






1、Spark简介
Spark是基于内存计算的通用大规模数据处理框架。Spark已经融入了Hadoop生态系统,可支持的作业类型和应用场景比MapReduce 更为广泛,并且具备了MapReduce所有的高容错性和高伸缩性特点。Spark支持离线批处理、流式计算和实时分析。
2、Spark为何快
MapReduce慢的原因:
- 多个MapReduce串联执行时,依赖于HDFS输出的中间结果
- MapReduce在处理复杂的DAG(有向无环图)时会产生大量的数据序列化、数据copy和磁盘I/O开销
Spark快的原因:
- Spark基于内存,尽可能的减少了中间结果写入磁盘和不必要的sort、shuffle
- Spark对于反复用到的数据进行了缓存
- Spark对于DAG进行了高度的优化,具体在于Spark划分了不同的stage和使用了延迟计算技术
3、弹性数据分布集RDD
Spark将数据保存分布式内存中,对分布式内存的抽象理解,提供了一个高度受限的内存模型,他是逻辑上集中,物理上是存储再集群的堕胎机器上。
4、RDD的属性和特点
只读
- 通过HDFS或者其他持久化系统创建RDD
- 通过transformation将父RDD转换得到新的RDD
- RDD上保存着前后之间的依赖关系
Partition
- 基本组成单位,RDD在逻辑上按照Partition分块
- 分布在各个节点,分片个数决定并行计算的粒度
- RDD保存如何计算每个分区的函数
容错
- 失败后可自动创建
- 如果发生部分分区数据丢失,可以通过依赖关系重新计算
RDD的创建
- var lines = sc.textFile("文件路径")//sc是SparkContent对象
- lines.filter(x => x.contains("error")).count()//filter是transformation算子不触发计算,count是action算子,会触发计算
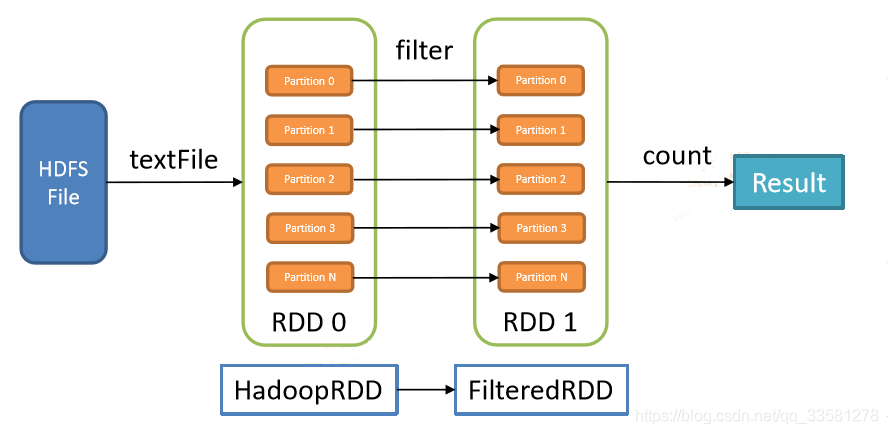
5、RDD的窄依赖和宽依赖
窄依赖:没有数据的shuffling,所有的父RDD的partition会一一映射到子RDD的partition中
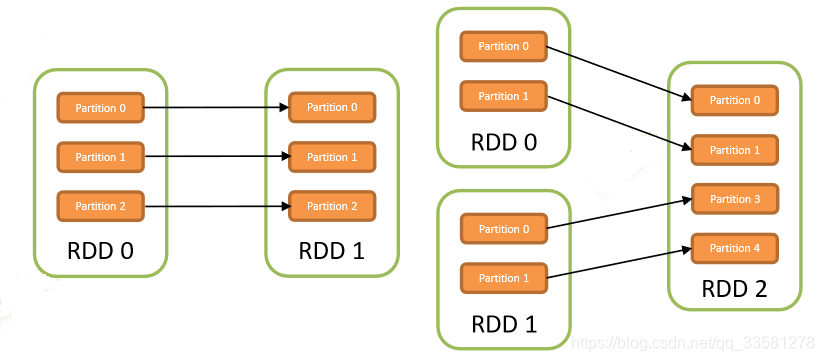
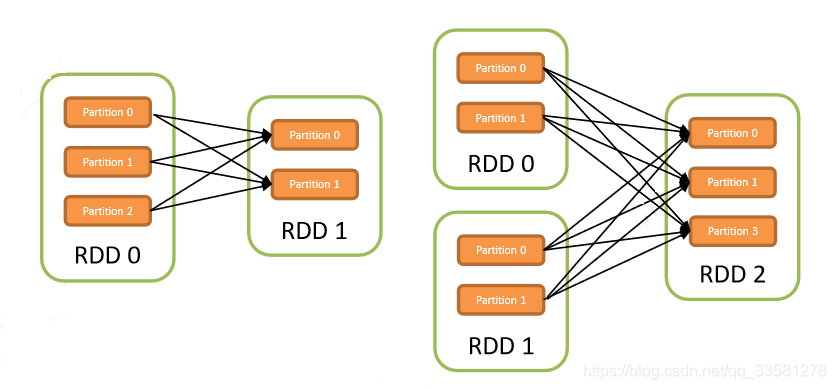
宽依赖:发生数据的shuffling,父RDD中的partition会根据key的不同进行切分,划分到子RDD中对应的partition中
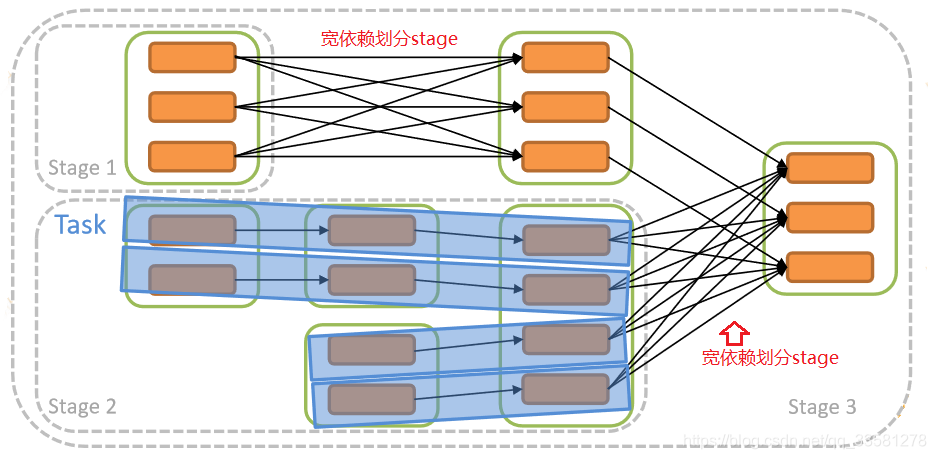
6、stage
- 什么是stage:一个job会被拆分成多组task,每组task为一个stage
- 划分依据:是否有数据shuffle,遇到宽依赖则划分一个stage,划分顺序为从后往前划分
- stage执行优化:对窄依赖进行流水线划分、相互依赖的stage必须要等到依赖的执行后再执行不依赖的可以并行执行、stage的执行成都和资源有关
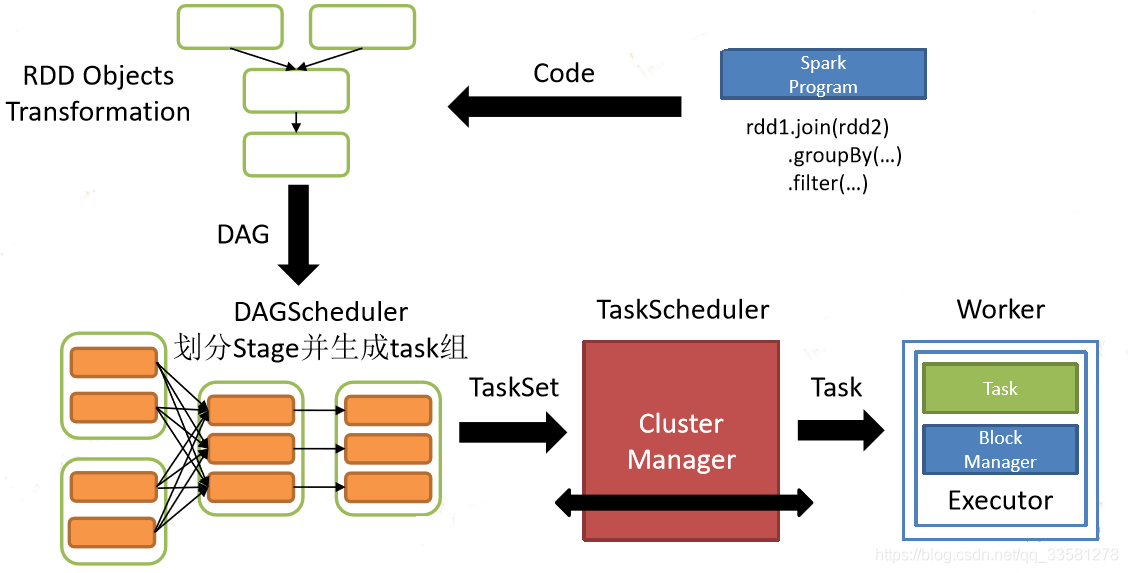
7、Spark的执行流程
- 用户创建Spark程序并提交
- 每个action会生成一个job,包含了一系列的RDD和对其如何进行操作的transformation
- 每个job生成一个DAG(有向无环图)
- DAGScheduler根据宽依赖对DAG进行划分stage并生成task组(一个stage对应一组task,一个partition对应一个task)
- Spark集群在worker上以一组Task为单位进行执行计算
8、Spark编程模型
四种类型算子:
- create:SparkContext.textFile(...)、SparkContext.parallelize(...)
- transformation:作用于一个或多个RDD,输出转换后的RDD。如:map、flatMap、filter
- action:触发RDD的执行结果,触发Spark提交作业将结果返回。如:count、countByKey
- cache:cache缓存和persist持久化
惰性运算:遇到action算子才会计算
运行Spark的方式:在CDH集群使用Spark-Shell、使用Spark-Submit提交作业
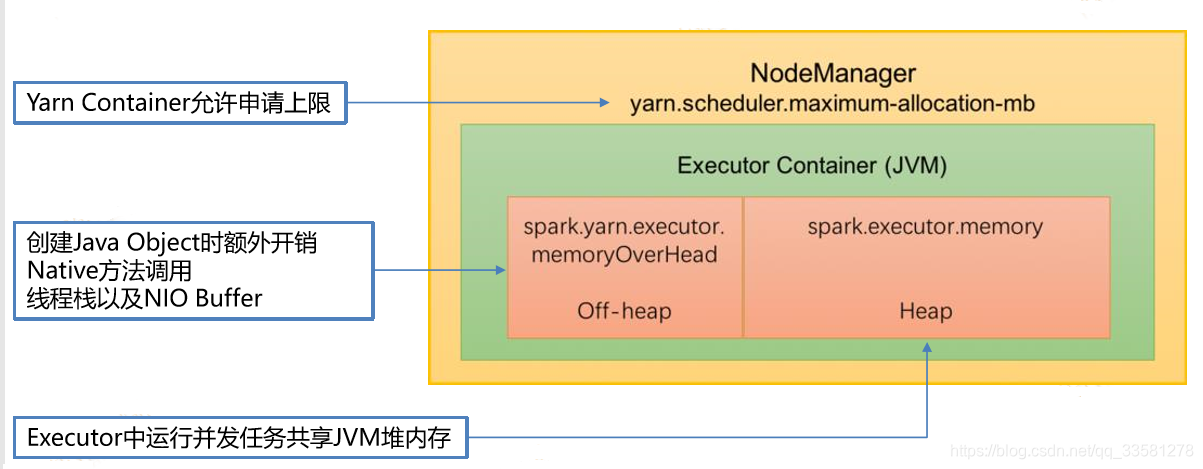
9、Spark内存结构
Spark运行在yarn中,运行内存受NodeManager管理的容器的大小限制,设置运行内存的时候,大小要小于容器的大小。Executors的内存又分为off-heap和heap,off-heap存放创建java对象的额外开销、native方法的调用和NIO Buffer,heap的大小受spark共享。
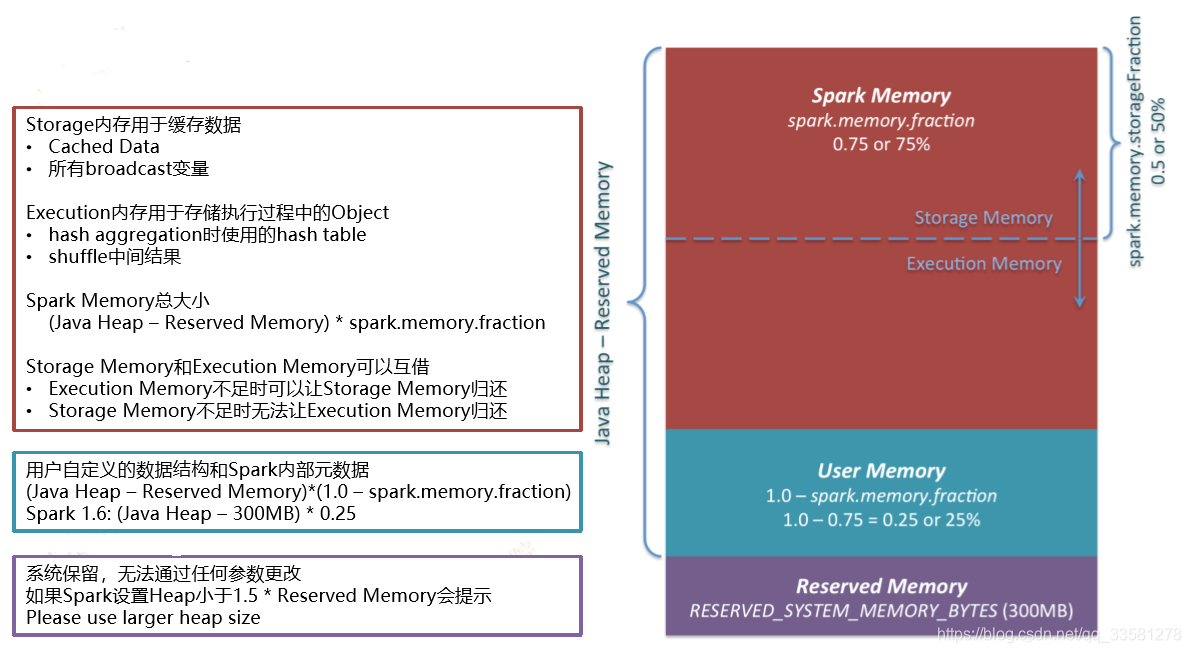
heap共享内存中可以分为三部分:reserved memory 、user memory 、Spark memory。reserved memory默认为300M,不可以比这个小;user memory存放的是用户定义的数据结构和Spark元数据,占用剩余25%;Spark memory可分为storage memory和Execution memory,两部分空间可相互借用,storage memory存储缓存的数据,Execution memory用于存储执行过程的中间object和shuff的结构。
10、面对OOM(内存溢出)问题的解决方法及优化
OOM产生原因
- Map执行中内存溢出:map执行中内存溢出代表了所有map类型的操作,包括:flatMap,filter,mapPatitions等。
- shuffle后内存溢出:shuffle后内存溢出的shuffle操作包括join,reduceByKey,repartition等操作。
内存溢出解决方法:
- map过程产生大量对象导致内存溢出:这种溢出的原因是在单个map中产生了大量的对象导致的,针对这种问题,在不增加内存的情况下,可以通过减少每个Task的大小,以便达到每个Task即使产生大量的对象Executor的内存也能够装得下。具体做法可以在会产生大量对象的map操作之前调用repartition方法,分区成更小的块传入map。例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。面对这种问题注意,不能使用rdd.coalesce方法,这个方法只能减少分区,不能增加分区,不会有shuffle的过程。
- 数据不平衡导致内存溢出:数据不平衡除了有可能导致内存溢出外,也有可能导致性能的问题,解决方法和上面说的类似,就是调用repartition重新分区。
- coalesce调用导致内存溢出:coalesce并不是shuffle操作,这意味着coalesce并不是按照我原本想的那样先执行100个Task,再将Task的执行结果合并成10个,而是从头到位只有10个Task在执行,原本100个文件是分开执行的,现在每个Task同时一次读取10个文件,使用的内存是原来的10倍,这导致了OOM。可以通过repartition解决,调用repartition(10),因为这就有一个shuffle的过程,shuffle前后是两个Stage,一个100个分区,一个是10个分区,就能按照我们的想法执行。
- shuffle后内存溢出:shuffle内存溢出的情况可以说都是shuffle后,单个文件过大导致的。在Spark中,join,reduceByKey这一类型的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism参数只对HashPartitioner有效,所以如果是别的Partitioner或者自己实现的Partitioner就不能使用spark.default.parallelism这个参数来控制shuffle的并发量了。如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
- standalone模式下资源分配不均匀导致内存溢出:在standalone的模式下如果配置了--total-executor-cores 和 --executor-memory 这两个参数,但是没有配置--executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置--executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
代码优化:
- 使用mapPartitions代替大部分map操作,或者连续使用的map操作。
- broadcast join和普通join:在大数据分布式系统中,大量数据的移动对性能的影响也是巨大的。基于这个思想,在两个RDD进行join操作的时候,如果其中一个RDD相对小很多,可以将小的RDD进行collect操作然后设置为broadcast变量,这样做之后,另一个RDD就可以使用map操作进行join,这样能够有效的减少相对大很多的那个RDD的数据移动。
- 先filter在join:这个就是谓词下推,这个很显然,filter之后再join,shuffle的数据量会减少
- groupByKey转换为reduceByKey
- 在内存不足的使用,使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache(): rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
- 在spark使用hbase的时候,spark和hbase搭建在同一个集群
参数优化:
- spark.driver.memory (default 1g):这个参数用来设置Driver的内存。在Spark程序中,SparkContext,DAGScheduler都是运行在Driver端的。对应rdd的Stage切分也是在Driver端运行,如果用户自己写的程序有过多的步骤,切分出过多的Stage,这部分信息消耗的是Driver的内存,这个时候就需要调大Driver的内存。
- spark.rdd.compress (default false) :这个参数在内存吃紧的时候,又需要persist数据有良好的性能,就可以设置这个参数为true,这样在使用persist(StorageLevel.MEMORY_ONLY_SER)的时候,就能够压缩内存中的rdd数据。减少内存消耗,就是在使用的时候会占用CPU的解压时间。
- spark.memory.storageFraction (default 0.5):这个参数设置内存表示 Executor内存中 storage/(storage+execution),虽然spark-1.6.0+的版本内存storage和execution的内存已经是可以互相借用的了,但是借用和赎回也是需要消耗性能的,所以如果明知道程序中storage是多是少就可以调节一下这个参数。
- spark.speculation (default false): 一个大的集群中,每个节点的性能会有差异,spark.speculation这个参数表示空闲的资源节点会不会尝试执行还在运行,并且运行时间过长的Task,避免单个节点运行速度过慢导致整个任务卡在一个节点上。这个参数最好设置为true。与之相配合可以一起设置的参数有spark.speculation.×开头的参数。参考中有文章详细说明这个参数。

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









