







 《Cross-Modal Retrieval in the Cooking Context》介绍了AdaMine模型,它通过联合检索和分类损失在图像和文本间建立语义嵌入。模型在Recipe1M数据集上进行验证,使用双三元组学习方案,结合ResNet-50和双向LSTM对图像和文本特征进行学习。实验显示,自适应学习策略提高了检索性能。
《Cross-Modal Retrieval in the Cooking Context》介绍了AdaMine模型,它通过联合检索和分类损失在图像和文本间建立语义嵌入。模型在Recipe1M数据集上进行验证,使用双三元组学习方案,结合ResNet-50和双向LSTM对图像和文本特征进行学习。实验显示,自适应学习策略提高了检索性能。
论文地址:
https://arxiv.org/pdf/1804.11146.pdfarxiv.org
来源:ACM SIGIR2018(暂未发布源码)
一、Introduction:
文章要做的事情(recipe retreival):
输入:image(sentence)+dataset 输出:sentence(image) rank list
在本文中,我们提出了一个跨模态检索模型,在共享表示空间中对齐视觉和文本数据(如菜肴图片和食谱)。我们描述了一个有效的学习方案,能够解决大规模问题,并在包含近100万个图片配方对的Recipe1M数据集上进行验证。
二、Contributions:
1.提出了一个跨模态检索及分类损失的联合目标函数来构建潜在空间。

2.提出了一个双重三元组来共同表达
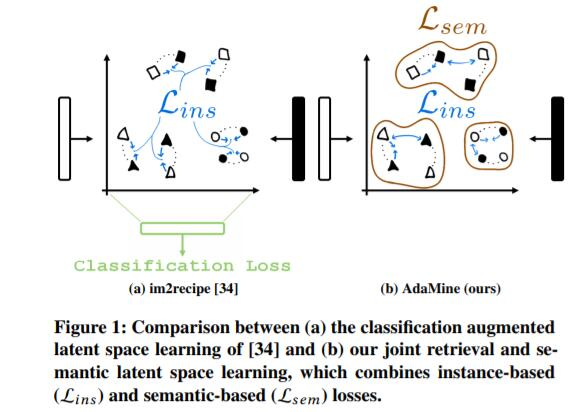
1)检索损失(例:比萨的配方和相对应的图片的距离在潜在空间中比其他的图片更接近,见图1b中的蓝色箭头)
2)类别损失(例:在潜在空间中,两种披萨的距离,比起,比萨和任何来自其他类别的另一个物品,如沙拉更接近)。我们基于类别的损失直接作用于特征空间,而不是向模型添加分类层。
3.提出了一种新方法来调整随机梯度下降法中的梯度更新和用于训练模型的反向传播算法。
三、Model:
本文提出的模型AdaMine(ADAptive MINing Embe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









