 GA-ConvGRU雷达降水预测
GA-ConvGRU雷达降水预测








 本文介绍了一种名为GA-ConvGRU的新模型,该模型结合了生成对抗网络(GAN)和卷积门控循环单元(ConvGRU),用于雷达回波图的降水预测。通过深圳气象局的雷达数据集验证,该模型在降水密度预测方面表现出优于传统ConvGRU模型的性能。
本文介绍了一种名为GA-ConvGRU的新模型,该模型结合了生成对抗网络(GAN)和卷积门控循环单元(ConvGRU),用于雷达回波图的降水预测。通过深圳气象局的雷达数据集验证,该模型在降水密度预测方面表现出优于传统ConvGRU模型的性能。
Address
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8777193
一、Abstract
本paper研究的是利用雷达回波图来预测降水。
对于这个场景下的预测,最近主要应用ConvGRU模型
尽管有很好的表现,但ConvGRU想去产生模糊的回波图像并且没有多模态和偏斜的强度分布。
为了去解决这个限制,提出了GA-ConGRU。
二、Related Work
2.1 Deep Learning-based Image Sequence Forecasting
常用的为以下两种
- autoencoder
- RNN
Yan利用dynamic autoencoder network 来预报高质量视频序列。
Liu利用fully convolutional autoencoder model
卷积神经网路能够足够的开发时空的信息。
所以后来用conv来代替fcn,为了更好地利用时空特征,最终用ConLSTM模型来预测,但由于参数太多,所以利用ConvGRU
2.2 Generative Adversarial Networks
这里提到的就是GAN模型
以下做简略说明,更多GAN详情请直接学习GAN即可,如果你不是学GAN的,和我一样只是偶尔用到,那就稍微了解一下即可。
GAN的目的其实就是去近似的得到一个目标分布。
由两个部分组成
- generator 可以理解为产生随机数据的生成器
- discriminator 可以理解为学习分别好与坏,并且不断通过判别随机生成和真实之间的差异来给于generator反馈
三、Related Work
提出了GA-ConvGRU,结构如下:
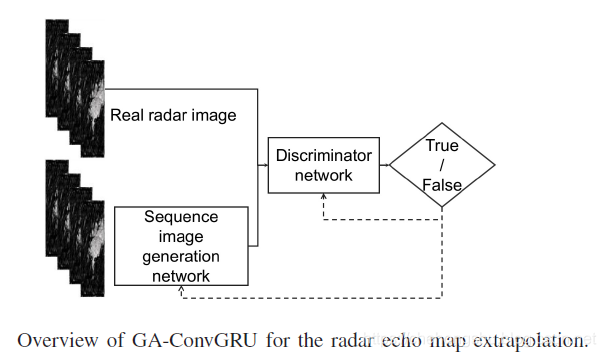
3.1、Generator
一个雷达回波图6分钟产生一张。
生成器将实现来预测将来的图像序列。
generator
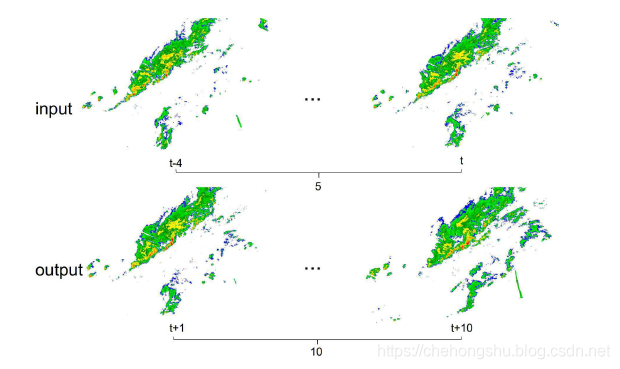
- input: 5个image,即从现在开始之前的24min。(包括现在)
- output: 10个image,即现在开始之后的1个小时。(不包括此时此刻)
生成器的结构:

总体的generator的框架
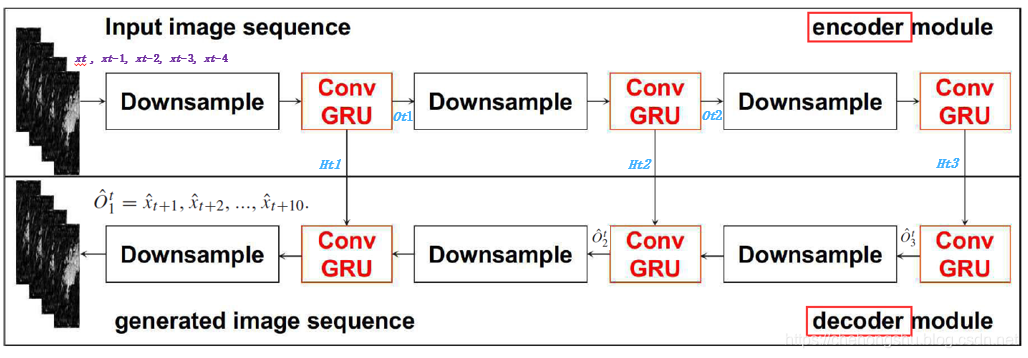
图中我做了一些处理,总体应该很容易看出来总体的变量输入输出,总体的框架依旧采用encoder-decoder框架,GRU每两个输入有两个输出一个是Ht,相当于hidden state,还有个输出o。
downsample的作用原文这么说的downsample operator is necessary to reduce the redundancy information and form a compact representation; 用来 减小冗余的信息并且形成更为紧密的表达,大白话讲就是更加精致的图片,对于目标来说。
ConvGRU:
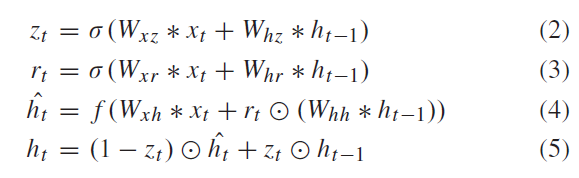
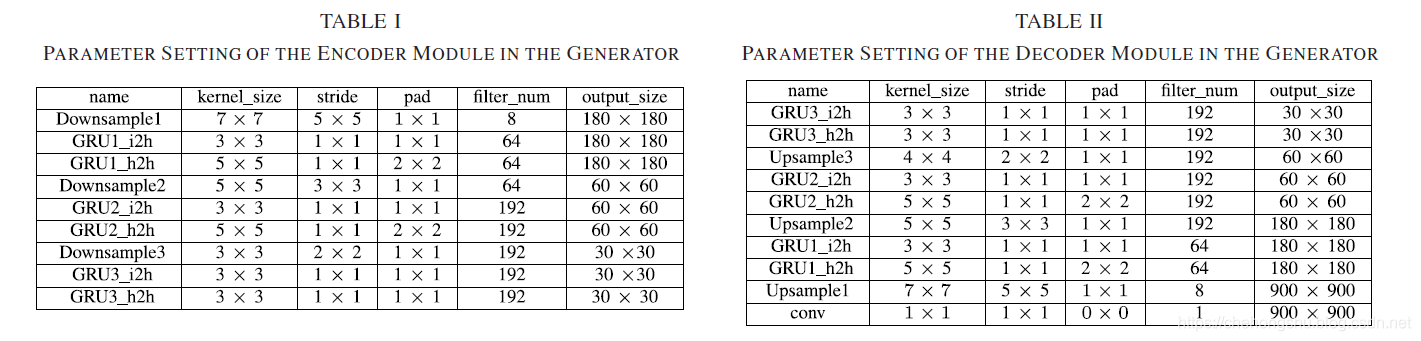
网络的参数
其中GRU的意思为convGRU的卷积部分的卷积核的参数,i2h为input to hidden ,h2h表示为hidden to hidden
loss函数依然还是MSE,因为预测问题一般都是MSE
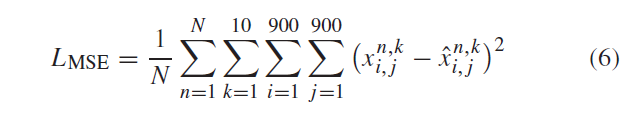
- N 为training samples的个数
- k表示每一次序列输出十个序列图片
- 900900其实就是图片的像素,即行列为900900个像素点,之后每个像素点的相差之乘积的平均值
3.2 Discriminator
the discriminator aims to identify the image sequence produced by the generator from the real observation.
这个discriminator是为了鉴别生成器生成的图片序列和真实的图片序列,这本质上是个二分类问题,是否是真实图片序列数据。
因为最终输出生成器生成的十个图片,把这十个图片与真实的十个序列图片,没对应的两个作为一个对。
对于这个二分类问题,这里我们采用CNN进行分类。
分类器结构为五个cnn组成。
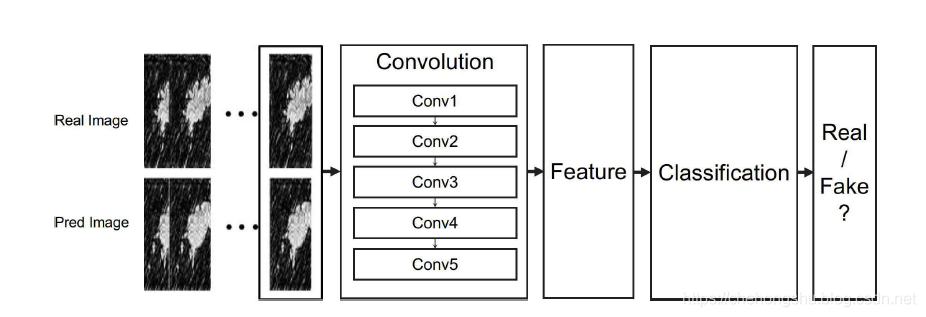
这个cnn discriminator的工作流程如图所示,首先,每个图片对的其中一个图片作为输入,经过五个cnn进行特征提取,最终通过sigmoid,输出一个概率表示是真实数据的概率,如果是真实数据,这个discriminator就会最大化概率,反之是生成的图片则会最小化概率。
生成器生成的图片更逼近于真实就能让discriminator最大化这个分类概率。
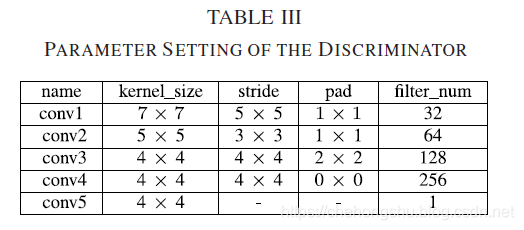
这个model的参数如下,可以看到最后一个conv输出为1
这个cnn模型的loss函数为
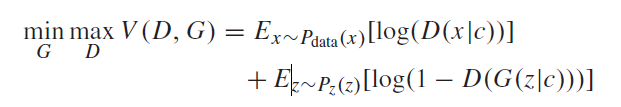
公式很简单,一看就能懂,不过博客比较麻烦写起来,直接贴下面了

最终把generator和discriminator的loss结合在一起。
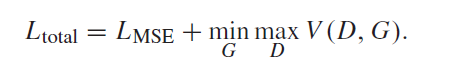
四、Experiments
4.1 Data Sets
来自于深圳气象局收集的雷达回波图作为数据。
每个雷达图覆盖全部的广东省的地区。
- training set 2014.1.1-2016.12.31
- validation set 2017.1.1-2018.5.31
- test set 2018.6.1-2018.12.30
全部的雷达图都是在2.5km之上的高度,大小都为900*900.
每一个像素点是1km*1km的大小距离
4.2 Evaluation Metrics
这里采用四个评估公式
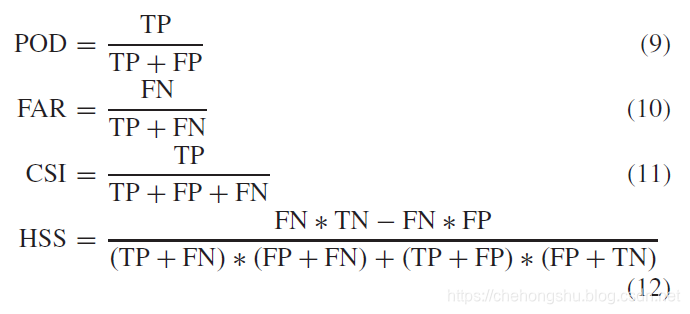
其中
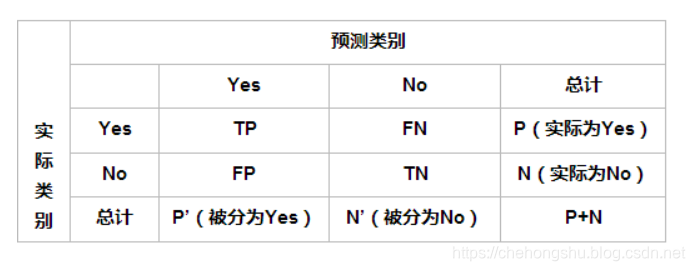
在计算这四个方程之前,先利用一个阈值,把图片中的像素点分为0或1,其中阈值可以为0.5, 5,10, 30对应着不同的降雨水平

4.3 Baselines
光流和convGRU方法。
4.4 Experimental Results
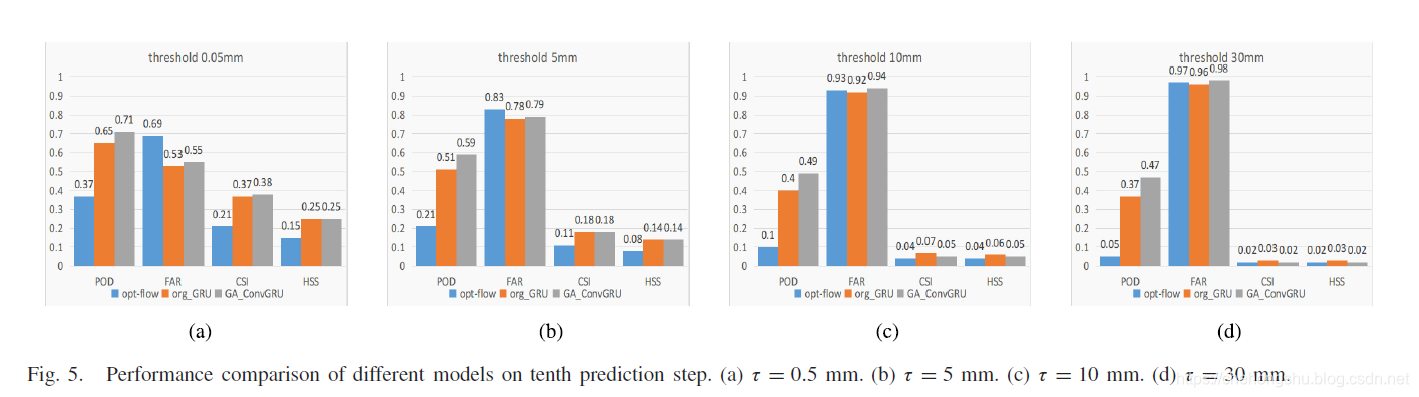
就POD而言,随着密度的增加,GA-ConvGRU和ConvGRU之间的差别越大,说明降水密度越大效果越好。
为了检验鲁棒性和稳定性。
采用2018.6.12 12:00到2018.6.13 23:00
每一小时的10张图片进行预测。
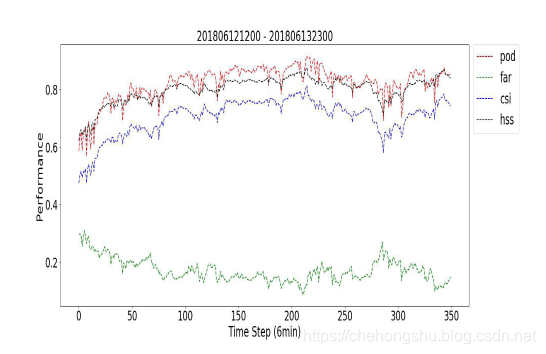
判断依据依旧很平稳,每一太大的波动。

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









