







 该博客探讨LeetCode第10题,涉及正则表达式匹配问题,支持'.'和'*'操作。输入字符串s可能为空或仅包含小写字母,模式p同样可为空,包含小写字母和特殊字符'.'(匹配任意单字符)和'*'(匹配前面元素0次或多次)。博主提供了两种解决方案,一是递归,二是动态规划,动态规划方法在效率上显著优于递归。
该博客探讨LeetCode第10题,涉及正则表达式匹配问题,支持'.'和'*'操作。输入字符串s可能为空或仅包含小写字母,模式p同样可为空,包含小写字母和特殊字符'.'(匹配任意单字符)和'*'(匹配前面元素0次或多次)。博主提供了两种解决方案,一是递归,二是动态规划,动态规划方法在效率上显著优于递归。
题意:正则表达式匹配
Given an input string (s) and a pattern (p), implement regular expression matching with support for '.' and '*'.
'.' Matches any single character.
'*' Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
Note:
scould be empty and contains only lowercase lettersa-z.pcould be empty and contains only lowercase lettersa-z, and characters like.or*.
Example 1:
Input:
s = "aa"
p = "a"
Output: false
Explanation: "a" does not match the entire string "aa".
Example 2:
Input:
s = "aa"
p = "a*"
Output: true
Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes "aa".
Example 3:
Input:
s = "ab"
p = ".*"
Output: true
Explanation: ".*" means "zero or more (*) of any character (.)".
Example 4:
Input:
s = "aab"
p = "c*a*b"
Output: true
Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches "aab".
Example 5:
Input:
s = "mississippi"
p = "mis*is*p*."
Output: false正则表达式匹配,关键就是匹配这俩字。首先,有两个对象,比较这两个对象,只有一模一样才叫做匹配。从 note 看,
scould be empty and contains only lowercase lettersa-z.pcould be empty and contains only lowercase lettersa-z, and characters like.or*.
输入串s 可为空 或者 只包含小写字母 (a-z)
样品 p 可为空 或者 包含唯一一个小写字母(a-z)和 ' . ' ' * ' 这两个特殊字符
'.' Matches any single character. '.' 可变成任意一个单字符
'*' Matches zero or more of the preceding element. '*' 可让在其最前面的一个字符重复 0 或 n 次 (0 次表示其前一个字符消失)
第一种解法: 递归
package pers.leetcode;
/**
* LeetCode 10 正则表达式匹配
* 难度: Hard
*
* @author 朱景辉
* @date 2019/3/21 9:49
*/
public class RegularExpressionMatching {
public static void main(String[] args) {
String s = "ab";
String p = ".*c";
System.out.println("是否匹配: " + isMatch(s, p));
}
public static boolean isMatch(String text, String pattern){
// 先处理特殊情况,pattern 为空的情况下,text为空返回true,否则返回false
if (pattern.isEmpty()){
return text.isEmpty();
}
// 首先比较双方第一个字符是否相同,2 种情况
// 1. 两者第一个字符相同
// 2. pattern 的第一个字符是 '.'
boolean first_match = (!text.isEmpty() && (pattern.charAt(0) == text.charAt(0) || pattern.charAt(0) == '.'));
// 递归处理两种情况
// 1. pattern长度大于等于 2 ,且第 2 个字符为'*'
// 2. 要么 pattern 长度为1,要么长度大于等于 2,但第二个字符不为 '*'
if (pattern.length() >= 2 && pattern.charAt(1) == '*'){
// 这里返回也有两种情况
// 1. '*' 将其前一个字符置空,再从 text 的第一个字符 与 pattern 的第三个字符匹配
// 2. '*' 目前重复 1 次, 与 text 第一个字符匹配到了,再用 text 的第二个字符 与 pattern 的第一个字符匹配
return (isMatch(text, pattern.substring(2)) || (first_match && isMatch(text.substring(1), pattern)));
}else {
// 只有双方第一个字符相同 且 剩余字符匹配 才返回 true
return first_match && isMatch(text.substring(1), pattern.substring(1));
}
}
}
运行结果:
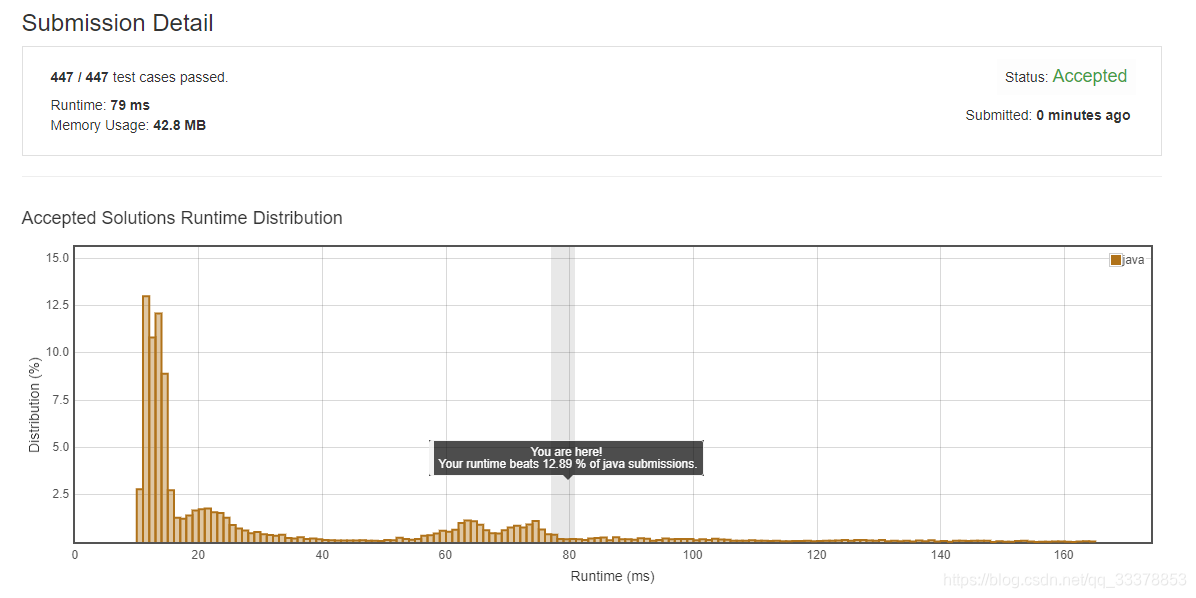
第二种解法:动态规划。。。现在不想写了
2019/9/22 补上
/**
* 动态规划
*
* @param text 给定字符串
* @param pattern 匹配字符串
* @return 匹配结果
*/
public static boolean isMatch2(String text, String pattern){
boolean[][] dp = new boolean[text.length() + 1][pattern.length() +1];
dp[text.length()][pattern.length()] = true;
for (int i = text.length(); i >= 0; i--){
for (int j = pattern.length() - 1; j>= 0; j--){
// 双方最后一个字符是否相同 或者 pattern 最后一个字符为 '.'
boolean first_match = (i < text.length() && (pattern.charAt(j) == text.charAt(i) || pattern.charAt(j) == '.'));
// 1. 从 pattern 倒数第二个字符起, 凡是等于 '*' 的情况
// 2. 不等于 '*'
if (j + 1 < pattern.length() && pattern.charAt(j+1) == '*'){
dp[i][j] = dp[i][j+2] || first_match && dp[i+1][j];
}else {
dp[i][j] = first_match && dp[i+1][j+1];
}
}
}
return dp[0][0];
}
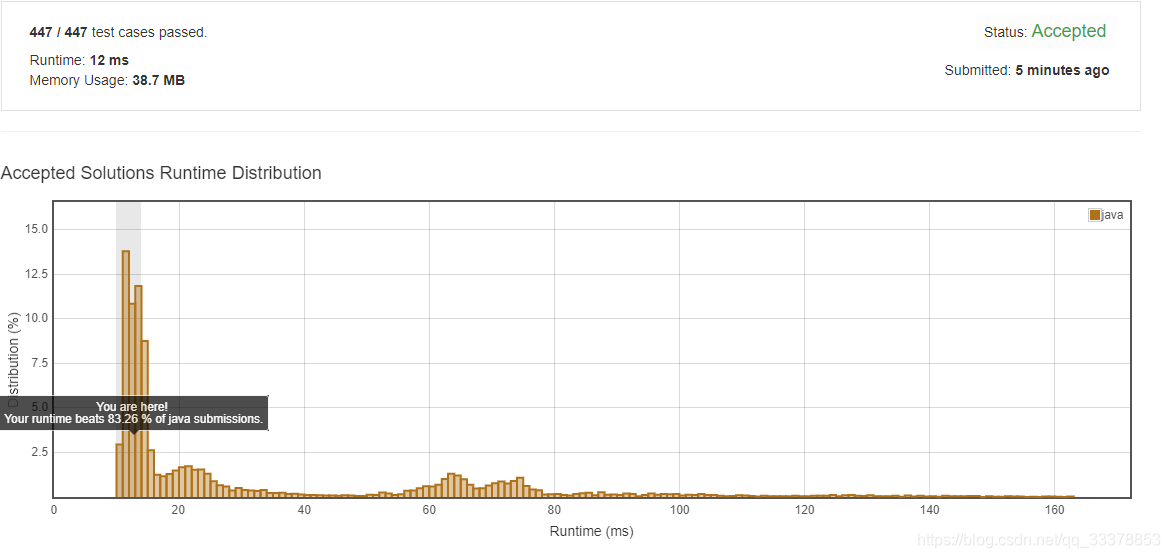
明显的,动态规划比递归快了 N 倍

















 4669
4669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









