




前言
堆是一种特殊的树形数据结构,广泛应用于优先队列、堆排序和图算法等场景。本文旨在介绍二叉堆的基本操作,剖析其实现细节,并进一步探讨具体的应用场景。
一、二叉堆是什么?
二叉堆是堆数据结构家族中的重要成员。二叉堆实现简单,插入和删除节点高效快捷。二叉堆是一棵完全二叉树,而且每个节点的都小于其左右子节点的值(小根堆,后续指的堆都是小根堆)。
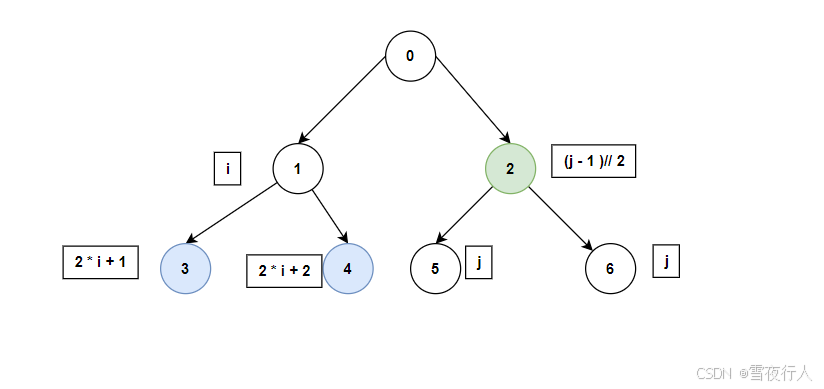
众所周知,完全二叉树的通常都用动态数组实现,其特性:
- 如果节点的索引是 (i),则其父节点的索引是 ((i - 1) // 2)。
- 如果节点的索引是 (i),则其左子节点的索引是 (2i + 1)。
- 如果节点的索引是 (i),则其右子节点的索引是 (2i + 2)。
堆的限制又是根节点和子节点值的比较,所以使用数组实现会更方便。
二、二叉堆的基本操作
1.插入
插入操作就是将新元素假如到数组尾部,然后将这个元素和父元素比较,如果比父元素小就交换二者的位置(可不立即交换,全程比较完毕再交换),如此便可将新元素放置到合适位置。
代码如下(示例):
def heappush(heap, item):
"""Push item onto heap, maintaining the heap invariant."""
heap.append(item)
_siftdown(heap, 0, len(heap)-1)
def _siftdown(heap, startpos, pos):
'Maxheap variant of _siftdown'
# Follow the path to the root, moving parents down until finding a place
# newitem fits.
while pos > startpos:
parentpos = (pos - 1) >> 1
if heap[parentpos] > heap[pos]:
heap[parentpos], heap[pos] = heap[pos], heap[parentpos]
pos = parentpos
else:
break
python的heapp 模块,其中的heappush操作和我们的说法略有不同,即我们比较两个元素后,不会立即进行交换,而是把较大元素下沉到新插入位置(新元素翻到临时空间保存),然后重复进行比较,直到最后确定不会下沉后才将新元素赋值到指定位置。
def _siftdown(heap, startpos, pos):
newitem = heap[pos]
# Follow the path to the root, moving parents down until finding a place
# newitem fits.
while pos > startpos:
parentpos = (pos - 1) >> 1
parent = heap[parentpos]
if newitem < parent:
heap[pos] = parent
pos = parentpos
continue
break
heap[pos] = newitem
python中源码down不是指的新加入元素上浮,而是堆中的元素不断下沉。
2.删除
和插入不同,删除前,先交换堆的最小元素和堆尾元素,然后就可以直接删除队尾元素。
其次取堆顶节点和左右子节点中的最小元素,然后和堆顶元素交换位置,然后以堆顶节点所在子节点位置当做开始节点,重复上述步骤,直到达到堆底即可。
代码如下(示例):
def heappop(heap):
# 交换首尾元素
heap[0], heap[-1] = heap[-1], heap[0]
# 取出最小元素
min_element = heap.pop()
down_new_item(heap, 0)
return min_element
def down_new_item(heap, pos):
# 从头开始下沉交换元素
heap_len = len(heap)
left_pos = pos * 2 + 1
right_pos = pos * 2 + 2
while left_pos < heap_len or right_pos < heap_len:
min_pos = pos
if left_pos < heap_len and heap[left_pos] < heap[min_pos]:
min_pos = left_pos
if right_pos < heap_len and heap[right_pos] < heap[min_pos]:
min_pos = right_pos
if min_pos != pos:
heap[min_pos], heap[pos] = heap[pos], heap[min_pos]
else:
break
pos = min_pos
left_pos = pos * 2 + 1
right_pos = pos * 2 + 2
为了提升性能,即减少交换操作,我们可以采用另一种更复杂的描述。
第一步还是交换。但是后续步骤则不是交换。
第二步,将新的堆顶元素保存到临时空间,然后从子节点提取较小元素填充这个位置,然后在提取孙子节点较小元素填充子节点位置,如此往复,直到空出一个叶子节点。注意:上述上浮步骤过后需要保持新堆没有违反堆性质。
第三步,将临时空间的元素赋值给空出的叶子节点,这可能会导致破会堆性质,但是也和新增步骤的操作一致,即再次调用插入方法即可调整成功。
代码如下所述:
def heappop(heap):
"""Pop the smallest item off the heap, maintaining the heap invariant."""
lastelt = heap.pop() # raises appropriate IndexError if heap is empty
if heap:
returnitem = heap[0]
heap[0] = lastelt
_siftup(heap, 0)
return returnitem
return lastelt
def _siftup(heap, pos):
endpos = len(heap)
startpos = pos
newitem = heap[pos]
# Bubble up the smaller child until hitting a leaf.
childpos = 2*pos + 1 # leftmost child position
while childpos < endpos:
# Set childpos to index of smaller child.
rightpos = childpos + 1
if rightpos < endpos and not heap[childpos] < heap[rightpos]:
childpos = rightpos
# Move the smaller child up.
heap[pos] = heap[childpos]
pos = childpos
childpos = 2*pos + 1
# The leaf at pos is empty now. Put newitem there, and bubble it up
# to its final resting place (by sifting its parents down).
heap[pos] = newitem
_siftdown(heap, startpos, pos)
从理解难易程度上来说,也是直来直往更加容易理解。
3.堆化
将一个无序数组重新构建成一个堆的过程叫做堆化,很容易,就想到从开始到末尾一个个将元素下沉到合适位置即可,可以利用 down_new_item 方法。但是,这种方法是错误的,down_new_item 是只能调整左右子树是堆的情况,不能如此调整。
那么很自然的,我们想到了从下到下,每个节点都调整一次,因为单个元素其实就是有序的堆。
def heapify(heap):
for i in range(len(heap) // 2 -1 , -1, -1):
down_new_item(a, i)
def down_new_item_recrusive(heap, i):
length = len(heap)
smallest = i
if 2 * i + 1 < length and heap[2 * i + 1] < heap[i]:
smallest = 2 * i + 1
if 2 * i + 2 < length and heap[2 * i + 2] < heap[smallest]:
smallest = 2 * i + 2
if smallest != i:
heap[i], heap[smallest] = heap[smallest], heap[i]
down_new_item_recrusive(heap, smallest)
代码中不是从末尾开始的,原因是,我们不需要从单个节点开始堆化,其实从三个节点的子树开始即可。
其中的down_new_item_recrusive 是插入操作中 down_new_item的递归写法。
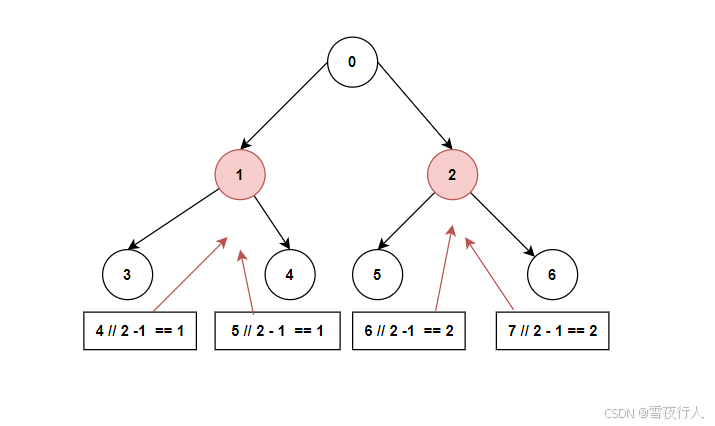
三、时间复杂度分析
插入和删除操作的时间复杂度是O(logn),这些很容易理解。因为n个节点的完全二叉树的最大高度是floor(logn) + 1,那么无论是删除还是插入移动的最大高度就是logn级别。
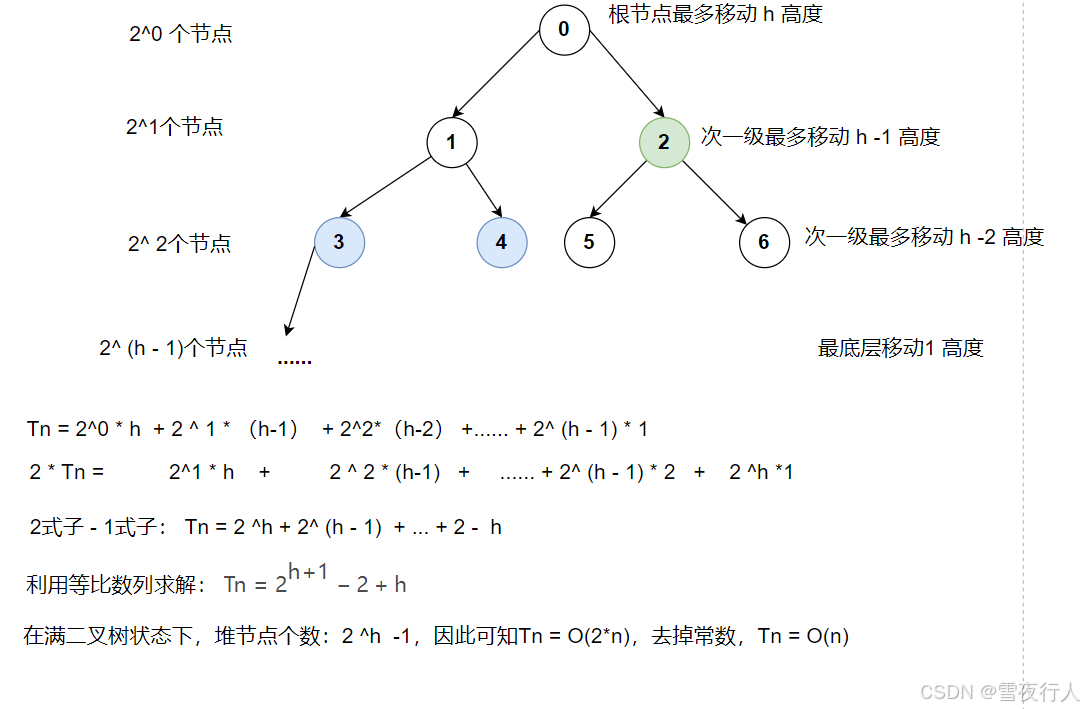
那么,初始化一个堆呢?直觉告诉我们应该是 O(n * logn),但是我们还可以进一步缩小这个上确界。
我们不要用每个节点移动的最大距离进行限制,而是研究如果每个节点是堆化了,那么最多多少步移动到这个位置?
四、应用
1.堆排序
def heap_sort(A):
heapify(A)
for i in range(len(A) - 1, -1, -1):
A[0], A[i] = A[i], A[0]
down_new_item_recrusive(A, 0, i)
2.中位数
计算一个数组的中位数,不需要将整个数组排序,而是维护一个大堆和一个小堆,而且大堆的最大值小于小堆的最小值(可以将两个堆想象成两个抛物线,一个有最大值,一个有最小值),并且两个堆最多相差一个元素。
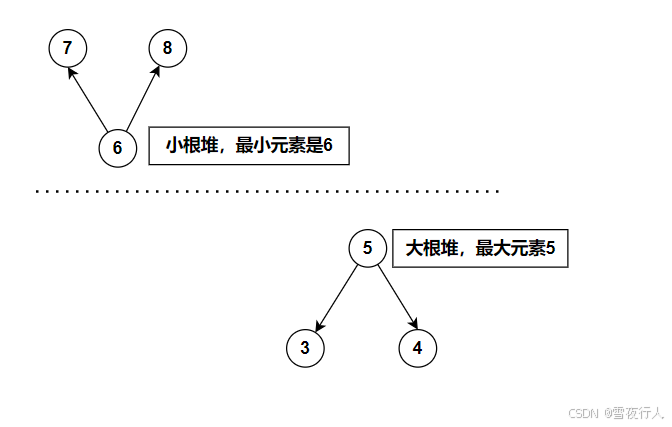
如果两个堆元素个数相等,那么,两个堆的堆顶元素的平均值即是中位数。
如果二者相差一个元素,那么多元素的堆的对顶元素即是中位数。
import heapq
def get_median(nums):
max_heap = []
min_heap = []
for num in nums:
heapq.heappush(max_heap, -num)
if len(max_heap) > len(min_heap) + 1:
heapq.heappush(min_heap, -heapq.heappop(max_heap))
# 保证min_heap的最小值大于max_heap的最大值
if min_heap and max_heap and min_heap[0] < -max_heap[0]:
min_value = heapq.heappop(min_heap)
max_value = heapq.heappop(max_heap)
heapq.heappush(min_heap, -max_value)
heapq.heappush(max_heap, -min_value)
if len(max_heap) > len(min_heap):
median = -max_heap[0]
elif len(max_heap) < len(min_heap):
median = min_heap[0]
else:
median = (-max_heap[0] + min_heap[0]) / 2
return median
a = [1,2,3,4,5,6,7,8,9]
print(get_median(a))
上述代码中在建堆过程中要维护两个要点:
1、两个堆元素个数必须相差小于等于1
2、大堆的最大值小于小堆的最小值
3.合并多个有序列表
def merge_sorted_array(arrs):
heap = []
for i, arr in enumerate(arrs):
heapq.heappush(heap, (arr[0], i, 0))
merge_list = []
while heap:
arr_value, arr_id, value_index = heapq.heappop(heap)
merge_list.append(arr_value)
if value_index + 1 < len(arrs[arr_id]):
heapq.heappush(heap, (arrs[arr_id][value_index + 1], arr_id, value_index + 1))
return merge_list
arrs = [
[1, 8, 15],
[0, 7, 14],
[-1, 6, 18]
]
print(merge_sorted_array(arrs))
合并多个有序列表要么两个两个合并,要么利用堆来合并,每次都选取K个列表的一个元素(包括元素值、列表索引、元素索引)放到堆中,然后将最小值取出,下次检查一下元素所属列表是不是还有元素,有的话就将下一个元素加入到堆中。
总结
本文介绍了二叉堆的基本信息,然后分析了堆在若干实际场景中的应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









