







 本文提供详细的Spark及Hadoop安装步骤,并介绍如何配置环境变量、安装PySpark等。通过具体实例演示了如何使用PySpark进行WordCount任务。
本文提供详细的Spark及Hadoop安装步骤,并介绍如何配置环境变量、安装PySpark等。通过具体实例演示了如何使用PySpark进行WordCount任务。
1.软件准备:
下载资源合集:https://download.youkuaiyun.com/download/qq_33283652/11060712
https://download.youkuaiyun.com/download/qq_33283652/11060746
- spark2.2.0 https://archive.apache.org/dist/spark/
- hadoop2.7.7 https://hadoop.apache.org/releases.html
- winutils
2.安装java,pycharm,python
3.安装spark
3.1下载并解压
3.2 配置环境变量
- 系统变量新增SPARK_HOME,值为安装路径
- ath,新增两个值:%SPARK_HOME%\bin,%SPARK_HOME%\sbin
3.3复制模板并修改conf/log4j.properties日志文件
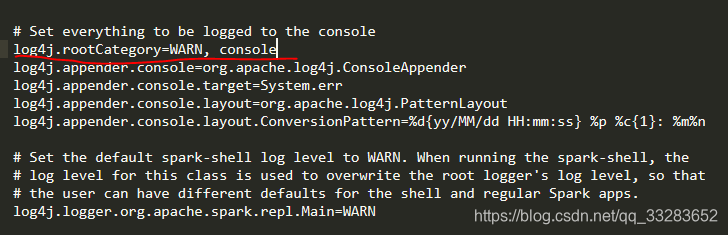
3.3 测试spark
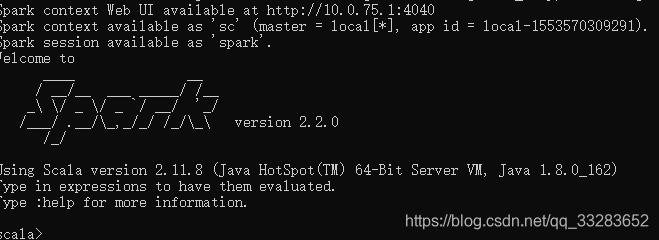
3.4 安装pyspark
将spark目录下的 ---> python目录下的 --> pyspark文件夹 复制粘贴到 python目录下的 -- >lib 目录下的 --> site-packges里面
安装py4j pip install py4j ipython
修改spark/bin/pyspark2.cmd
set PYSPARK_DRIVER_PYTHON=ipython4.安装hadoop
4.1下载并解压
4.2配置环境变量
- 新建系统变量HADOOP_HOME,值为Hadoop安装路径
- 配置系统变量PATH,添加%HADOOP_HOME%\bin
4.3 将bin-master中的文件覆盖hadoop/bin下的文件
5.pycharm新建一个spark项目
5.1 wordcount代码演示
from pyspark import SparkContext,SparkConf
if __name__ == '__main__':
conf = SparkConf().setMaster("local").setAppName("wordcount")
sc = SparkContext(conf=conf)
lines = sc.textFile("./word.txt")
words = lines.flatMap(lambda line: line.spilt(" "))
pairwords = words.map(lambda word: (word, 1))
result = pairwords.reduceByKey(lambda v1, v2: v1 + v2)
result.foreach(lambda one: print(one))
sc.stop()5.2 在edit configuration 修改路径
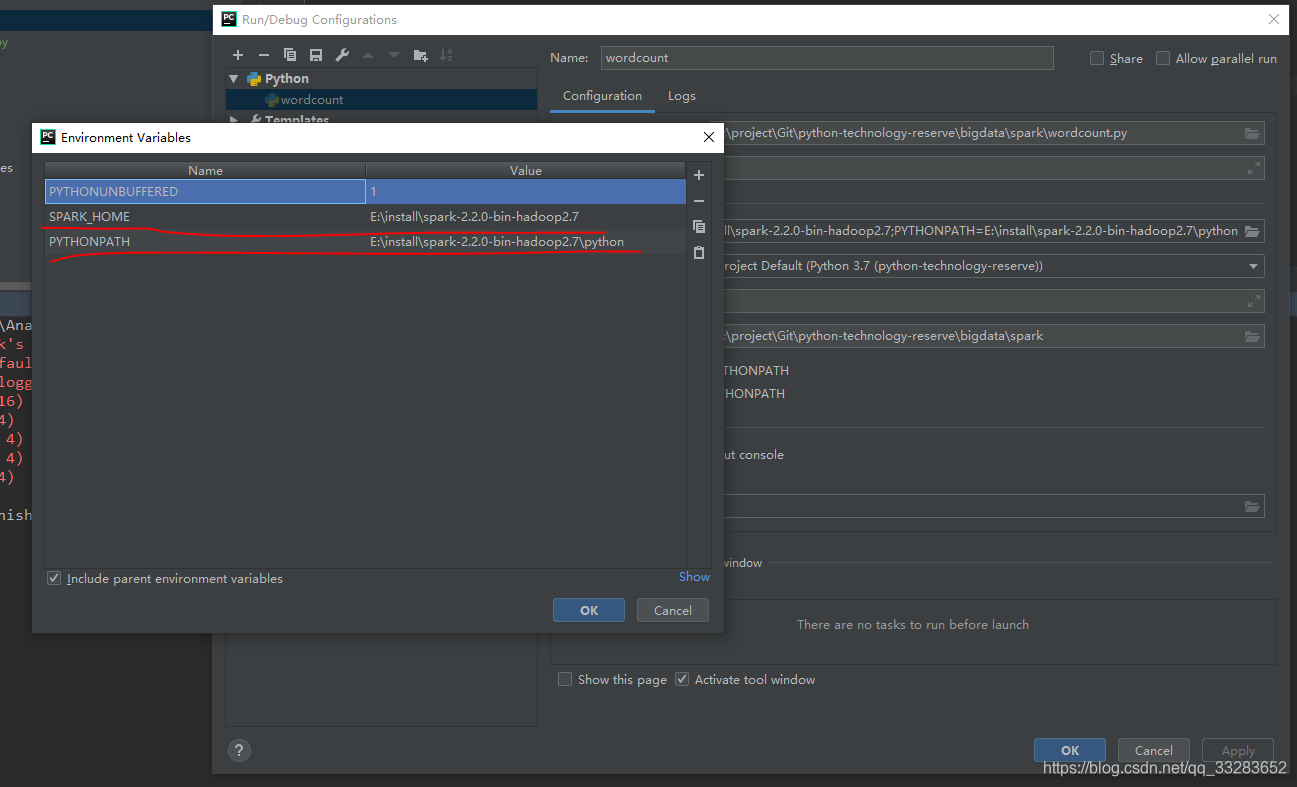
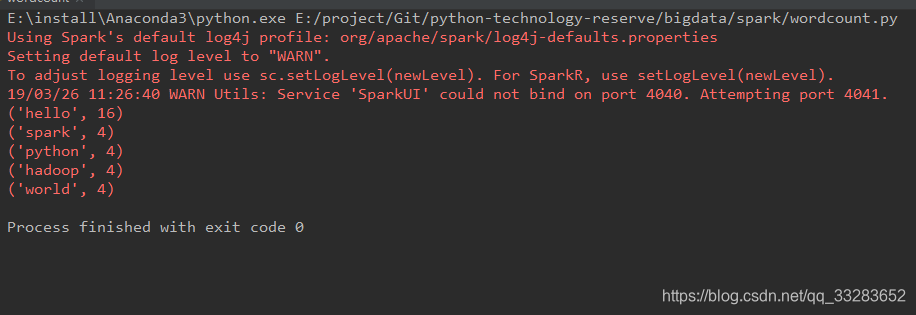
5.3 运行结果

















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









