







DataStream API 流数据处理
流处理基本流程
UDF (User-Defined Functions)函数形式编程
Flink 中 UDF 无处不在,所有接口几乎都实现了 Function 函数接口,支持 Lambda 表达式,匿名函数类,自定义函数类。大多数操作都需要用户定义的函数。
在 Flink 中有四种指定用户自定义函数类的方式:
- Implementing an interface 实现 Flink 提供的函数类接口
- Anonymous classes 使用匿名类
- Java 8 Lambdas 使用 Lambda 表达式
- Extends Rich functions 继承 Flink 中提供的富函数类
Rich functions provide, in addition to the user-defined function (map, reduce, etc), four methods: open, close, getRuntimeContext, and setRuntimeContext. These are useful for parameterizing the function (see Passing Parameters to Functions), creating and finalizing local state, accessing broadcast variables (see Broadcast Variables), and for accessing runtime information such as accumulators and counters (see Accumulators and Counters), and information on iterations (see Iterations).
重要作用:
- 参数化函数类:即可以想函数类传递参数
- 创建和完成本地状态
- 访问广播变量
- 访问运行时信息,例如计数器
- 访问迭代信息
Data Source 数据源算子
原理
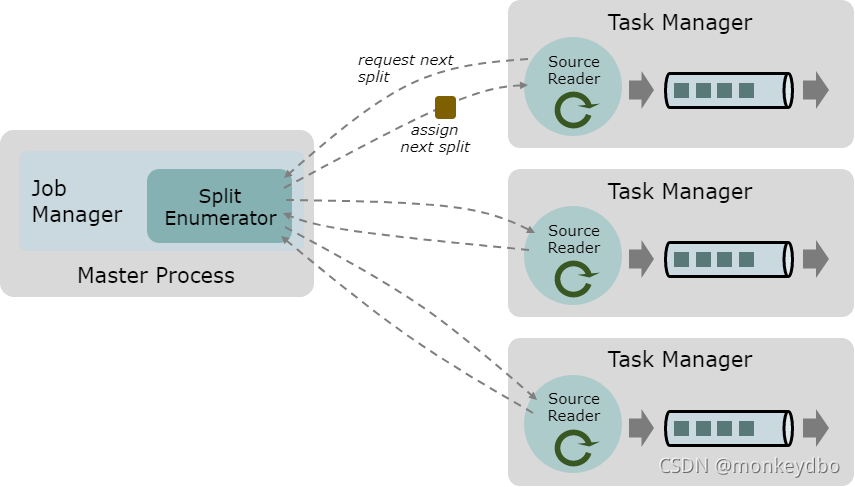
核心组件:Splits(分区), SplitEnumerator(分区枚举器), SourceReader(数据源读取器)
-
Splits(分区)
-
表示消耗数据源的一个部分,是数据源分配work和并行读取数据的粒度
例如:一个目录下有多个文件,文件就可以作为这样的一个粒度;kafka 的 topic 也可以作为分配work和并行读取数据划分粒度
SplitEnumerator(分区枚举器)
- 产生 Split 分区,并将 split 分区分配给 SourceReader(数据源读取器)。SplitEnumerator 在 JM 中单例运行 SourceReader(数据源读取器)
- 请求一个数据源 split 分区,并处理分区中的数据。SourceReader 在 SourceOperators(数据源算子)中的 TaskManager 上并行运行(即 每一个 SourceReader 在不同的 TaskSlot 中),并生成并行的流。
简单数据源
-
集合中获取流数据
DataStream<UserClickRecord> streamSource = environment.fromCollection(Arrays.asList(···)) environment.fromElements(···) -
文件流
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> streamSource = environment .readTextFile("filePath") -
Socket 中获取
DataStreamSource<String> streamSourceFromSocket = executionEnvironment .socketTextStream("192.168.116.100", 9999); -
从 Kafka 获取数据流
<!-- 连接器依赖 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency>Properties properties = new Properties(); properties.setProperty("bootstrap.servers", kafkaServers); properties.setProperty("group.id", groupId); DataStream<Object> streamSource = environment.addSource( new FlinkKafkaConsumer<Object>(topic, (DeserializationSchema) new SimpleStringSchema(), properties));以上 1、2、3 时 Flink 内置的,4 需要引入 Kafka 连接器,其他连接器使用类似
自定义数据源
目的:更细粒度的控制数据源
应用:
-
- 模拟真实无界流数据的输入,常用于构建测试数据源
-
- 数据源分区控制
Transform Operators 数据流转换算子
基础转换算子
- map
- flatMap
- filter
/**
* <p> 基本数据流转换算子示例 map flatmap filter</p>
*
* @author hubo
* @since 2021/11/3 21:36
* 启动参数:
*/
public class BasicTransformTest {
public static void main(String[] args) throws Exception {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String testInputFilePath = parameterTool.get("file.path");
testInputFilePath = testInputFilePath == null ?
"E:\\Projects\\bigdata\\flink\\flink-study\\demo01\\src\\main\\resources\\userclickrecordtempdata.txt":
testInputFilePath;
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream dataSource = executionEnvironment.readTextFile(testInputFilePath);
/*
* 1. Map 算子
* Takes one element and produces one element. 获取一个元素并生成一个元素。
* DataStream → DataStream
* 例如:将获得的 String 转换成 POJO 实体对象,并将 label 设置成 0
**/
SingleOutputStreamOperator mapOutputStreamOperator = dataSource.map((MapFunction<String, UserClickRecord>) line -> {
String[] lineIrems = line.split(",");
UserClickRecord record = new UserClickRecord(lineIrems[0],
lineIrems[1],
lineIrems[2],
lineIrems[3],
lineIrems[4]);
record.setLabel("0");
return record;
});
mapOutputStreamOperator.print("mapOpt");
/*
* 1. FlatMap 算子
* Takes one element and produces zero, one, or more elements. 获取一个元素并生成零个或一个或多个元素。
* DataStream → DataStream
* 例如:将获得的 String 转换成 POJO 实体对象,再提前里面的数据特征,把数据特征分成产品特征和用户特征输出(假设前 5 个是商品的特征)
**/
SingleOutputStreamOperator flatMapOutputStream = dataSource.flatMap((FlatMapFunction<String, List<Double>>) (line, out) -> {
String[] lineIrems = line.split(",");
UserClickRecord record = new UserClickRecord(lineIrems[0], lineIrems[1], lineIrems[2], lineIrems[3], lineIrems[4]);
String features = record.getFeatures();
String[] featureArr = features.split(" ");
ArrayList<Double> goodsFeatures = new ArrayList<>();
ArrayList<Double> userFeatures = new ArrayList<>();
for (int i = 0; i < featureArr.length; i++) {
if (i < 5) {
goodsFeatures.add(Double.parseDouble(featureArr[i]));
} else {
userFeatures.add(Double.parseDouble(featureArr[i]));
}
}
out.collect(goodsFeatures);
out.collect(userFeatures);
});
flatMapOutputStream.print("flatOpt");
/*
* 1. Filter 算子
* Evaluates a boolean function for each element and retains those for which the function returns true.
* 保留该函数返回true的元素,不可以改变输入的数据类型
* DataStream → DataStream
* 例如:将获得的 String 解析成 POJO 实体对象,再判断 Label 的值,为 1 时输出
**/
SingleOutputStreamOperator filterOutputStreamOperator = dataSource.filter((FilterFunction<String>) line -> {
String[] lineIrems = line.split(",");
UserClickRecord record = new UserClickRecord(lineIrems[0], lineIrems[1], lineIrems[2], lineIrems[3], lineIrems[4],lineIrems[5]);
if ("1".equals(record.getLabel())) {
return true;
}
return false;
});
filterOutputStreamOperator.print("filterOpt");
executionEnvironment.execute("BasicTransformTestJob");
}
}
UserClickRecord 时自定义的数据类型,可以在文末源码地址中获取
数据流基础分组算子
- KeyBy
- Reduce
- Window\WindowAll - WindowApply/WindowReduce
/**
* <p> 数据流分组转换测试 </p>
*
* @author hubo
* @since 2021/11/4 19:37
*/
public class GroupTransformTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> inputStream = executionEnvironment
.readTextFile("E:\\Projects\\bigdata\\flink\\flink-study\\demo01\\src\\main\\resources\\userclickrecordtempdata.txt");
// 想利用基本转换将接收到的数据装欢为 POJO 对象
SingleOutputStreamOperator<UserClickRecord> objectStreamSource = inputStream.map((MapFunction<String, UserClickRecord>) line -> {
String[] lineIrems = line.split(",");
UserClickRecord record = new UserClickRecord(lineIrems[0],
lineIrems[1],
lineIrems[2],
lineIrems[3],
lineIrems[4],
lineIrems[5]);
return record;
});
/*
* 1. KeyBy
* 从逻辑上将流划分为不相交的分区。 DataStream → KeyedStream
* key相同的记录会被分到同一个分区
* 通过分割数据的 Hash 值实现
* 实例:将用户点击记录根据 Label 标签分区,同一个区表示会进到用一个 TaskSlot 中
**/
KeyedStream<UserClickRecord, String> keyedStream = objectStreamSource.keyBy(
(KeySelector<UserClickRecord, String>) value -> value.getLabel());
keyedStream.print("UserClickRecordKeyedStream");
/*
* 2. Reduce
* KeyedStream 流数据上的记录会按照分区,新来的数据回合之前的数据做合并,然后产生新的值。 KeyedStream → DataStream
* 效果就像来一个消失一个
* 实例:将前面 keyedStream 中的记录按照分区把 uuid 拼接起来(没有实际含义,做实验)
**/
SingleOutputStreamOperator<UserClickRecord> reduceResultSource = keyedStream.reduce((ReduceFunction<UserClickRecord>) (value1, value2) -> {
// ur1 先到的数据,ur2 时后来的数据,会
String uuid1 = value1.getUuid();
value1.setUuid(uuid1 + "," + value2.getUuid());
return value1;
});
reduceResultSource.print("reduceResultSource");
/*
* 3. Window 可以在已分区的KeyedStreams上定义窗口。
* KeyedStream → WindowedStream
* WindowAll
* DataStreamStream → AllWindowedStream
* 4. Window Apply
* WindowedStream → DataStream ||||||| AllWindowedStream → DataStream
**/
WindowedStream<UserClickRecord, String, TimeWindow> windowStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(1)));
SingleOutputStreamOperator<Object> windowApplyStream = windowStream.apply(new WindowFunction<UserClickRecord, Object, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<UserClickRecord> input, Collector<Object> out) throws Exception {
StringBuffer uuids = new StringBuffer("");
for (UserClickRecord record : input) {
uuids.append("," + record.getUuid()) ;
}
out.collect(uuids.toString());
}
});
windowApplyStream.print("windApply");
executionEnvironment.execute("GroupTransformTestJob");
}
}
简单时间窗口算子

滚动时间窗口 Tumbling Windows
特点:
- 元素只出现在一个窗口中
- 窗口无重叠
- 窗口只需要一个参数
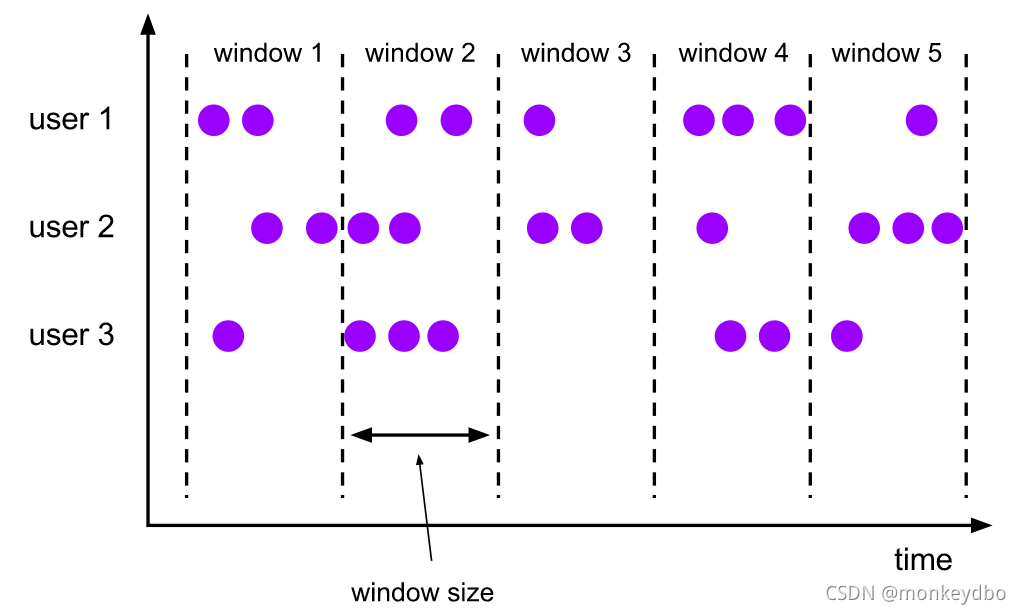
滚动窗口时特殊的滑动窗口,窗口大小等于滑动步长。
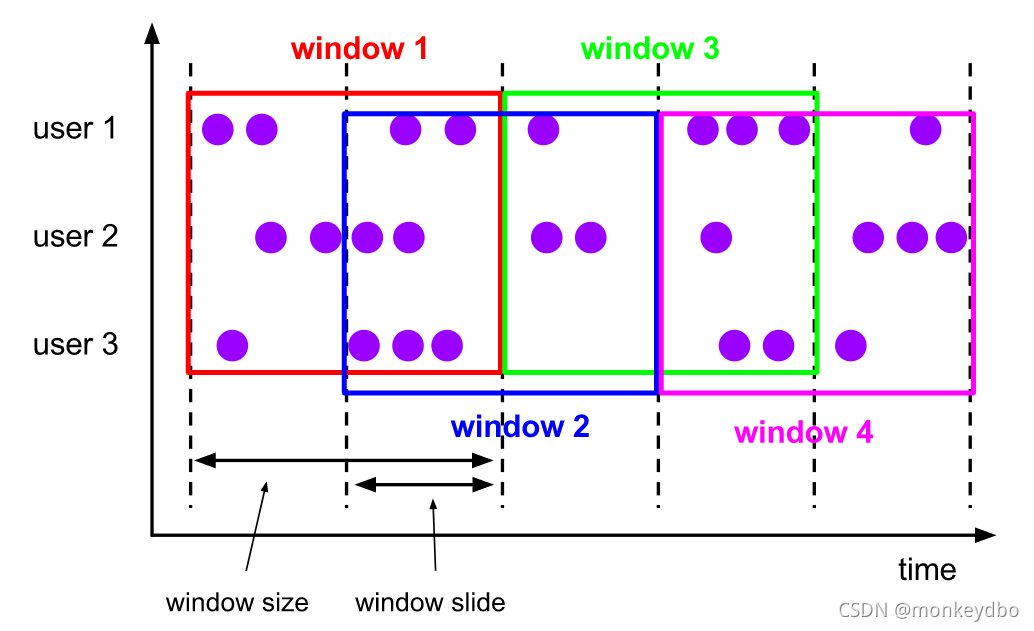
滑动事件窗口 Sliding Windows
特点:
- 窗口可以重叠
- 一个元素可能会被分配到多个窗口中(window-size/window-slide)
- 有两个关键参数:窗口大小,滑动步长
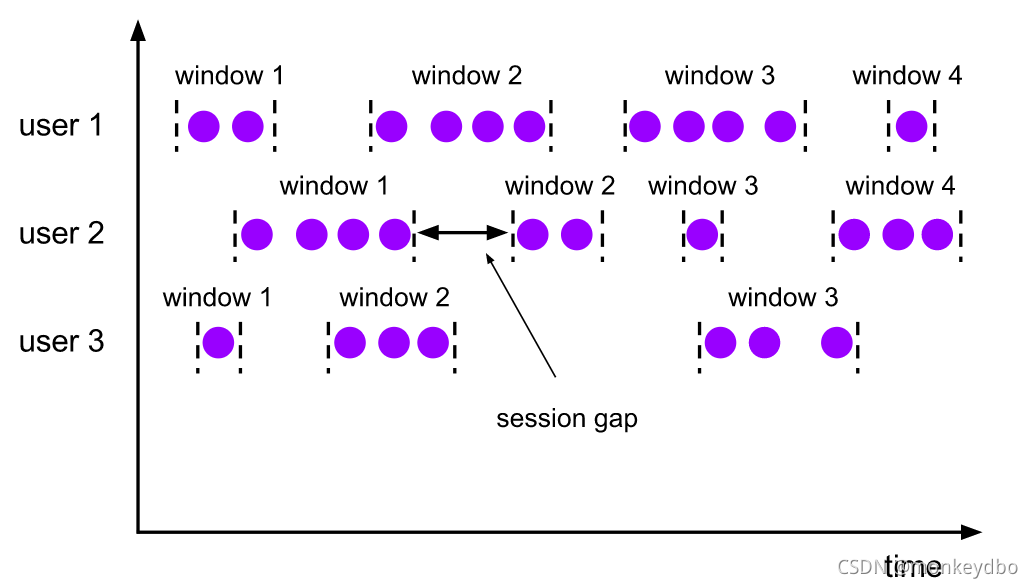
会话窗口 Session Windows
特点:
- 窗口不重合
- 窗口时间跨度不一致
- 需要一个参数,会话间隔(session gap),即多长时间内接不大数据就断开会话窗口
/**
* <p> 数据流开窗转换算子基础测试 </p>
*
* 需要针对无界流
*
* @author hubo
* @since 2021/11/5 10:15
*/
public class OpenWindowOperatorTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketDataSource = executionEnvironment.socketTextStream("192.168.250.55", 9999);
// mapStream
SingleOutputStreamOperator<UserClickRecord> mapStream = socketDataSource.map((MapFunction<String, UserClickRecord>) (line) -> {
String[] lineItems = line.split(",");
UserClickRecord record =
new UserClickRecord(lineItems[0], lineItems[1], lineItems[2], lineItems[3], lineItems[4], lineItems[5]);
return record;
});
// KeyedStream
KeyedStream<UserClickRecord, String> userClickRecordKeyedStream =
mapStream.keyBy((KeySelector<UserClickRecord, String>) record -> record.getLabel());
/*
* 1. Window 可以在已分区的KeyedStreams上定义窗口。
* KeyedStream → WindowedStream
* WindowAll (on non-keyed window stream)
* DataStreamStream → AllWindowedStream
**/
// 滚动处理窗口
WindowedStream<UserClickRecord, String, TimeWindow> tumblWindowStream =
userClickRecordKeyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
// 滑动处理窗口
WindowedStream<UserClickRecord, String, TimeWindow> slidWindowStream =
userClickRecordKeyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(5)));
/*
* 2. Window Apply 将常规 Function 应用于窗口
* WindowedStream → DataStream
* AllWindowedStream → DataStream
**/
SingleOutputStreamOperator<Object> windowApplyedStream = slidWindowStream.apply(new WindowFunction<UserClickRecord, Object, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<UserClickRecord> input, Collector<Object> out) throws Exception {
StringBuffer uuids = new StringBuffer("");
for (UserClickRecord record : input) {
uuids.append("," + record.getUuid()) ;
}
out.collect(uuids.toString());
}
});
windowApplyedStream.print("windowApplyedStream");
/*
* 3. WindowReduce 将 ReduceFunction 应用到窗口中。 WindowedStream → DataStream
**/
SingleOutputStreamOperator<UserClickRecord> windowReducedStream = tumblWindowStream.reduce((ReduceFunction<UserClickRecord>) (valueOld, valueNew) -> {
String newEventUuid = valueNew.getUuid();
String uuids = valueOld.getUuid() + "," + newEventUuid;
valueOld.setUuid(uuids);
return valueOld;
});
windowReducedStream.print("windowReducedStream");
executionEnvironment.execute();
}
}
流数据合并算子
- Union
- Connect - CoMap, CoFlatMap
- Iterate
/**
* <p> 流数据合并转换算子测试 </p>
*
* @author hubo
* @since 2021/11/5 17:20
*/
public class StreamMergeOperatorTest {
public static void main(String[] args) throws Exception {
String filePath = "E:\\Projects\\bigdata\\flink\\flink-study\\demo01\\src\\main\\resources\\userclickrecordtempdata.txt";
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<UserClickRecord> streamSourceFromMyUserClickSource = executionEnvironment.addSource(new UserDefineDataSourceTest.MyUserClickSource());
DataStreamSource<String> streamSourceFromSocket = executionEnvironment.socketTextStream("192.168.116.100", 9999);
DataStreamSource<String> streamSourceFromTextFile = executionEnvironment.readTextFile(filePath);
DataStream<String> streamSourceFromCollection = executionEnvironment
.fromCollection(Arrays.asList(
new UserClickRecord("1", "1111", "1", "1", "1", "1").toString(),
new UserClickRecord("2", "222", "1", "1", "1", "1").toString(),
new UserClickRecord("3", "33", "1", "1", "1", "1").toString(),
new UserClickRecord("4", "44", "1", "1", "1", "1").toString(),
new UserClickRecord("5", "55", "1", "1", "1", "1").toString(),
new UserClickRecord("6", "66", "1", "1", "1", "1").toString()
)
);
/*
* 1. Union DataStream* → DataStream
* 合并多个流,要求每个流中的数据类型要一致,合并同一个流时,流中的元素会得到两次,即相同的元素并不会被擦除
**/
DataStream<String> unionStringDataStream =
streamSourceFromSocket.union(streamSourceFromTextFile,streamSourceFromCollection);
unionStringDataStream.print("unionSocketAndFile");
/*
* 2. Connect DataStream,DataStream → ConnectedStream
* CoMap, CoFlatMap ConnectedStream → DataStream
* 示例:streamSourceFromMyUserClickSource 是一个 UserClickRecord 类型的对象流
* streamSourceFromSocket 是一个 String 流,将他们连接
* 再利用 CoMap, CoFlatMap 通过同一个类型输出
* (以 CoMap 为例,CoFlatMap 类似,就是 Map 和 flatMap 的区别)
**/
ConnectedStreams<UserClickRecord, String> connectedStream =
streamSourceFromMyUserClickSource.connect(streamSourceFromSocket);
SingleOutputStreamOperator<UserClickRecord> connectedStreamCoMap =
connectedStream.map(new CoMapFunction<UserClickRecord, String, UserClickRecord>() {
@Override
public UserClickRecord map1(UserClickRecord value) throws Exception {
value.setUuid("MyUserClickSource-" + value.getUuid());
return value;
}
@Override
public UserClickRecord map2(String value) throws Exception {
String[] lineIrems = value.split(",");
UserClickRecord record = new UserClickRecord("SocketSource-" + lineIrems[0],
lineIrems[1],
lineIrems[2],
lineIrems[3],
lineIrems[4],
lineIrems[5]);
return record;
}
});
connectedStreamCoMap.print("connectedStreamCoMap");
/*
* 3. Iterate DataStream → IterativeStream → ConnectedStream
* (迭代).通过将一个算子的输出重定向到前一个算子,在流中创建一个 “反馈” 循环。这对于定义持续更新模型的算法特别有用。
* 示例:下面的代码从一个 MyUserClickSource 流开始,并连续应用迭代体。label 为 1 的元素被发送回反馈通道,其余元素被转发到下游。
* out + feedback 可以形成一个反馈机制
**/
IterativeStream<UserClickRecord> iteration = streamSourceFromMyUserClickSource.iterate();
SingleOutputStreamOperator<UserClickRecord> iterationBody =
iteration.map((MapFunction<UserClickRecord, UserClickRecord>) value -> {
if ("1".equals(value.getLabel())){
value.setUuid("非正常点击:" + value.getUuid()); //对应反馈回来的数据做处理
value.setLabel("3"); // 重新标记
}
return value;
});
DataStream<UserClickRecord> feedback = iterationBody.filter(
(FilterFunction<UserClickRecord>) value -> "1".equals(value.getLabel()))
.setParallelism(1);// 因为 streamSourceFromMyUserClickSource 的并行度为 1,所有 feedback 回去的并行度要一致
iteration.closeWith(feedback);
DataStream<UserClickRecord> out = iterationBody.filter(
(FilterFunction<UserClickRecord>) value -> !"1".equals(value.getLabel()));
ConnectedStreams<UserClickRecord, UserClickRecord> connectOutWithFeedBack = out.connect(feedback);
SingleOutputStreamOperator<String> connectedFeedBackStream = connectOutWithFeedBack.map(new CoMapFunction<UserClickRecord, UserClickRecord, String>() {
@Override
public String map1(UserClickRecord value) throws Exception {
return value.toString();
}
@Override
public String map2(UserClickRecord value) throws Exception {
value.setUuid("非正常点击:" + value.getUuid());
return value.toString();
}
});
connectedFeedBackStream.print("connectedFeedBackStream");
executionEnvironment.execute("unionStringDataStream");
}
}


















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









