformer可以更好地利用先前的观测结果来改进多模态动作预测。transformer也用于构建多模态、多任务、多实施例的多面手agent,gato[77]。受transformers成功的启发,我们探索了用于指令驱动和历史感知机器人操纵的transformer架构。
3 Problem Definition
我们的目标是训练一个policy
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









