







 本文详细介绍了Spark SQL的使用,包括SparkSQL的诞生和发展、功能特点、数据结构抽象如RDD、DataFrame、DataSet,以及如何通过SQL和DSL实现WordCount。文章还探讨了Spark与HBASE、MySQL的数据交互,并讲解了广播变量、累加器等共享变量的使用,以及SparkCore的调度机制,如宽窄依赖、Shuffle和Stage划分。
本文详细介绍了Spark SQL的使用,包括SparkSQL的诞生和发展、功能特点、数据结构抽象如RDD、DataFrame、DataSet,以及如何通过SQL和DSL实现WordCount。文章还探讨了Spark与HBASE、MySQL的数据交互,并讲解了广播变量、累加器等共享变量的使用,以及SparkCore的调度机制,如宽窄依赖、Shuffle和Stage划分。
分布式计算平台Spark:SQL(一)
一、重点
-
Spark中RDD的常用函数
-
分区操作函数:mapPartitions、foreachPartition
- 功能:与map和foreach基本功能一致,这两个函数是对分区进行操作的
- 应用:对RDD数据处理时,需要构建资源时
-
重分区函数:repartition、coalesce
- 功能:调节RDD分区的个数
- 应用:repartition实现调大、coalesce降低分区个数
-
聚合函数:reduce/fold/aggregate
- 分布式聚合:先分区内聚合,再分区间聚合
- fold:初始值在每次聚合都要初始化构建一次
- aggregate(初始值)(分区内聚合逻辑,分区间聚合逻辑)
- 分布式聚合:先分区内聚合,再分区间聚合
-
二元组函数:reduceByKey、aggregateByKey、groupByKey、sortByKey
- groupByKey容易导致内存溢出问题,尽量避免使用
-
关联函数:join
-
二元组类型的RDD才可以实现join:按照Key进行join
RDD【(K,v)】.join(RDD【(K,w)】) => RDD【(K,(v,W))】
-
-
-
RDD的容错机制
-
依赖关系:当计算过程中如果RDD的数据丢失,可以依赖关系重新构建整个RDD的数据
-
缓存机制:persist(StorageLevel)
-
功能:将RDD缓存在内存中【可选缓存级别:mem_disk_ser_2】,如果内存不足,剩余的部分缓存在磁盘中
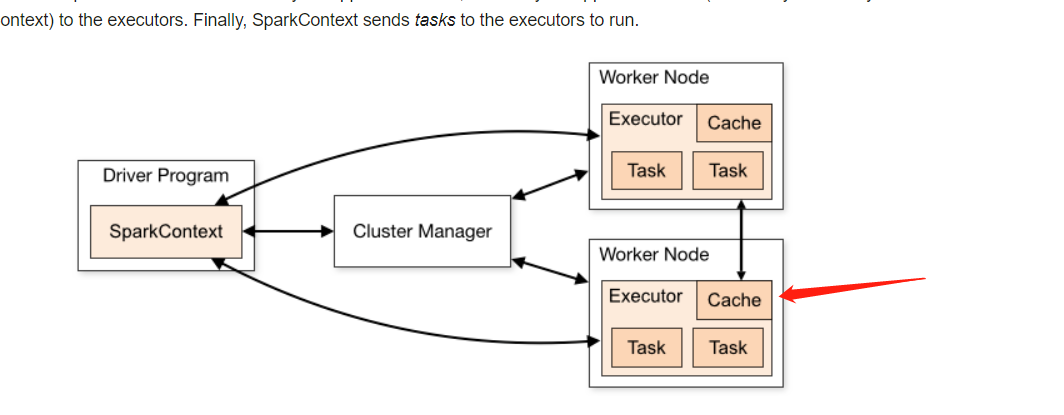
-
注意:如果RDD不再被使用,建议一定要尽早的手动释放掉
rdd.unpersist
-
-
checkpoint机制:checkpoint
- 功能:将RDD的数据持久化的存储在HDFS上
- 与persist区别
- 存储位置
- 存储内容
- 血脉存储
- checkpoint不存储依赖关系
-
-
数据源
- Spark作为分布式计算框架:读写数据来自于各种常见的数据源【分布式数据源】
- Core:HDFS、MySQL、HBASE
- SQL:Hive
- Streaming:Kafka、Redis、HBASE
- Spark作为分布式计算框架:读写数据来自于各种常见的数据源【分布式数据源】
-
反馈问题
- trim函数的功能:去除头尾的空格
二、概要
- Spark读写HBASE和MySQL
- 类似于写JavaAPI,通过Spark来实现分布式读写【将读写的API封装好了】
- Spark读写HBASE:通过调用MapReduce中封装的API
- Spark读写MySQL:封装了JDBC
- 共享变量
- RDD和累加器、广播变量共称为SparkCore两种抽象
- Spark整体程序的架构和调度
- SparkSQL
- 诞生以及设计思想:功能与应用场景
- 数据结果抽象
- SparkCore:RDD
- SparkSQL:DataFrame/DataSet
- SparkStreaming:DStream
- 开发接口:SQL、DSL
三、外部数据源
1、HBASE
-
Spark读写HBASE,自己没有封装API,通过调用Hadoop的API来实现的
- 写:TableOutputFormat
- 读:TableInputFormat
-
写HBASE:将Wordcount的结果通过spark写入HBASE
-
设计
- 表名:htb_wordcount
- rowkey:唯一、散列、长度、组合
- 单词作为rowkey
- 列族:info
- 列名称:count
-
启动HBASE
start-dfs.sh zookeeper-daemons.sh start start-hbase.sh hbase shell -
创建表
create 'htb_wordcount','info' -
开发
package bigdata.it.cn.spark.scala.core.hbase import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.rdd.RDD import org.apache.spark.{ SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 将Wordcount的结果写入HBASE的表中 * - 表名:htb_wordcount * - rowkey:唯一、散列、长度、组合 * - 单词作为rowkey * - 列族:info * - 列名称:count * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreWriteToHbase { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) //todo:2-数据处理 val rsRdd: RDD[(String, Int)] = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) .reduceByKey(_+_) //todo:3-保存结果 // rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) //写入HBASE //Spark中提供了专门调用Hadoop输入输出类的方法 /** * def saveAsNewAPIHadoopFile( * path: String,:指定的一个临时存储路径 * keyClass: Class[_],:指定输出类的Key的类型 * 注意:TableOutputFormat中输出的Key的类型不重要,会被丢弃,一般给ImmutableBytesWritable类型 * 这个类型是HBASE中用于单独存储roowkey的类型 * valueClass: Class[_],:指定输出类的Value类型 * 注意:TableOutputFormat中输出的Value必须为Mutation的子类,如果是写入数据,就用Put类型 * outputFormatClass: Class[_ <: NewOutputFormat[_, _]], :指定调用Hadoop的哪种输出类 * conf: Configuration = self.context.hadoopConfiguration): Unit */ //将rsRDD转换为输出的类型:ImmutableBytesWritable,Put val putRdd: RDD[(ImmutableBytesWritable, Put)] = rsRdd .map{ case (word,numb) => { //Key为ImmutableBytesWritable:rowkey val key = new ImmutableBytesWritable(Bytes.toBytes(word)) //Value为Put类型,要存储的每一列 val value = new Put(Bytes.toBytes(word)) //添加列族、列族、值 value.addColumn( Bytes.toBytes("info"), Bytes.toBytes("count"), Bytes.toBytes(numb.toString) ) (key,value) }} //构建Hadoop的Configuration对象,存储一些HBASE的配置:ZK的地址,表的名称 val configuration = HBaseConfiguration.create() //指定HBASE的访问地址 configuration.set("hbase.zookeeper.quorum", "node1.it.cn") configuration.set("hbase.zookeeper.property.clientPort", "2181") configuration.set("zookeeper.znode.parent", "/hbase") //指定写入表的名称 configuration.set(TableOutputFormat.OUTPUT_TABLE,"htb_wordcount") //调用输出类来写入 putRdd.saveAsNewAPIHadoopFile( "datas/output/hbase", classOf[ImmutableBytesWritable], classOf[Put], classOf[TableOutputFormat[ImmutableBytesWritable]], configuration ) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
-
-
读HBASE
package bigdata.it.cn.spark.scala.core.hbase
import org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName SparkCoreMode
* @Description TODO Spark Core读HBASE数据
* @Date 2020/12/17 9:32
* @Create By Frank
/
object SparkCoreReadFromHbase {
def main(args: Array[String]): Unit = {
/*
* step1:初始化一个SparkContext
*/
//构建配置对象
val conf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster(“local[2]”)
// TODO: 设置使用Kryo 序列化方式
.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
// TODO: 注册序列化的数据类型
.registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result]))
//构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建
val sc = SparkContext.getOrCreate(conf)
//调整日志级别
sc.setLogLevel("WARN")
/**
* step2:实现数据的处理过程:读取、转换、保存
*/
//todo:1-读取
/**
* def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
* conf: Configuration = hadoopConfiguration,
* fClass: Class[F],:指定调用Hadoop哪种输入类:InputFormat
* kClass: Class[K],:输入类返回的Key
* vClass: Class[V]):输入类返回的Value
*/
//构建Hadoop的Configuration对象,存储一些HBASE的配置:ZK的地址,表的名称
val configuration = HBaseConfiguration.create()
//指定HBASE的访问地址
configuration.set("hbase.zookeeper.quorum", "node1.it.cn")
configuration.set("hbase.zookeeper.property.clientPort", "2181")
configuration.set("zookeeper.znode.parent", "/hbase")
//指定写入表的名称
configuration.set(TableInputFormat.INPUT_TABLE,"htb_wordcount")
//通过调用方法来调用Hadoop中的任何一种输入类:[ImmutableBytesWritable, Result]
val hbaseRdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
configuration,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
//todo:2-转换
val dataRdd: RDD[Result] = hbaseRdd.map(tuple => tuple._2)
//todo:3-保存
dataRdd
//加了take,会将数据从Executor返回到Driver中的一个数组中,再进行打印,要求,传输的对象要进行序列化,在Spark构建时定义序列化机制
.take(3)
//如果不加take,是对RDD的数据打印,这个是在Executor中执行的打印
.foreach(rs => {
//每个Result存储的是每个Rowkey的所有数据,每个rowkey包含很多列,每一列就是一个Cell对象,所有的列都在cell数组中
val cells: Array[Cell] = rs.rawCells()
//取出每一列进行打印
cells.foreach(cell => {
//从cell中取出rowkey,列族、列名、值
val rowkey = Bytes.toString(CellUtil.cloneRow(cell))
val family = Bytes.toString(CellUtil.cloneFamily(cell))
val column = Bytes.toString(CellUtil.cloneQualifier(cell))
val value = Bytes.toString(CellUtil.cloneValue(cell))
println(rowkey+"\t"+family+"\t"+column+"\t"+value)
})
})
/**
* step3:释放资源
*/
Thread.sleep(1000000L)
sc.stop()
}
}
### 2、MySQL
- 读MySQL:SparkCore中的应用比较少【表读进来变成了RDD,没有schema】,一般用SparkSQL来做
- 写MySQL:将Wordcount的结果写入MySQL中
- 登录MySQL:node1
mysql -uroot -p
- MySQL中创建表
USE db_test ;
drop table if exists tb_wordcount;
CREATE TABLE tb_wordcount (
word varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
count varchar(100) NOT NULL,
PRIMARY KEY (word)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;
- 代码实现
```scala
package bigdata.it.cn.spark.scala.core.mysql
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @ClassName SparkCoreSimpleMode
* @Description TODO Spark实现写mySQL
* @ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









