







1.set集合
set集合是一种不包含重复元素的Collection,Set集合中主要有两个类:HashSet类和TreeSet类。一般情况我们使用hashset比较多。因为set集合默认是无序的。当我们想要对set集合进行排序时,会使用到TreeSet。
2.HashSet的使用及遍历
/**
* @program:
* @description
* @author:Mr.Jia
* @return:
* @creattime:2019-03-11 21:55:50
**/
public class TestSet {
public static void main(String[] args) {
Set<String> set=new HashSet();
set.add("a");
set.add("s");
set.add("d");
set.add("f");
set.add("g");
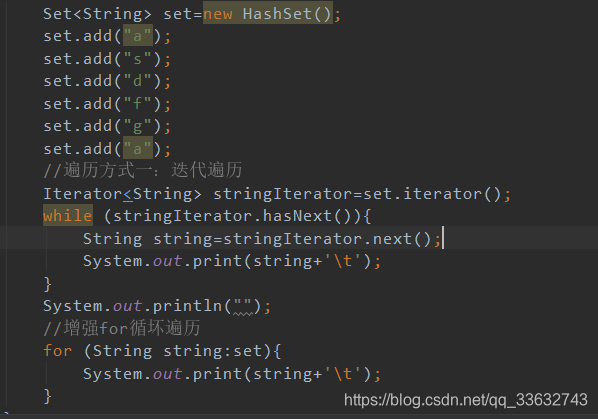
//遍历方式一:迭代遍历
Iterator<String> stringIterator=set.iterator();
while (stringIterator.hasNext()){
String string=stringIterator.next();
System.out.print(string+'\t');
}
System.out.println("");
//增强for循坏遍历
for (String string:set){
System.out.print(string+'\t');
}
}
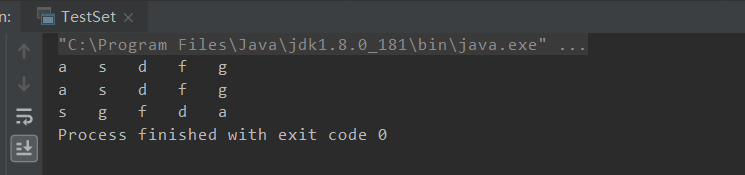
}输出结果如下
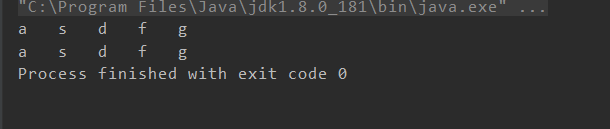
当然set是不允许存放重复元素的,当我再一次添加一个“a”进入再输出set时

输出结果仍然为一个a。
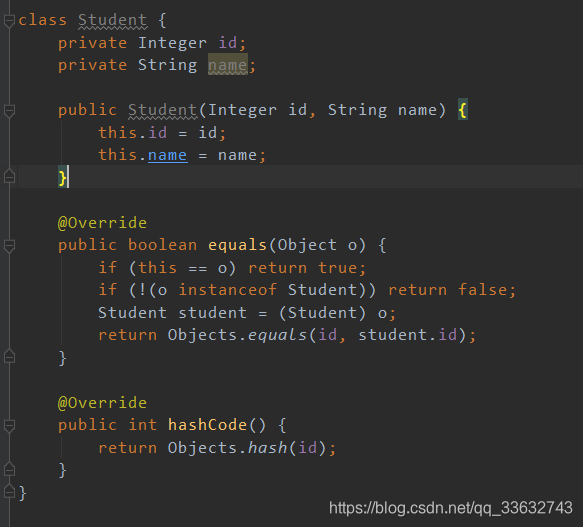
这里我们在set中存放的是一个String类型的字符串,当我们存放的是我们的自定义类时,需要在类中重写equals方法和hashCode方法。(简单说一下为什么重写equals必须重写hashcode方法,是因为重写equals时,我们会对该类中的某些属性进行判断。而为了保证equals一致hashcode也一致,故需要重写hashcode方法)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student= (Student) o;
return Objects.equals(id, Student.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
这里我重写了equals方法,其中对Student类中的id进行了比较,当这两个类的id是相同的时候,equals便返回true。而如果我们没有重写hashcode方法,则会出现hashcode不一致而equals一致的情况。(因为没重写hashcode实际上是这两个对象在jvm内存堆上的地址,两个对象的地址肯定不同)
因为往HashSet中存放元素时,默认会对两个元素进行比较,首先会比较它们的HashCode,当HashCode相同时,再进行equals比较,如果返回true则证明两个元素相同,将不对该元素进行存放,如果是false,则会进行散列,然后存放。
3.TreeSet的排序
创建方法也是通过new关键字进行创建。与HashSet的极大不同是,你可以对TreeSet的元素进行排序。
排序分为自然排序与指定排序。
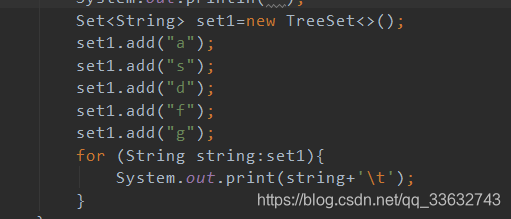
![]()
这里set1自动对集合内元素进行了升序排序。
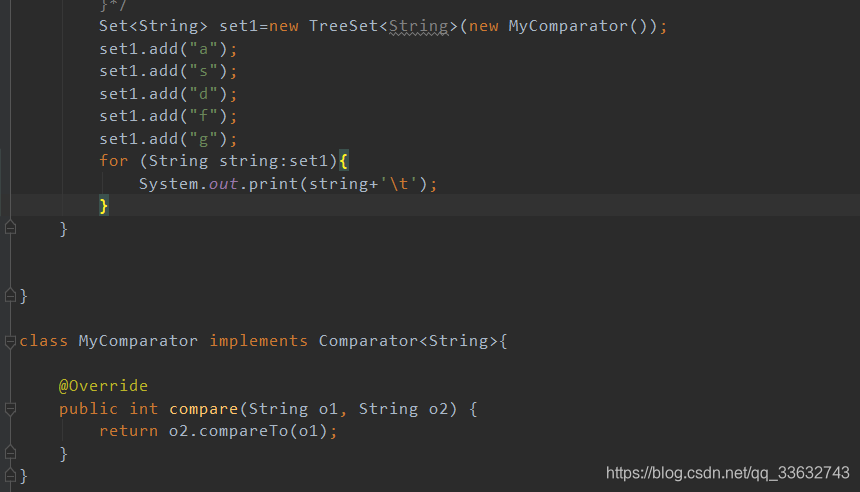
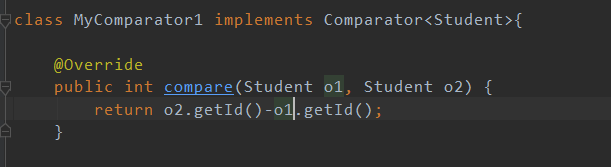
这里我定义了一个类实现Comparator接口,其中定义了以降序的方式对set1中的元素进行排序。
那么如果是我们自定义的一个类型呢?
这里我定义一个Student类:
再写一个类实现Comparator接口,以id进行排序。
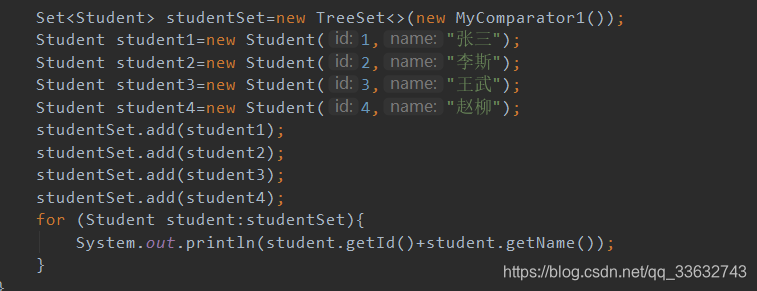
输出结果如下
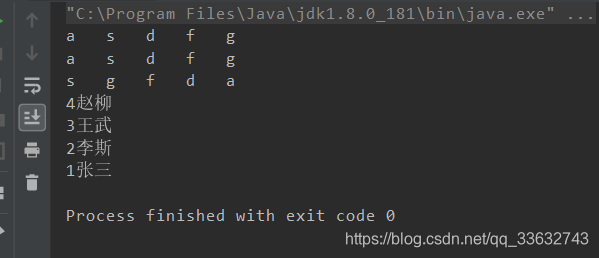
这里以id进行了降序排列。
主要是为了让自己巩固一下TreeSet。
参考博客:https://blog.youkuaiyun.com/u014649337/article/details/43734863

















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









