







 本文详细介绍了Apache Flink的集群组件,包括FlinkClient、JobManager、TaskManager、HighAvailabilityServiceProvider、FileStorageandPersistency、ResourceProvider和MetricsStorage。讲解了JobManager的三种作业提交模式:SessionMode、Per-JobMode和ApplicationMode,以及它们的特点和适用场景。此外,还提到了数据源和出口的多种实现,如Kafka、ElasticSearch等。
本文详细介绍了Apache Flink的集群组件,包括FlinkClient、JobManager、TaskManager、HighAvailabilityServiceProvider、FileStorageandPersistency、ResourceProvider和MetricsStorage。讲解了JobManager的三种作业提交模式:SessionMode、Per-JobMode和ApplicationMode,以及它们的特点和适用场景。此外,还提到了数据源和出口的多种实现,如Kafka、ElasticSearch等。
Flink 集群组件
集群组件图
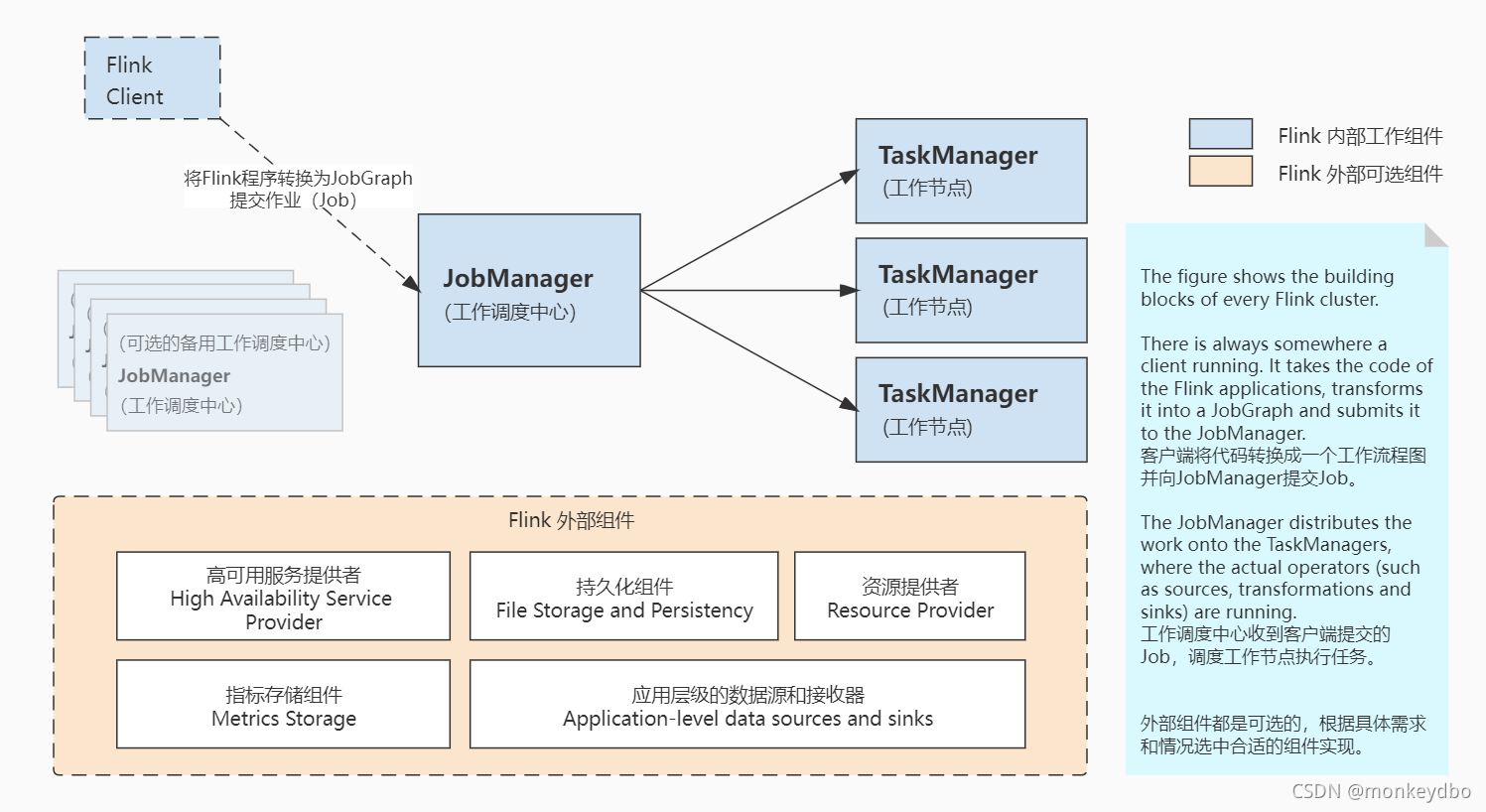
组件介绍:
Flink Client ( Flink 客户端 )
用途:将批处理或者流处理应用编译成一个 Data Flow Graph(数据流程图)或者说是 JobGraph(作业流程图),并将它提交到 JobManager
实现方式:
- Command Line Interface 利用命令行
- REST Endpoint 利用http请求端点
- SQL Client 数据库语言客户端
- Python REPL 利用 Python 交互式的编程
- Scala REPL 利用 Scala 交互式的编程
JobManager ( 工作调度中心 )
用途:调度工作节点,向工作节点分发任务。JobManager 的针对不同的资源提供者有不同的实现。并且它有三种 (job submission modes) 作业提交模式(Application、Per-Job、Session Mode)。
JobManager 的资源提供方式:
- Standalone
- Kubernetes
- YARN
- Mesos (Apache Mesos 是一个资源管理框架,暂时没有接触过)
TaskManager 任务管理器(工作者)
用途:真正干活的组件,虽然他叫任务管理器,但是它并不管理任务,它是任务执行者,给他起名管理器大概是应为它并不是执行任务的最小单元,它里面还管理着插槽(Slot)。
High Availability Service Provider 提供高可用支持的组件
作用:保证 JobManager 的高可用,因为他是集群的中心控制者,虽然可以有很多备份,但是集群中实际使用的 JobManager 只有一个。只有在这个 JobManager 出现故障不可用时,才会从备份中选一个继续提供服务。
实现方式:
- Zookeeper
- Kubernetes HA
File Storage and Persistency 持久化组件
用途:数据持久化,状态持久化
可选实现:很多
Resource Provider 资源提供组件
作用:提供计算资源,除了 Standalone 方式,其他的都可以为 Flink 集群提供动态扩展资源的能力。
实现方式:
- Standalone
- Kubernetes
- YARN
- Mesos (Apache Mesos 是一个资源管理框架,暂时没有接触过)
Metrics Storage 指标存储组件
作用:存储 Flink 集群中的各种指标数据,以便监控与分析
Flink Metrics 包括系统的各种指标(例如:Hostname,CPU,内存占用,GC 等)和各种任务指标(例如:各个任务组件的指标、Job、Task 等等)。这些数据可以用在 UI 展示,也可以通过 MetricsReport 上报数据,由第三方系统监控分析。
Application-level data sources and sinks 应用层级的数据源和出口
作用:即使各种和 Flink 连接的数据,可以是输入端为 Flink 提供计算的数据源,也可以是输出端,让Flink 计算完的数据可以落盘或者输出。
可选实现:
- Kafka
- ElasticSearch
- 各种 Connectors
- 等等
job submission modes(三种作业提交模式)
三者主要区别点:
- 作业工作时的集群资源隔离方式
- 集群生命周期
- 应用程序的main()方法的执行位置(client或者JobManager)
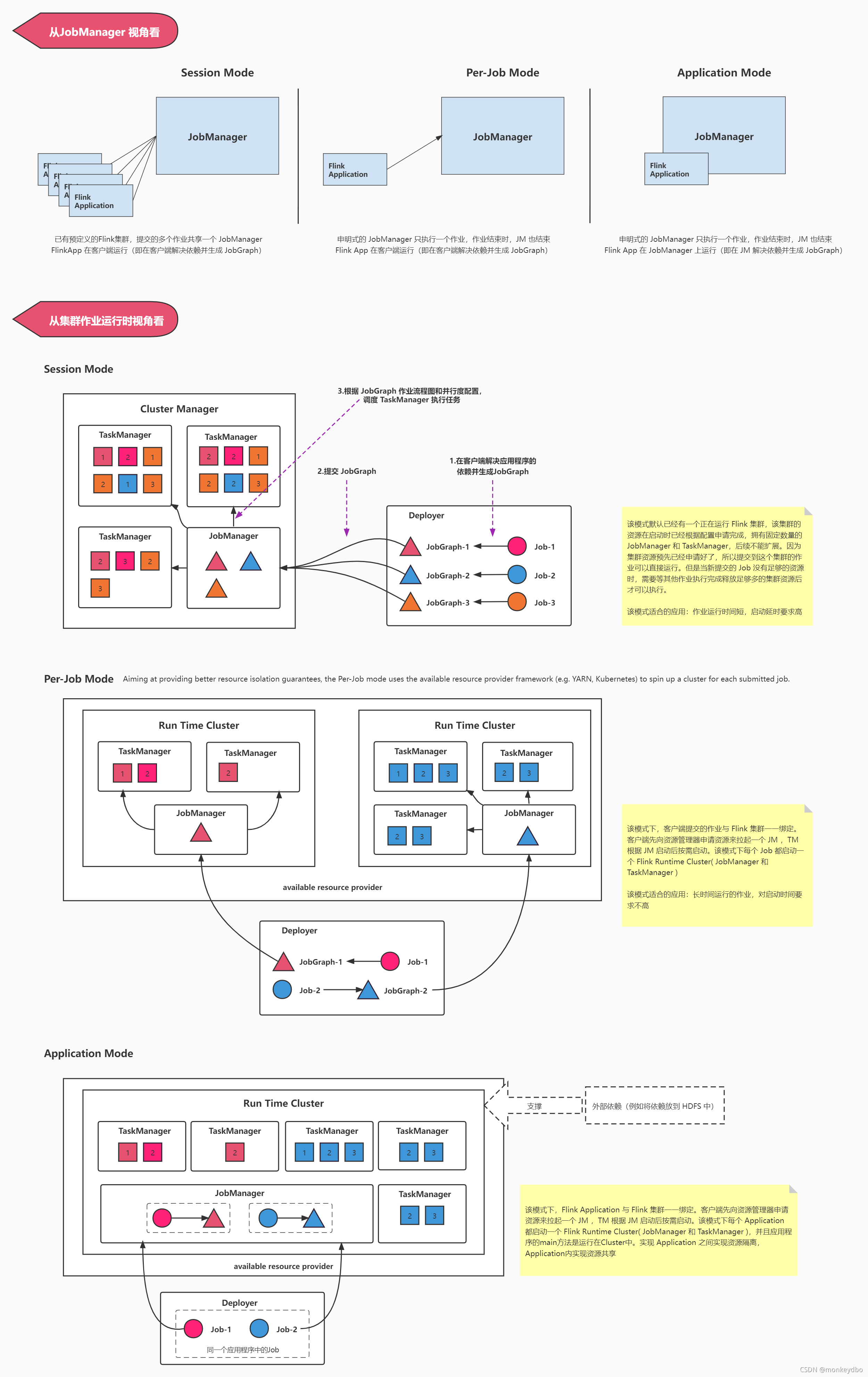
Session Mode
该模式默认已经有一个正在运行 Flink 集群,该集群的资源在启动时已经根据配置申请完成,拥有固定数量的 JobManager 和 TaskManager,后续不能扩展。因为集群资源预先已经申请好了,所以提交到这个集群的作业可以直接运行。但是当新提交的 Job 没有足够的资源时,需要等其他作业执行完成释放足够多的集群资源后才可以执行。
该模式适合的应用:作业运行时间短,启动延时要求高
特点:
- 该模式集群生命周期不受 Job 的生命周期影响,只要预定义的集群资源足够,就可以提交 Job
- 集群中的所有 Job 都共享一套集群资源(JM和TM),会出现资源竞争,某个TM节点宕机会影响多个 Job
- 应用程序的 main() 方法在客户端执行,客户端需要负责编译程序生成 JobGraph 并将 JobGraph 和 程序的依赖提交到 JM。客户端和JM 压力大。
Per-Job Mode
该模式下,客户端提交的作业与 Flink 集群式一一绑定的。客户端先向资源管理器申请资源来拉起一个 JM ,TM 根据 JM 启动后按需启动。该模式下每个 Job 都启动一个 Flink Runtime Cluster( JobManager 和 TaskManager )
该模式适合的应用:长时间运行的作业,对启动时间要求不高,多个作业之间要求资源隔离的应用
特点:
- 集群生命周期和 Job 绑定,job停止后集群也会被停止
- 作业之间资源隔离,单个Job独享一套JobManager和TaskManager,不存在资源竞争问题
- 计算资源根据 Job 来申请
- 需要向外部资源管理器请求资源来启动 TaskManager
- 资源相较浪费,每个job都需要启动一个JobManager
- Client负载比较大,需要生成JobGraph,并将JobGraph及其依赖jar上传到JobManager
Application Mode
该模式下,Flink Application 与 Flink 集群一一绑定。客户端先向资源管理器申请资源来拉起一个 JM ,TM 根据 JM 启动后按需启动。该模式下每个 Application 都启动一个 Flink Runtime Cluster( JobManager 和 TaskManager ),并且应用程序的main方法是在Cluster中运行,客户端只需要负责发起部署请求。实现 Application 之间实现资源隔离,Application内实现资源共享。
特点:
- 生命周期和 Flink Application 绑定,当Application全部执行完,集群才会停止
- Flink Application 使用一套 JobManager 和 TaskManager,相较前两种模式找到了一个比较好的隔离点。
- 降低Client负载
- Application之间实现资源隔离,Application内实现资源共享
- 客户端只需要负责发起部署请求


















 1950
1950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









