







 本文介绍了使用Python3进行豆瓣短评爬取的步骤,包括安装必要的库requests、lxml、openpyxl和pandas,通过XPath解析网页,抓取并保存评论数据到Excel文件中。通过分析网页源代码,提取出评论内容的XPath表达式,最终成功生成了comments.xlsx文件。
本文介绍了使用Python3进行豆瓣短评爬取的步骤,包括安装必要的库requests、lxml、openpyxl和pandas,通过XPath解析网页,抓取并保存评论数据到Excel文件中。通过分析网页源代码,提取出评论内容的XPath表达式,最终成功生成了comments.xlsx文件。
采用工具pyCharm,python3,工具的安装在这就不多说了,之所以采用python3是因为python2只更新维护到2020年。
-
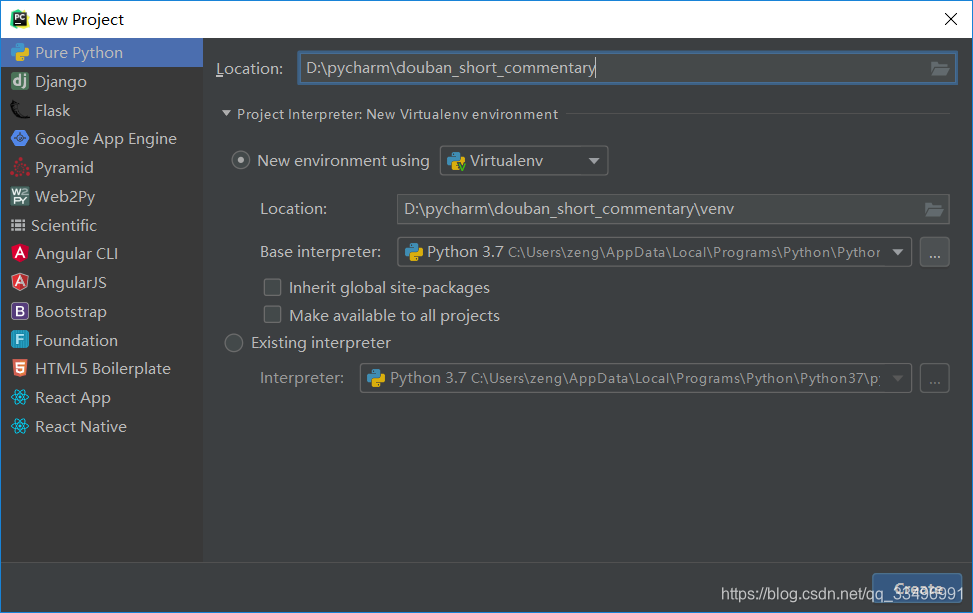
新建python项目
-
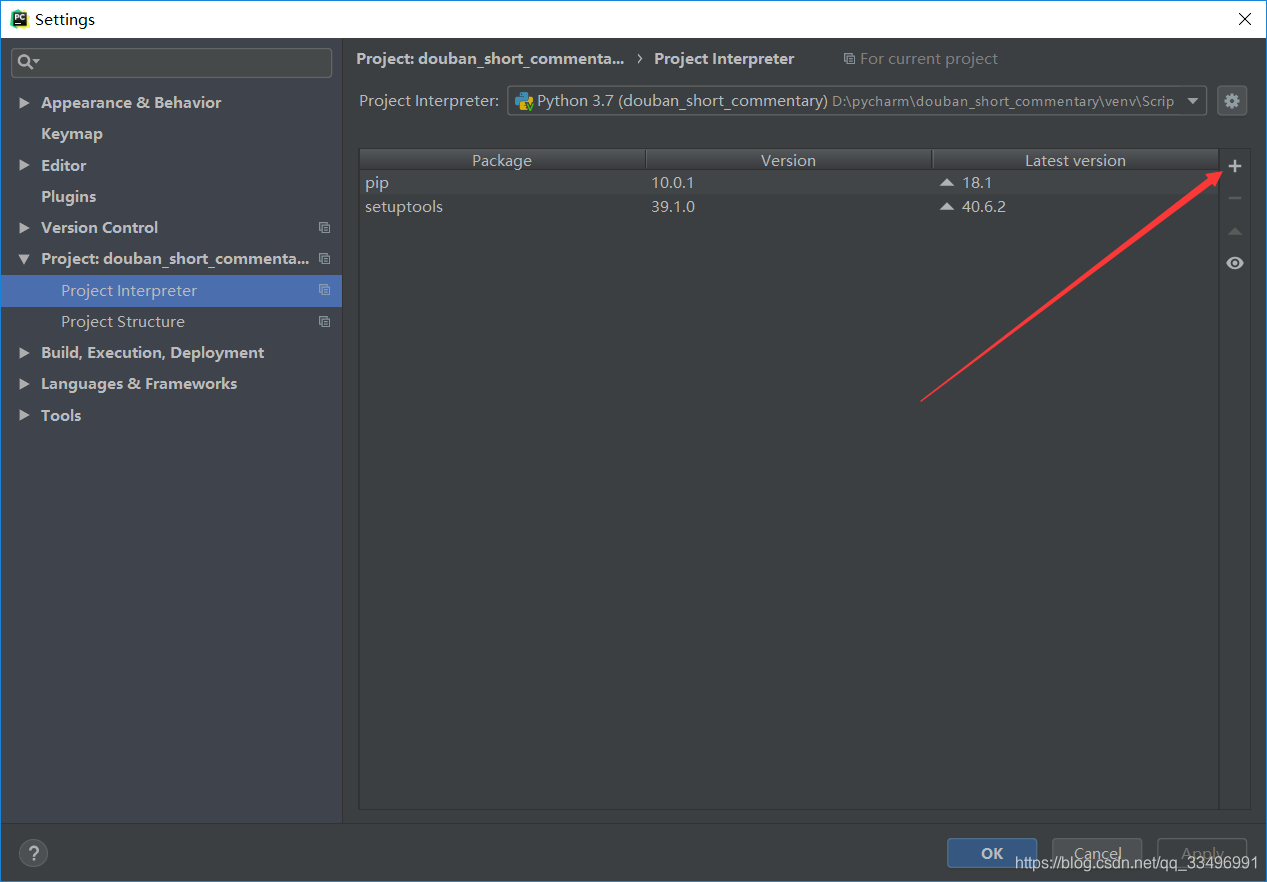
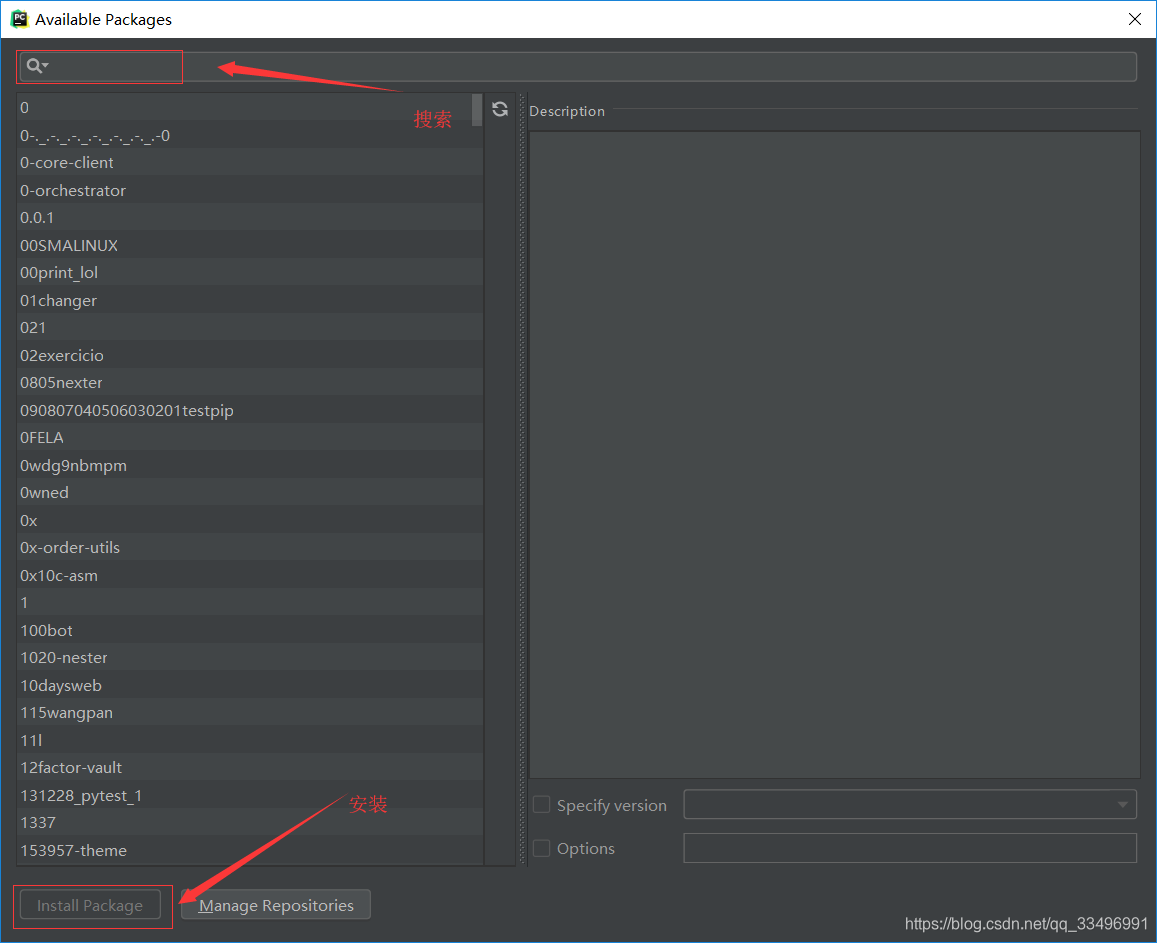
File-Settings-project interpreter,点右上角+号,安装requests,lxml,openpyxl,pandas四个包。
requests爬取豆瓣短评
lxml解析定位豆瓣短评
panda转换并保存豆瓣短评数据
openpyxl是读写excel文件所用到的包
-
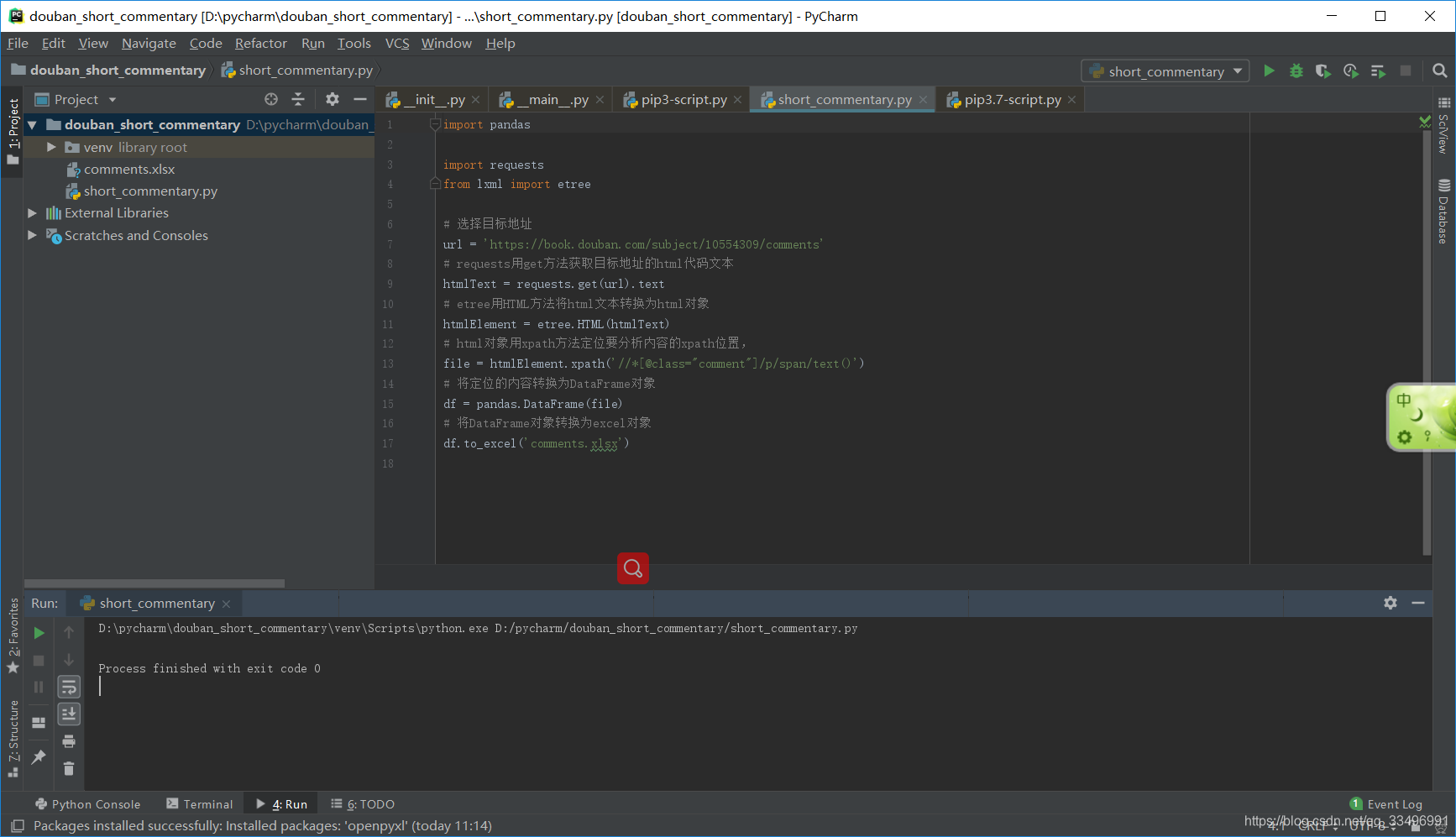
在项目下新建一个python file,实例代码如下:
-
这里着重说一下,xpath路径如何获取,在网页中选中评论内容,右击-检查,自动跳到对应代码行,再在该代码行上右击-Copy-Copy XPath;粘贴出来你的代码好比如是://[@id=“comments”]/ul[1]/li[1]/div[2]/p/span,这时你要结合你的前端基础知识和页面世界节点去分析,最后把xpath改成//[@class=“comment”]/p/span/text()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









