






一、MapReduce概述
1、MapReduce定义
MapReduce是一个分布式计算框架,将用户编写的业务代码和自带默认组件组成一个完整的分布式运算程序,并运行在一个Hadoop集群上。
2、优点
- 易于编程:简单的实现和继承类就可以编写自己的业务代码,运行在集群中,就可实现分布式计算
- 扩展性:可以通过简单的增加机器来完成对集群的扩展
- 高容错:任务分别在不同的机器运行,单个任务的失败会进行重试,失败重试完全由集群负责,不用人工参与
- 适合海量数据的计算:上千台机器运行任务,实现海量数据的计算
3、缺点
- 不擅长实时计算:MapReduce计算耗时比较长
- 不擅长流式计算:流式计算数据是动态的,而MapReduce的数据是静态的
- 不擅长DAG:计算类型单一,不支持向量机和斐波那契数列
4、核心编程思想
MapReduce分为两个部分,MapTask和ReduceTask;MapTask为并行运行,互不相干;ReduceTask并行互不相干,但是运行需要依赖MapTask的运算结果,将MapTask的运算结果进行整合。
5、常用数据类型
| Java类型 | Hadoop Writable类型 |
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
Hadoop内部通信协议是RPC,进行数据通信传输数据要进行序列化和反序列化,所以Hadoop的数据类型都是实现了Writeable序列化接口的。
6、序列化
将java对象序列化成字节对象称为序列化,将字节对象转化为java对象称为反序列化。java自带的序列化框架太重不好用,Hadoop自己实现了一套Writable框架。
序列化步骤如下:
1、实现Writable接口,必须有空参构造方法
2、重写序列化和反序列化方法。(字段顺序必须一致)
//序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
3、bean对象要放在key的位置需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
@Override
public int compareTo(FlowBean flowBean) {
return Long.compare(flowBean.sumFlow,this.sumFlow);
}7、Mapreduce编码规范和WordCount实例
- mapper阶段:继承mapper类,实现map方法,输入和输出都是KV数据,循环调用map方法,把当前块的数据一行一行处理
- reduce阶段:继承reduce类是按reduce方法,把map阶段处理的数据,相同的key调用一次reduce方法
- driver:封装mapreduce的配置和业务代码,向yarn提交当前任务
代码案例:
//mapper
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
private static Text text = new Text();
private static IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word: words) {
this.text.set(word);
context.write(text,one);
}
}
}
//reduce
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
private static IntWritable count = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value:values) {
sum = sum + value.get();
}
this.count.set(sum);
context.write(key,count);
}
}
//driver
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hadoop101:8020");
configuration.set("mapreduce.framework.name","yarn");
configuration.set("mapreduce.app-submission.cross-platform","true");
configuration.set("yarn.resourcemanager.hostname","hadoop102");
configuration.set("mapred.job.queue.name","hive");
//1、获取job对象
Job job = Job.getInstance(configuration);
//2、设置执行的的类
// job.setJarByClass(WordCountDriver.class);
job.setJar("D:\\ideaWorkspace\\hdfs0105\\target\\hdfs0105-1.0-SNAPSHOT.jar");
//3、设置mapper和reduce
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//4、设置mapper和reduce的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//5、设置job的输入和输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//6、提交job
boolean b = job.waitForCompletion(true);
System.exit(true?0:1);
}
}二、框架原理
1、Inputformat输入
- map的切片是按文件进行切分,切片的大小一般为块的大小,切片的数量决定了任务的并行度
- job的提交流程:建立连接->提交job->获取提交路径->获取jobid和job路径->拷贝jar包->生成切片信息->生成配置信息->返回提交状态
- CombineTextInputFormat切片机制,适用于小文件场景,将小文件的大小和最大切片文件做比较,小于则不切,大于并且小于两倍,则平均切为两份。
- FileInputFormat实现类分别为TextInputFormat(文本)、KeyValueInputFormat(kv对,指定分割符)、NLineINputFormat(行)、CombineTextInputFormat(处理小文件)和自定义InputFormat
2、MapReduce工作流程
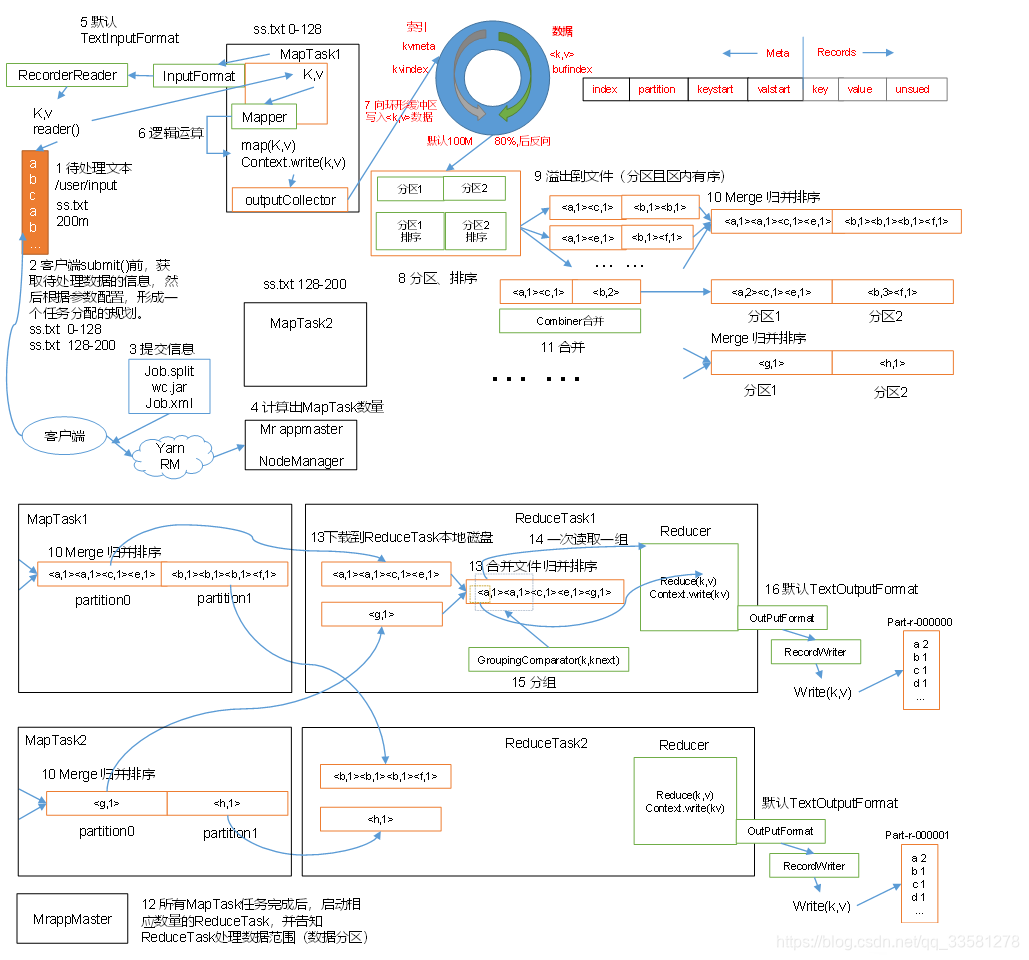
maptask读取需要处理的数据,把输出结果写入到缓冲区内,缓冲区区内数据不断溢写,形成小文件,在溢写的过程中调用partition方法进行分区和排序,最终多个小文件合merge成一个大文件提供reducetask处理,reducetask根据自己的分区号分别去maptask形成的大文件拉取自己的数据,reduce将自己分区的数据进行分组、排序合并形成最终的结果
3、Shuffle机制(map方法之后,reduce方法之前)
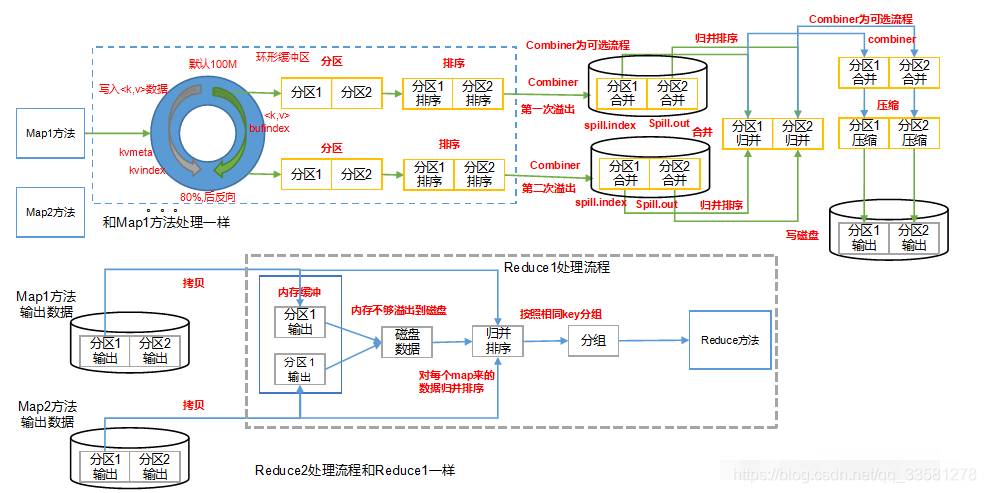
- map方法结束后,调用getpartition方法,标记数据是属于那个分区,写入环形缓冲区内
- 环形缓冲区内双向存储,一侧存数据,一侧存索引,当环形缓冲区内数据到达80%的时候进行溢写
- 边溢写边排序形成很多溢写文件,多个溢写文件进行归并排序,形成一个大文件和索引文件
- reducetask拉取自己分区的数据,首先将数据放入内存中,内存不够放磁盘上,并对数据进行归并排序和分组,把数据写入到reduce方法
优化:
- 环形缓冲区大小调整为200整,阈值为90
- 对溢写文件提前进行combiner,只对结合律使用
- 提高meger溢写文件的个数,默认10个
- 对shuffle的中间数据进行压缩
- reducetask拉取的maptask数据个数调整。默认5个
- 调整reducetask的内存
- 调整nodemanager和单任务的内存,maptask和redcetask的内存不要超过6G
三、数据压缩
由于在MapReduce计算任务中,存在大量的IO开销,压缩可以减少IO,加快整个集群的运算速度。在Map输入端对数据有要求,必须为可以切分的数据,目前支持切分的压缩为LZO和Bzip2,而LZO要支持压缩必须为文件创建索引。由于snappy压缩最快,所以在shuffer阶段常用的压缩算法为snappy,用lzo也是可以的。在选择时也必须考虑计算的类型,如果是IO密集型考虑加压缩,计算密集型则不用考虑压缩,加上压缩反而会影响效率。
| 压缩格式 | hadoop自带? | 算法 | 文件扩展名 | 是否可切分 | 换成压缩格式后,原来的程序是否需要修改 |
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









