






1、基本概念
DHFS是是Hadoop最重要的核心组件 ,基于JAVA实现的一个分布式文件系统 ,基于unix/linux ,支持顺序写入,而非随机定位读写。
特点:
- HDFS适合存储大文件,单个文件大小通常在百MB以上 HDFS适合存储海量文件,总存储量可达PB,EB级 。
- 基于普通机器搭建,硬件错误是常态而不是异常,因此错误检测和快速、自 动的恢复是HDFS最核心的架构目标
- 流式数据访问 为数据批处理而设计,关注数据访问的高吞吐量
- 简单的一致性模型 一次写入,多次读取 一个文件经过创建、写入和关闭之后就不需要改变
- 将计算移动到数据附近
2、基本构成
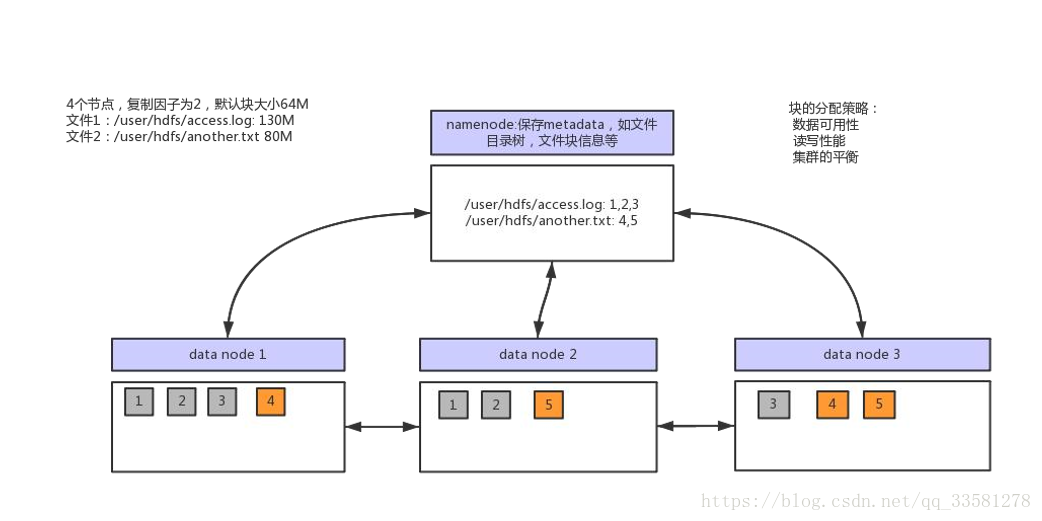
2.1、数据块
- 文件以块为单位进行切分存储,块通常设置的比较大(最小6M,默认 128M)
- 块越大,寻址越快,读取效率越高,但同时由于MapReduce任务也是以块为最小单位来处理,所以太大的块不利于于对数据的并行处理
- 一个文件至少占用一个块(逻辑概念)
2.2、Namenode与Datanode
- namenode 负责维护整个文件系统的信息,包括:整个文件树,文件的块 分布信息,文件系统的元数据,数据复制策略等
- datanode 存储文件内容,负责文件实际的读写操作,保持与namenode的 通信,同步文件块信息
3、数据读写过程
HDFS写数据:
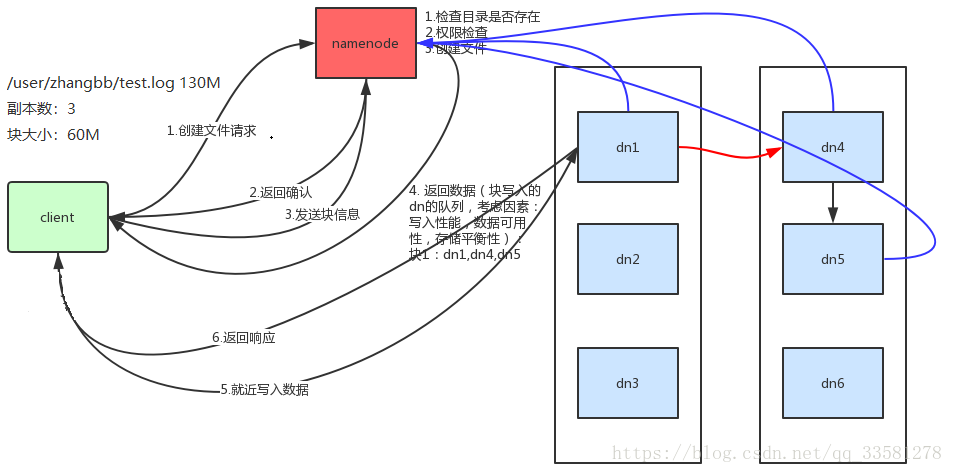
- 客户端发起写请求,nameNode检验写入目录是否存在,是否有写入权限,如果目录不存在且有写权限,则创建文件,告知客户端可以写入
- 客户端发送块信息(写入的文件根据块大小切分的块个数)到nameNode,nameNode返回写入dataNode的队列,返回的dataNode需要考虑的因素写入性能(尽可能的靠近客户端即队列的第一个节点离客户端较近)、数据可用性(至少有两个机架存放数据)和存储平衡(分布在不同的dataNode)
- 根据dataNode队列就近写入数据,当第一个写完即返回成功(也可以设置都写入成功后返回),其余通过管道方式进行写入,每个节点写完后想nameNode汇报各个节点的写入状态,保证每个块的副本数一致。
HDFS读文件:
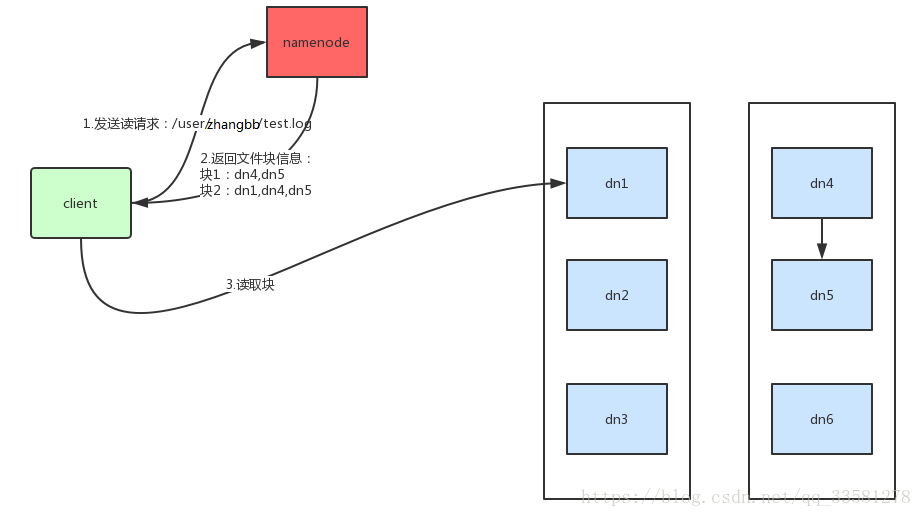
客户端发起读请求,nameNode检查目录是否存在、是否有权限,nameNode返回文件的块信息,返回块信息(块对应的dataNode的队列,保证当dataNode挂的时候可以正常读取数据),客户端根据块信息读取文件。
3、nameNode介绍
3.1、作用
- Namespace管理:负责管理文件系统中的树状目录结构以及文件与数据块 的映射关系
- 块信息管理:负责管理文件系统中文件的物理块与实际存储位置的映射关系BlocksMap
- 集群信息管理:机架信息,datanode信息
- 集中式缓存管理:从Hadoop2.3 开始,支持datanode将文件缓存到内存中, 这部分缓存通过namenNode集中管理
3.2、存储结构
- 内存: Namespace数据,BlocksMap数据,其他信息
- 文件:已持久化的namespace数据:FsImage;未持久化的namespace操作:Edits
3.3、启动过程
- 开启安全模式:不能执行数据修改操作
- 加载fsimage
- 逐个执行所有Edits文件中的每一条操作将操作合并到fsimage加载到内存,完成后生 成一个空的edits文件
- 接收datanode发送来的心跳消息和块信息
- 根据以上信息确定文件系统状态
- 退出安全模式
3.4、Secondary NameNode介绍
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。当nameNode启动后,系统不断的想edits文件中写入信息,edits文件会变的很大。在这种情况下就会出现下面这些问题:
- edits文件会变的很大,如何去管理这个文件?
- NameNode的重启会花费很长的时间,因为有很多改动要合并到fsimage文件上。
- 如果NameNode宕掉了,那我们就丢失了很多改动,因为此时的fsimage文件时间戳比较旧。
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edits文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。而Secondary NameNode就是为了帮助解决上述问题提出的,它的职责是合并NameNode的edits到fsimage文件中。
Secondary NameNode合并edits到fsimage的过程:
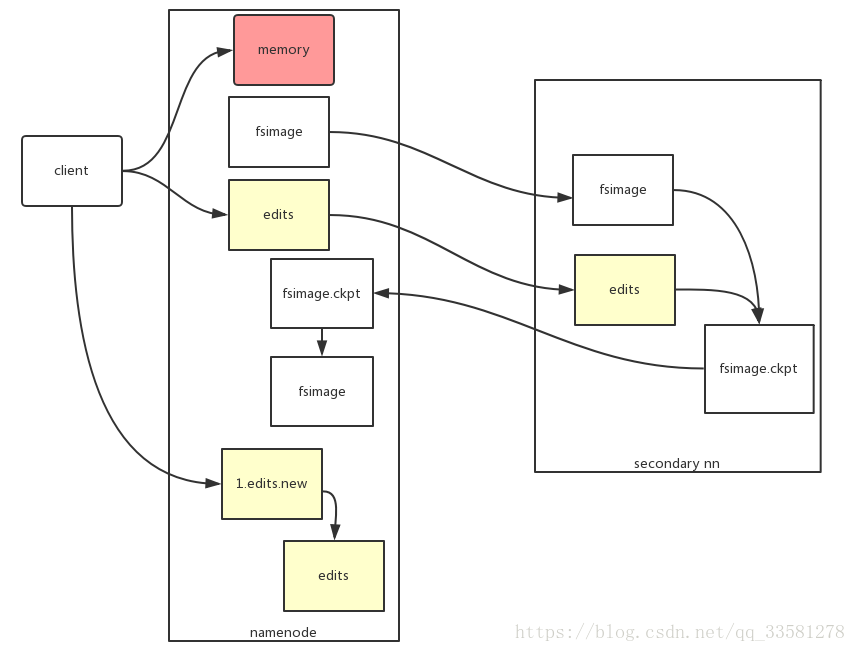
Secondary NameNode所做的是在文件系统这设置一个Checkpoint来帮助NameNode更好的工作;它不是取代NameNode,也不是NameNode的备份。
Secondary NameNode的检查点进程启动,是由两个配置参数控制的(CDH中也可以进行配置):
- fs.checkpoint.period,指定连续两次检查点的最大时间间隔, 默认值是1小时。
- fs.checkpoint.size定义了edits日志文件的最大值,一旦超过这个值会导致强制执行检查点(即使没到检查点的最大时间间隔)。
3.5、Namenode管理
大数据量下的namenode问题
- 启动时间变长
- 性能开始下降
- NameNode JVM FGC风险较高
解决方案
- 根据数据增长情况,预估namenode内存需求,提前做好预案
- 使用HDFS Federation,扩展NameNode分散单点负载
- 引入外部系统支持NameNode内存数据
- 合并小文件
- 调整合适的BlockSize
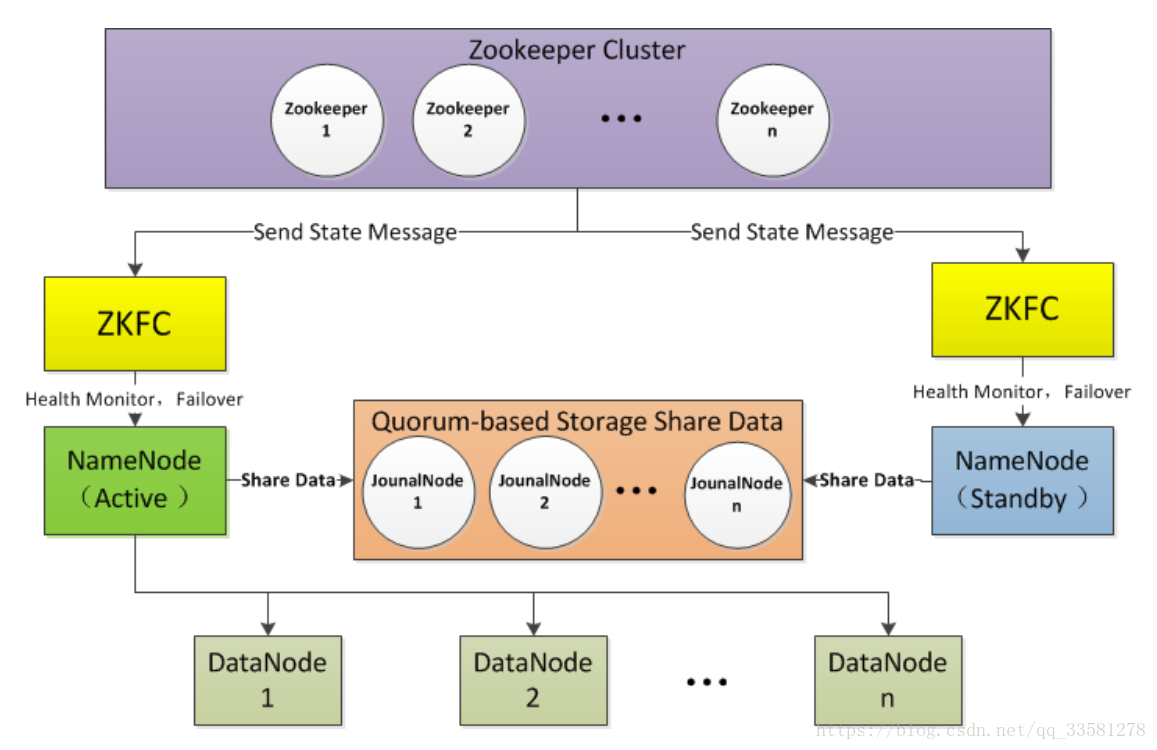
4、HDFS的高可用方案
通过zookeeper以QJM(quorum journal manager)实现高可用,可以手动进行配置也可以通过CDH启用高可用方案。
edits文件存放于journalNode中,有两个nameNode,一个处于活跃状态(active),一个处于待命状态(standby),只有活跃的nameNode可以提供HDFS服务并向journalNode中写入edits,待命状态的nameNode负责同步journalNode中的数据,各个dataNode节点活跃态的nameNode报告状态(心跳信息、块信息)。2个nameNode和journalNode保持通信,待命的节点与活跃态的nameNode的数据保持一致,当活跃态的nameNode不可用时,zookeeper会把standby节点自动变为active状态,继续对外提供读写服务。
5、HDFS的文件格式和文件类型
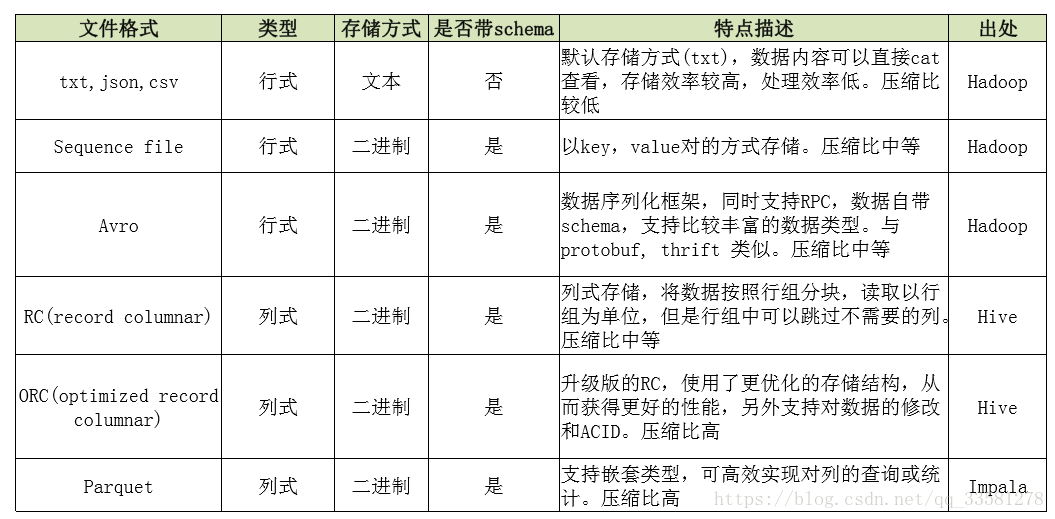
文件格式:HDFS支持任意格式的文件
文件类型:行式存储和列式存储
5.1、行式和列式的比较
- 行式按行进行存储一个block存储一或多行数据;列式按列进行存储一个block可能有一列或多列数据。
- 行式压缩时由于数据类型不一致,压缩比较差;列式按列压缩由于每列的数据是一致的,压缩比较强。
- 行式执行查询时,查询部分字段,需要遍历整张表,查询数据较大,效率低;列式则只需要找对应的列即可,数据量较小,效率高。
5.2、小文件
每个文件的元数据对象约占150byte,所以如果有1千万个小文件, 每个文件占用一个block,则NameNode大约需要2G空间。如果存储1亿 个文件,则NameNode需要20G空间;数据以块为单位进行处理。
影响:占用资源,降低处理效率
解决方案:
- 从源头减少小文件
- 使用archive打包
- 使用其他存储方式,如Hbase,ES等

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









