






 本文围绕SqlServer展开,介绍了sqlcmd命令表示及使用其导入*.sql文件的方法,还涉及触发器学习、导入导出.sql文件等内容。同时列举了数据库隔离级别、查询锁表、临时表等知识,以及众多SqlServer常用命令和相关功能实现。
本文围绕SqlServer展开,介绍了sqlcmd命令表示及使用其导入*.sql文件的方法,还涉及触发器学习、导入导出.sql文件等内容。同时列举了数据库隔离级别、查询锁表、临时表等知识,以及众多SqlServer常用命令和相关功能实现。
SQLCMD命令表示
Sqlcmd [-U 登录 ID] [-P 密码]
[-S 服务器] [-H 主机名] [-E 可信连接]
[-d 使用数据库名称] [-l 登录超时值] [-t 查询超时值]
[-h 标题] [-s 列分隔符] [-w 屏幕宽度]
[-a 数据包大小] [-e 回显输入] [-I 允许带引号的标识符]
[-c 命令结束] [-L[c] 列出服务器[清除输出]]
[-q “命令行查询”] [-Q “命令行查询” 并退出]
[-m 错误级别] [-V 严重级别] [-W 删除尾随空格]
[-u unicode 输出] [-r[0|1] 发送到 stderr 的消息]
[-i 输入文件] [-o 输出文件] [-z 新密码]
[-f <代码页> | i:<代码页>[,o:<代码页>]] [-Z 新建密码并退出]
[-k[1|2] 删除[替换]控制字符]
[-y 可变长度类型显示宽度]
[-Y 固定长度类型显示宽度]
[-p[1] 打印统计信息[冒号格式]]
[-R 使用客户端区域设置]
[-b 出错时中止批处理]
[-v 变量 = “值”…] [-A 专用管理连接]
[-X[1] 禁用命令、启动脚本、环境变量[并退出]]
[-x 禁用变量情况]
[-? 显示语法摘要]SqlServer使用sqlcmd导入*.sql文件
sqlcmd -S . -U sa -P sa -d database -i d:\data.sql
参数说明:-S 服务器地址 -U 用户名 -P 密码 -d 数据库名称 -i 脚本文件路径
sqlcmd -S xx.xx.xx.xx -U SA -P Xh562386 -d tsumitate_mwt_it -i ./insert_voucher_status.sqlSqlServer触发器学习
https://www.cnblogs.com/selene/p/4493311.htmlSqlServer导入导出.sql文件
导出:
https://www.cnblogs.com/jiechn/p/4876245.html
如果某些字段设置了COLLATE排序规则,则需要设置Script Collation为true
导出命令模式
sqlcmd -S IP地址 -U SA -P 密码 -d 库名 -Q "select a.[text] from syscomments A inner join sysobjects B on A.ID = B.ID where b.xtype = 'P' and b.name = 'ImportZenginData'" -o "输出文件路径"
参考案列
sqlcmd -S 192.168.7.xx -U SA -P Xh562386 -d tsumitate_mwt_it -Q "select a.[text] from syscomments A inner join sysobjects B on A.ID = B.ID where b.xtype = 'P' and b.name = 'ImportZenginData'" -o "/home/ImportZenginData.sql"
导入:
SqlServer安装在远程的Linux上的,导入通过sqlcmd工具导入的。
sqlcmd工具下载地址:https://docs.microsoft.com/zh-cn/sql/tools/sqlcmd-utility?view=sql-server-2017
本案例是通过Windows远程连接访问的,所以下载的是Windows版的sqlcmd工具。
下载完成后
sqlcmd -S ip -U 用户名 -i D:\ldd_rj\2020-10-30\xxx.sql <-d 数据库名>
注意:
如果xxx.sql文件中存在创建库等命令,并且xxx.sql文件中已经指定了库名。那么可以不用通过指定-d
数据库名。但是如果想用一个新库名,通过-d 数据库名指定即可。SqlSever数据库隔离级别
sqlserver默认隔离级别是读已提交。但是它的读已提交定义和别的数据库其实是不一样的,写会阻塞
读,一定条件下读也会阻塞写,非常影响高并发系统性能。
https://www.cnblogs.com/chenmh/p/3998614.html
https://www.cnblogs.com/princessd8251/p/4188947.html
https://www.cnblogs.com/leohahah/p/8464575.html
SQL Server开启READ_COMMITTED_SNAPSHOT
--查询数据库状态
select name,user_access,user_access_desc,
snapshot_isolation_state,snapshot_isolation_state_desc,
is_read_committed_snapshot_on
from sys.databases
--设置数据库为SINGLE_USER模式,减少锁定时间
ALTER DATABASE dbname SET SINGLE_USER WITH ROLLBACK IMMEDIATE
ALTER DATABASE dbname SET ALLOW_SNAPSHOT_ISOLATION ON
ALTER DATABASE dbname SET READ_COMMITTED_SNAPSHOT ON
ALTER DATABASE dbname SET MULTI_USER
SqlServer查询锁表
查询被锁住的表
select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName
from sys.dm_tran_locks where resource_type='OBJECT'
--spid 锁表进程
--tableName 被锁表名
解锁:
declare @spid int
Set @spid = 57 --锁表进程
declare @sql varchar(1000)
set @sql='kill '+cast(@spid as varchar)
exec(@sql)
--查询出死锁的SPID
select blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses where blocked>0 ) b
where a.blocked=spid)
--输出引起死锁的操作
DBCC INPUTBUFFER (@spid)
--查询当前进程数
select count(-1) from sysprocesses
where dbid in (select dbid from sysdatabases where name like '%telcount%');SqlServer临时表
临时表与永久表相似,但临时表存储在tempdb中,当不再使用时会自动删除。临时表有两种类型:本地和
全局。它们在名称、可见性以及可用性上有区别。
对于临时表有如下几个特点:
1.本地临时表就是用户在创建表的时候添加了“#”前缀的表,其特点是根据数据库连接独立。只有创建本地临
时表的数据库连接有表的访问权限,其它连接不能访问该表;
2.不同的数据库连接中,创建的本地临时表虽然“名字”相同,但是这些表之间相互并不存在任何关系;
在SQLSERVER中,通过特别的命名机制保证本地临时表在数据库连接上的独立性。
3.真正的临时表利用了数据库临时表空间,由数据库系统自动进行维护,因此节省了表空间。并且由于
临时表空间一般利用虚拟内存,大大减少了硬盘的I/O次数,因此也提高了系统效率。
4.临时表在事务完毕或会话完毕数据自动清空,不必记得用完后删除数据。本地临时表
本地临时表的名称以单个数字符号 (#) 打头;它们仅对当前的用户连接(也就是创建本地临时表的
connection)是可见的;当用户从 SQL Server 实例断开连接时被删除。
例如我们在一个数据库连接中用如下语句创建本地临时表#Temp
CREATE TABLE #Temp
(
id int,
customer_name nvarchar(50),
age int
)
然后同时启动数据库连接2,执行查询#Temp的操作
数据库连接2:
select * from #Temp
抛出错误:
Invalid object name '#Temp'
结果显示,数据库连接2找不到表#Temp。这说明#Temp这张临时表,只是对创建它的数据库连接1可
见,而对于数据库连接2来说是不可见的。
全局临时表
全局临时表的名称以两个数字符号 (##) 打头,创建后对任何数据库连接都是可见的,当所有引用该表的数据库连接从 SQL Server 断开时被删除。
例如我们在一个数据库连接中用如下语句创建全局临时表##Temp,然后插入三行数据
CREATE TABLE ##Temp
(
id int,
customer_name nvarchar(50),
age int
)
INSERT INTO ##Temp VALUES(1,'老王',20),(2,'老张',30),(3,'老李',25)
接着我们在数据库连接2中,查询##Temp的数据
select * from ##Temp
可以查询到数据。
可以看到,数据库连接2可以成功访问到数据库连接1创建的全局临时表##Temp,但是如果我们现在关闭
数据连接1,然后再执行数据库连接2的##Temp查询语句会发生什么呢?结果如下:
关闭数据库连接1,然后数据库连接2再次执行:
select * from ##Temp
报错:Invalid object name '##Temp'.
我们发现关闭数据库连接1后,数据库连接2就找不到全局临时表##Temp了。这是因为数据库连接1被关
闭后,数据库连接2此时也没有语句正在使用临时表##Temp,所以Sqlserver认为此时已经没有数据库
连接在引用全局临时表##Temp了,就将##Temp释放掉了。
接下来,我们尝试在数据库连接2中对全局临时表##Temp持有事务中的排他锁(X锁)后,然后关闭数据库
连接1.
CREATE TABLE ##Temp
(
id int,
customer_name nvarchar(50),
age int
)
INSERT INTO ##Temp VALUES(1,'老王',20),(2,'老张',30),(3,'老李',25)
数据库连接2:
BEGIN TRAN
select * from ##Temp with(xlock)
关闭数据库连接1,然后数据库连接2执行:
select * from ##Temp
结果显示我们尽管关闭了数据库连接1,但是由于数据库连接2在事务中一直持有全局临时表##Temp的排
他锁(X锁),所以临时表##Temp并没有随着数据库连接1的关闭而被释放掉,只要数据库连接2中启动
的事务没有被回滚或提交,那么数据库连接2会一直持有临时表##Temp的排他锁,这时Sqlserver会认
为还有数据库连接正在引用全局临时表##Temp,所以##Temp不会被释放掉。
转载:https://www.cnblogs.com/OpenCoder/p/7576602.html查询SqlServer隔离级别
--查看SQL事务隔离级别
DBCC USEROPTIONS
textsize -1
language us_english
dateformat ymd
datefirst 7
lock_timeout -1
quoted_identifier SET
ansi_null_dflt_on SET
ansi_warnings SET
ansi_padding SET
ansi_nulls SET
concat_null_yields_null SET
isolation level read committed --隔离级别
--设置连接会话事务隔离级别
set transaction isolation level <隔离级别>
--例如
set transaction isolation level SNAPSHOT
set transaction isolation level Read Uncommitted
0.SqlServer常用命令|排序规则
SqlServer常用命令整理:
--版本信息
SELECT @@VERSION
--查询所有数据库名
SELECT Name FROM Master..SysDatabases
--查询所有的触发器
select * from sysobjects where xtype like 'tr%'
--分析单个触发器创建语句
exec sp_helptext 'dbo.tr_haraidasi_yotei_henkou_rireki'
--查看当前SQLServer版本支持的排序规则
select * from fn_helpcollations() where name like '%Japanese_90_CI_AI_SC_UTF8%'
--查看服务器默认排序规则
select SERVERPROPERTY('Collation')
--查看实例下所有数据库的排序规则
select name,collation_name from sys.databases
--查看服务器排序使用字符集名称
select SERVERPROPERTY('SqlCharSetName')
-- 查询字符集(排序规则)对应的code数值
SELECT COLLATIONPROPERTY('Japanese_90_CI_AI_SC_UTF8', 'CodePage');
--查询数据当前正在使用的连接
select * from master.sys.sysprocesses where dbid = db_id('数据库名')
--断开连接
kill spid号
--断开某个库的所有连接
declare @i int declare cur cursor for select spid from sysprocesses where db_name(dbid)= '数据库名' open cur fetch next from cur into @i while @@fetch_status=0 begin exec('kill '+@i) fetch next from cur into @i end close cur deallocate cur
--查询SqlServer所有登录名
select name from syslogins
--查看所有数据库用户所属的角色信息
sp_helpsrvrolemember
查看当前SqlServer数据库支持的排序规则:
select * from fn_helpcollations()
举例:
Japanese_90_CS_AS_KS_WS
Chinese_Hong_Kong_Stroke_90_CS_AI_KS_WS
Chinese_PRC_90_CS_AI_WS
...
...
解释:
前半部份:指UNICODE字符集
后半部份:
_BIN 二进制排序
_CI(CS) 是否区分大小写,CI不区分,CS区分
_AI(AS) 是否区分重音,AI不区分,AS区分
_KI(KS) 是否区分假名类型,KI不区分,KS区分
_WI(WS) 是否区分宽度 WI不区分,WS区分
区分大小写:如果想让比较将大写字母和小写字母视为不等,请选择该选项。
区分重音:如果想让比较将重音和非重音字母视为不等,请选择该选项。如果选择该选项,比较还将重音不同的
字母视为不等。
区分假名:如果想让比较将片假名和平假名日语音节视为不等,请选择该选项。
区分宽度:如果想让比较将半角字符和全角字符视为不等,请选择该选项 1.字符集
--查看当前SQLServer版本支持的排序规则
select * from fn_helpcollations()
--查看当前SQLServer版本支持的排序规则(只查询UTF8 )
select * from fn_helpcollations() where name like '%UTF8%'
结果集:
Japanese_90_CI_AI_SC_UTF8
...
...
...
--查看字符集对应的code数值
SELECT COLLATIONPROPERTY('Japanese_90_CI_AI_SC_UTF8', 'CodePage');
查询出来的结果:65001
936 简体中文GBK
950 繁体中文BIG5
437 美国/加拿大英语
932 日文
949 韩文
866 俄文
65001 unicode UFT-82.mssql-conf命令
--启动
systemctl start mssql-server
--停止
systemctl stop mssql-server
--重启
systemctl restart mssql-server
--查询SqlServer状态
systemctl status mssql-server[mssql@localhost bin]$ ./mssql-conf
usage: mssql-conf [-h] [-n] ...
positional arguments:
setup 初始化并设置 Microsoft SQL Server。
set 设置某个设置的值
unset 取消设置某个设置的值
list 列出受支持的设置
traceflag 启用/禁用一个或多个跟踪标志
set-sa-password
设置系统管理员(SA)密码
set-collation 设置系统数据库的排序规则
validate 验证配置文件
set-edition 设置 SQL Server 实例的版本
optional arguments:
-h, --help show this help message and exit
-n, --noprompt 不提示用户并使用环境变量或默认值。例如:设置服务器的排序规则

3.系统库
--查询所有数据库名
SELECT Name FROM Master..SysDatabases
1.master数据库
master数据库记录SQLServer系统的所有系统级别信息,它记录所有的登录帐户和系统配置设置,记录所有其它
的数据库,其中包括数据库文件的位置。master数据库记录SQLServer的初始化信息,它始终有一个可用的最
新master数据库备份。
2.tempdb数据库
tempdb数据库保存所有的临时表和临时存储过程。tempdb数据库是全局资源,所有连接到系统的用户的临时表和
存储过程都存储在该数据库中。tempdb数据库在SQLServer每次启动时都重新创建,因此该数据库在系统启动时总
是干净的。临时表和存储过程在连接断开时自动除去,而且当系统关闭后将没有任何连接处于活动状态,因此
tempdb数据库中没有任何内容会从SQLServer的一个会话保存到另一个会话。
3.model数据库
model数据库用作在系统上创建的所有数据库的模板。当发出CREATE DATABASE语句时,新数据库的第一部分
通过复制model数据库中的内容创建,剩余部分由空页填充。由于SQLServer每次启动时都要创建tempdb数据库
,model数据库必须一直存在于SQLServer系统中。
4.msdb数据库
msdb数据库供SQLServer代理程序调度警报和作业以及记录操作员时使用。4.Linux命令行访问SqlServer
--输入命令回车
sqlcmd -S ip -U sa -p
5.分离和添加数据库
在Linux环境下通过sqlcmd进入SqlServer实例,然后进行分离和添加操作。
分离数据库:表示将数据库从SQL Server实例中去除,但不是物理性的删除。
sp_detach_db '数据库名'
添加数据库:
EXEC sp_attach_db @dbname = N'目标数据库名', //这是你要引入后的数据库名。
@filename1 = N'源数据库DATA文件完整路径及文件名.MDF', //指明源数据库的数据文件
@filename2 = N'源数据库LOG文件完整路径及文件名.LDF' //指明源数据库日志文件
注:最后一行不要加逗号。
-rw-rw----. 1 mssql mssql 75497472 11月 9 01:49 tsumitate_mwt.mdf
-rw-rw----. 1 mssql mssql 8388608 11月 9 01:50 tsumitate_mwt1.mdf
-rw-rw----. 1 mssql mssql 8388608 11月 9 01:50 tsumitate_mwt1_log.ldf
-rw-rw----. 1 mssql mssql 8388608 11月 9 02:34 tsumitate_mwt2.mdf
-rw-rw----. 1 mssql mssql 75497472 11月 9 02:34 tsumitate_mwt2_log.ldf
-rw-rw----. 1 mssql mssql 276824064 11月 9 01:50 tsumitate_mwt_log.ldf
6.错误日志
运行错误日志:
默认保留有7个 SQL Server 错误日志文件,分别是:ErrorLog,Errorlog.1~Errorlog.6 ,当前的错误日志
(文件ErrorLog)没有扩展名。每当启动 SQL Server 实例时,将创建新的错误日志ErrorLog,并将之前的
ErrorLog更名为ErrorLog.1,之前的ErrorLog.1更名为ErrorLog.2,依次类推,原先的ErroLog.6被删除。
-rw-rw----. 1 mssql mssql 10047 11月 10 01:31 errorlog
-rw-rw----. 1 mssql mssql 34663 11月 10 00:07 errorlog.1
-rw-rw----. 1 mssql mssql 11791 11月 9 08:02 errorlog.2
-rw-------. 1 mssql mssql 21491 11月 9 07:42 errorlog.3
-rw-rw----. 1 mssql mssql 14171 11月 9 07:41 errorlog.4
-rw-------. 1 mssql mssql 10943 11月 9 07:13 errorlog.5
-rw-------. 1 mssql mssql 0 11月 9 07:13 errorlog.6
代理错误日志:
系统维护10个SQL Server Agent 错误日志.文件名分别是:SQLAgent.out、SQLAgent.n(n=1、2、3、4、5、
6、7、8、9),其中SQLAgent.out记录代理当前的消息,其更新方式和SQL Server日志文件相同。
-rw-rw----. 1 mssql mssql 6880 11月 9 08:03 sqlagent.1
-rw-rw----. 1 mssql mssql 6880 11月 9 07:43 sqlagent.2
-rw-------. 1 mssql mssql 808 11月 9 07:42 sqlagent.3
-rw-rw----. 1 mssql mssql 6880 11月 9 07:15 sqlagent.4
-rw-------. 1 mssql mssql 808 11月 9 07:13 sqlagent.5
-rw-rw----. 1 mssql mssql 6880 11月 10 00:08 sqlagent.out
注意:
SQL Server代理维护它自己的错误日志,和SQL Server错误日志分开。
https://blog.youkuaiyun.com/weixin_33806300/article/details/85803412?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.channel_param
--查看 ErrorLog 文件的创建日期和大小,其创建日期就是第一条记录插入的日期。
exec sys.xp_enumerrorlogs
6 11/09/2020 07:13 0
5 11/09/2020 07:13 10943
4 11/09/2020 07:41 14171
3 11/09/2020 07:42 21491
2 11/09/2020 08:02 11791
1 11/10/2020 00:07 34663
0 11/10/2020 01:31 10047
SQL Server提供了存储过程sys.xp_readerrorlog及sys.sp_readerrorlog,用于查看错误日志。
sys.xp_readerrorlog 存储过程有7个参数,按照参数的顺序,它们依次是:
1.@Archive,存档编号(0~99),其值是 sys.xp_enumerrorlogs返回的Archive#字段的值, 默认值是0,
0 代表的是ErrorLog,1代表的是ErrorLog.1。
2.@Logtype,日志类型,有效值是1和2,1代表SQL Server日志,2代表SQL Server Agent日志,默认值是1
3.@SearchText1,查询包含的字符串,大小是255,默认值是null,
4.@SearchText2,查询包含的字符串,大小是255,默认值是null,参数3和参数4的逻辑关系是and(与关系),表示同时包含这两个文本。
5.@StartTime,消息的开始时间
6.@End'Time,消息的结束时间
7.@Order,对结果排序,按LogDate排序(Desc、Asc)对输出结果排序
sys.sp_readerrorlog有四个参数,和sys.xp_readerrorlog的前四个参数相同,sys.sp_readerrorlog内部使用sys.xp_readerrorlog来实现。
案列:
查看登陆失败的错误日志,可以看到参数4和参数5是过滤Text字段。
exec sys.sp_readerrorlog 0,1,'login','failed'
7.锁定为单用户
--锁定为单用户
ALTER DATABASE 数据库 SET SINGLE_USER WITH ROLLBACK IMMEDIATE
-- 解锁为多用户
ALTER DATABASE tsumitate_mwt SET MULTI_USER
实例:
今天在使用SQL Server时,由于之前创建数据库忘记了设置Collocation,数据库中插入中文字符都是乱码,于
是到DataBase的Options中修改Collocation,出现了The database could not be exclusively locked to
perform the operation这个错误,无法修改字符集为Chinese_PRC_90_CI_AS。
解决办法找了很久才找到,如下:
1.执行SQL ALTER DATABASE db_database SET SINGLE_USER WITH ROLLBACK IMMEDIATE
修改为单用户模式
2.然后关闭所有的查询窗口,修改Options的Collocation属性为Chinese_PRC_90_CI_AS
3.执行SQL ALTER DATABASE db_database SET MULTI_USER
再修改为多用户模式8.关闭自增ID
SqlServer在导入数据的时候,有时候要考虑id不变,就要先取消自动增长再导入数据,导完后恢复自增。
set IDENTITY_INSERT tableName ON //设置为允许手动插入值
INSERT INTO tableName (id,product) VALUES (2,'screwdriver')
set IDENTITY_INSERT tableName OFF //设置为禁止手动插入值
注:创建一个存在自增键的表
CREATE TABLE [dbo].[aa_version_identity] (
[identity_id] int NOT NULL IDENTITY(1,1) ,
[identity_name] nvarchar(20) COLLATE Japanese_90_CI_AI_SC_UTF8 NOT NULL ,
[version_no] int NOT NULL
)9.创建库语句
use master
go
if exists(select * from sysdatabases where name='CommonPermission')
begin
select '该数据库已存在'
drop database CommonPermission --如果该数据库已经存在,那么就删除它
end
else
begin
create database CommonPermission
on primary --表示属于 primary 文件组
(
name='cpDB_data', -- 主数据文件的逻辑名称
filename='C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQL\MSSQL\DATA\cpDB_data.mdf', -- 主数据文件的物理名称
size=5mb, --主数据文件的初始大小
maxsize=100mb, -- 主数据文件增长的最大值
filegrowth=15% --主数据文件的增长率
)
log on
(
name='cpDB_log', -- 日志文件的逻辑名称
filename='C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQL\MSSQL\DATA\cpDB_log.ldf', -- 日志文件的物理名称
size=2mb, --日志文件的初始大小
maxsize=20mb, --日志文件增长的最大值
filegrowth=1mb --日志文件的增长率
)
end10.创建用户
转载
https://www.cnblogs.com/vuenote/p/10143434.html
https://www.cnblogs.com/xiaowunian/p/10004762.html
https://www.cnblogs.com/xulinjun/p/12000516.html
11.服务器角色
服务器角色:是针对SQL Server登录名、Windows 帐户的,而某个数据库中建立的用户是不能具有服务器角色
的。例如:任何登录名建立后默认都是public服务器角色,public没有权限建立新的数据库;如果登录名具有
dbcreator服务器角色,用它登录后,就可以创建新数据库;如果登录名具有securityadmin服务器角色,用它登
录后,就可以管理其他登录名。
sysadmin 固定服务器角色的成员可以在服务器中执行任何活动
serveradmin 固定服务器角色的成员可以更改服务器范围内的配置选项并关闭服务器
securityadmin 固定服务器角色的成员管理登录名及其属性。 他们可以 GRANT、DENY 和 REVOKE 服务器级权
限。 他们还可以 GRANT、DENY 和 REVOKE 数据库级权限(如果他们具有数据库的访问权限)。 此外,他们还
可以重置 SQL Server 登录名的密码。
processadmin 固定服务器角色的成员可以终止在 SQL Server 实例中运行的进程
setupadmin 固定服务器角色的成员可以添加和删除链接服务器
bulkadmin 固定服务器角色的成员可以运行 BULK INSERT 语句
diskadmin 固定服务器角色用于管理磁盘文件
dbcreator 固定服务器角色的成员可以创建、更改、删除和还原任何数据库
public 每个 SQL Server 登录名均属于 public 服务器角色12.数据库角色
数据库角色:作用范围数据,而非服务器(db_owner 和 db_securityadmin 数据库角色的成员可以管理固定数
据库角色成员身份。 只有db_owner 数据库角色的成员能够向 db_owner 角色中添加成员)
db_owner :固定数据库角色的成员可以执行数据库的所有配置和维护活动,还可以删除数据库
db_securityadmin :固定数据库角色的成员可以修改角色成员身份和管理权限。 向此角色中添加主体可能会导致意外的权限升级
db_accessadmin: 固定数据库角色的成员可以为 Windows 登录名、Windows 组和 SQL Server 登录名添加或删除数据库访问权限
db_backupoperator: 固定数据库角色的成员可以备份数据库
db_ddladmin: 固定数据库角色的成员可以在数据库中运行任何数据定义语言 (DDL) 命令
db_datawriter :固定数据库角色的成员可以在所有用户表中添加、删除或更改数据
db_datareader: 固定数据库角色的成员可以从所有用户表中读取所有数据
db_denydatawriter: 固定数据库角色的成员不能添加、修改或删除数据库内用户表中的任何数据
db_denydatareader: 固定数据库角色的成员不能读取数据库内用户表中的任何数据13.SqlServer代理
SQL Server 代理是一种bai Microsoft Windows 服务,它在 SQL Server 中执行计du划的管理任务,即“作
业zhi”。
SQL Server 代理使用 SQL Server 来存储作dao业信息。作业包含一个或多个作业步骤。 每个步骤都有自己的
任务。例如,备份数据库。
SQL Server 代理可以按照计划运行作业,也可以在响应特定事件时运行作业,还可以根据需要运行作业。
例如,如果希望在每个工作日下班后备份公司的所有服务器,就可以使该任务自动执行。 将备份安排在星期一到
星期五的 22:00 之后运行,如果备份出现问题,SQL Server 代理可记录该事件并通知您。14.mdf和.ldf文件
.mdf:是数据库数据文件,存放一个数据库的数据信息。
.ldf:是数据库日志文件,即日常对数据库的操作的记录如(增、删、改)的文件。15.sqlserver 查询指定表操作记录
SELECT TOP 1000
CONVERT(varchar(100), QS.creation_time, 20), SUBSTRING(ST.text, (QS.statement_start_offset / 2) + 1,
((CASE QS.statement_end_offset WHEN - 1 THEN DATALENGTH(st.text) ELSE QS.statement_end_offset END - QS.statement_start_offset) / 2) + 1)
AS statement_text, ST.text, QS.total_worker_time, QS.last_worker_time, QS.max_worker_time, QS.min_worker_time
FROM
sys.dm_exec_query_stats QS
--关键字
CROSS APPLY
sys.dm_exec_sql_text(QS.sql_handle) ST
WHERE
--QS.creation_time BETWEEN '2019-08-10 00:00:00' AND '2020-11-18 00:00:00'
-- AND ST.text NOT LIKE '%SELECT * FROM T_LOCATIONINFO WHERE STRCLIPLOGICID in(%'
--AND
ST.text LIKE '%campaign_master%'
ORDER BY
QS.creation_time DESC
转载记录:
https://www.cnblogs.com/guanxiaohe/p/13983730.html16.sqlserver 实现rownum 的功能
SELECT
row_number() over(order by a.version_no desc) as num,
a.version_no label
FROM
convenience_store_payment a
num label
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 1
17.sqlserver 类似MySql的LAST_INSERT_ID()函数
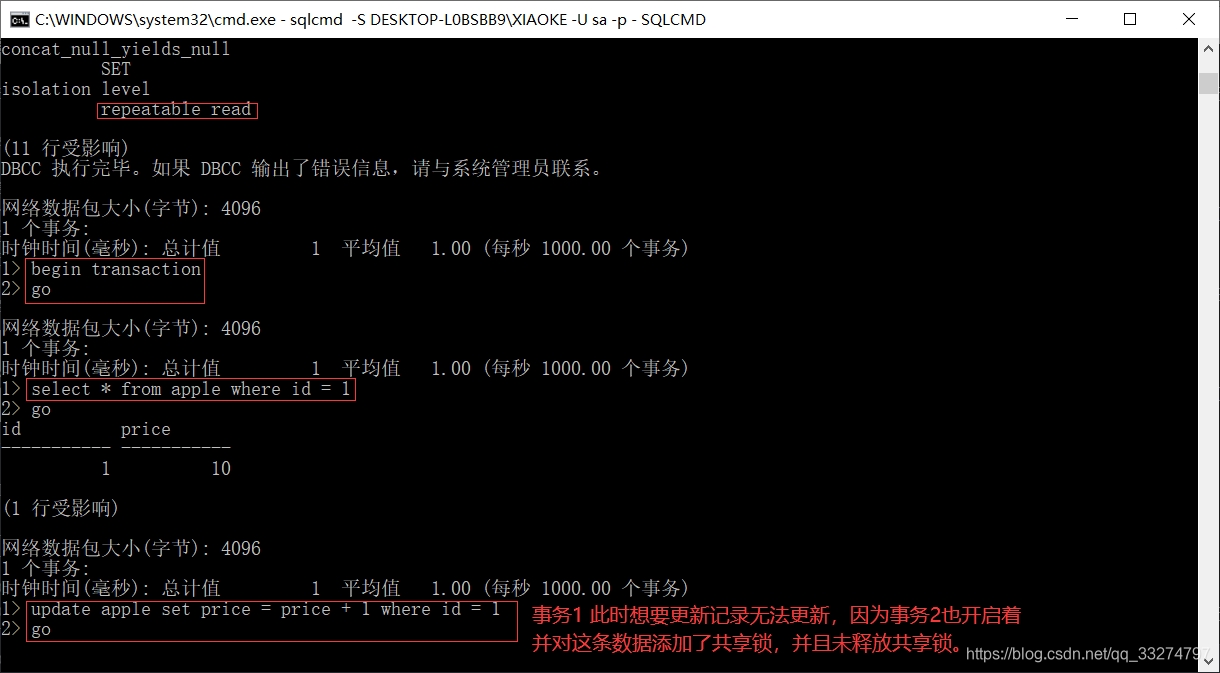
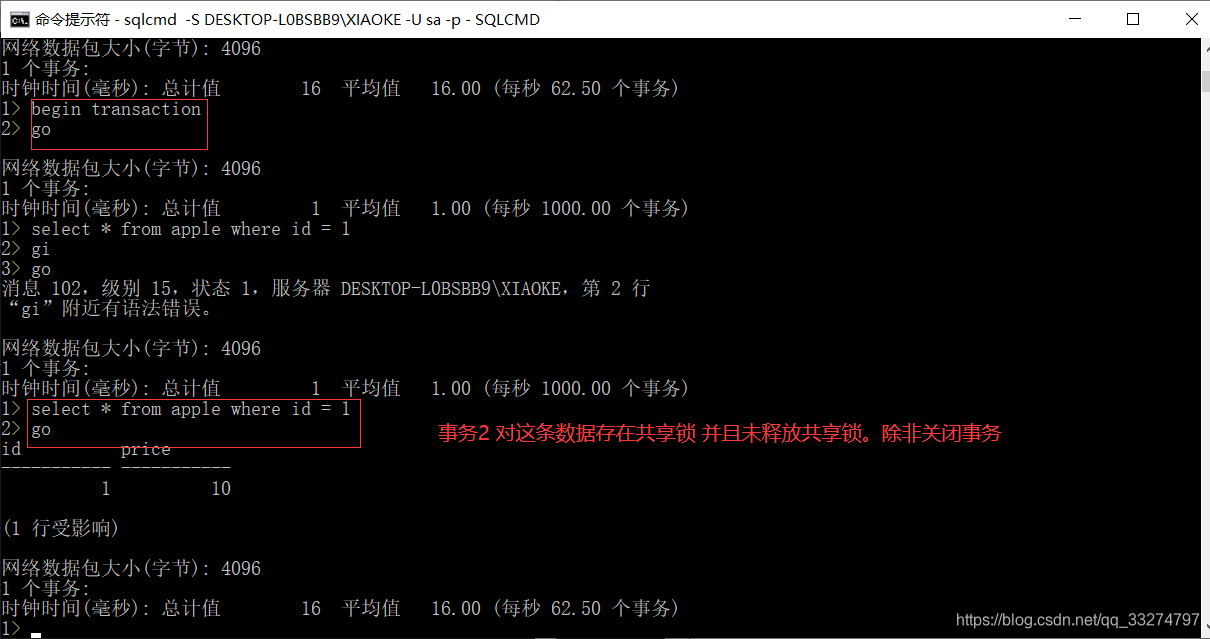
SELECT @@IDENTITY AS 'Identity'18.可重复读
REPEATABLE READ(可重复读):保证在一个事务中的两个读操作之间,其他的事务不能修改当前事务读取的数
据,该级别事务获取数据前必须先获得共享锁同时获得的共享锁不立即释放一直保持共享锁至事务完成,所以此
隔离级别查询完并提交事务很重要。
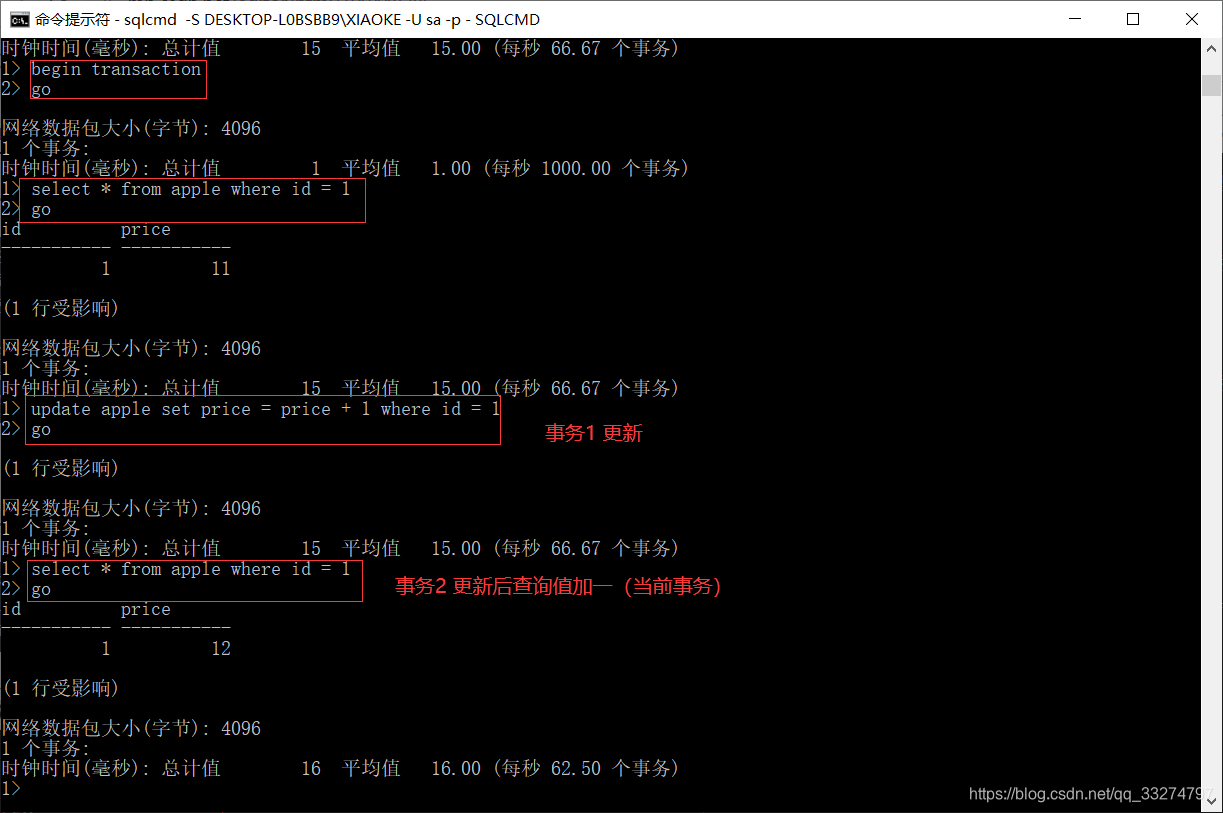
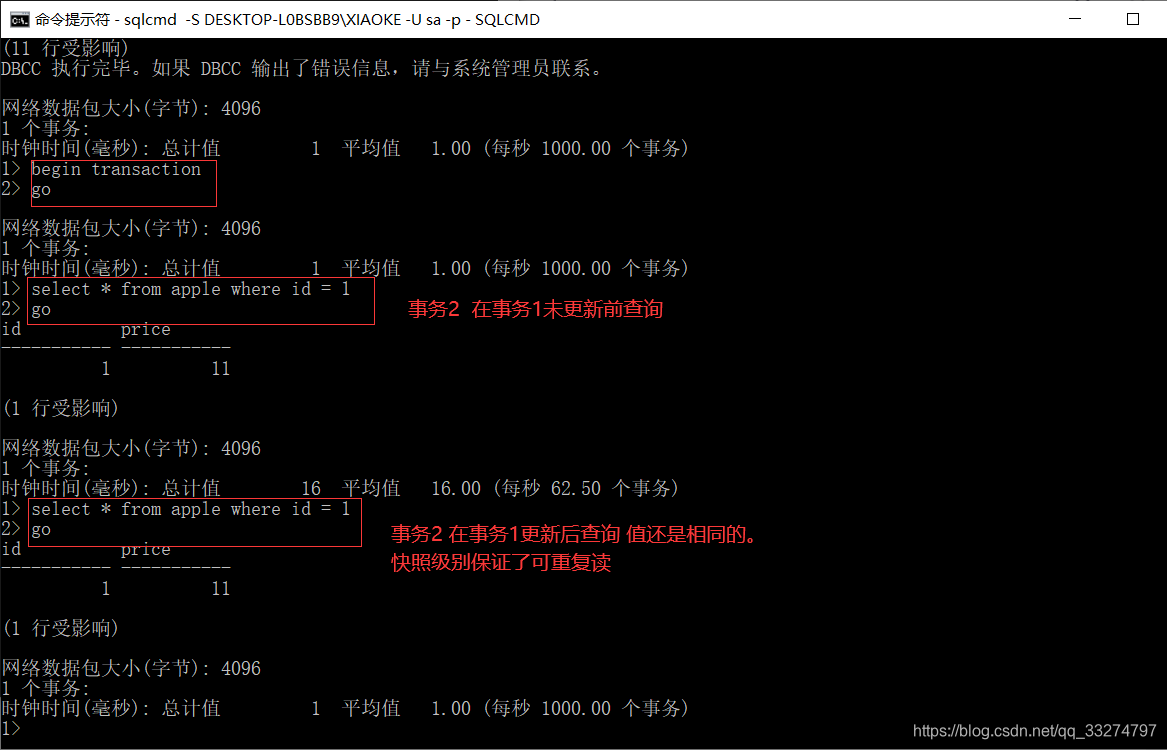
19.SNAPSHOT快照
SNAPSHOT 在SNAPSHOT隔离级别下,当读取数据时可以保证操作读取的行是事务开始时可用的最后提交版本
同时SNAPSHOT隔离级别也满足前面的已提交读,可重复读,不幻读;该隔离级别实用的不是共享锁,而是行版本控制
使用SNAPSHOT隔离级别首先需要在数据库级别上设置相关选项。
在打开的所有查询窗口中执行以下操作
允许开启快照模式
ALTER DATABASE TEST SET ALLOW_SNAPSHOT_ISOLATION ON;
20.读已提交
READ COMMITTED(已提交读)是SQL SERVER默认的隔离级别,可以避免读取未提交的数据,该隔离级别
读操作之前首先申请并获得共享锁,允许其他读操作读取该锁定的数据,但是写操作必须等待锁释
放,一般读操作读取完就会立刻释放共享锁。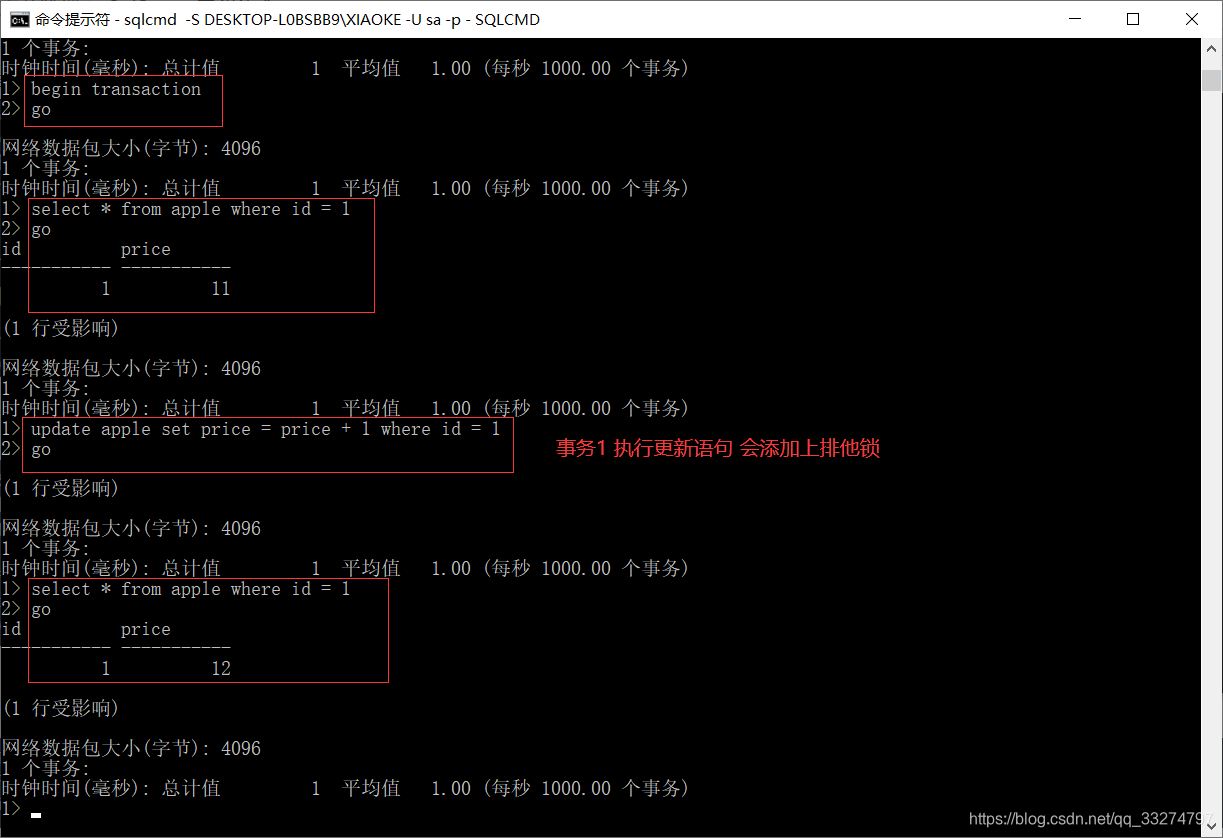
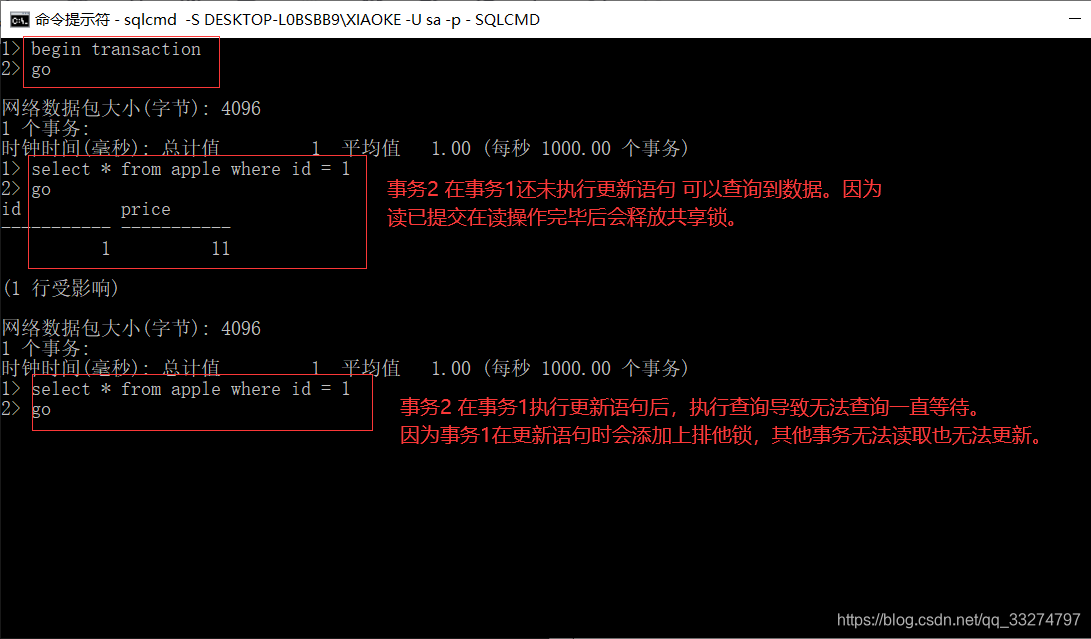
21.读未提交
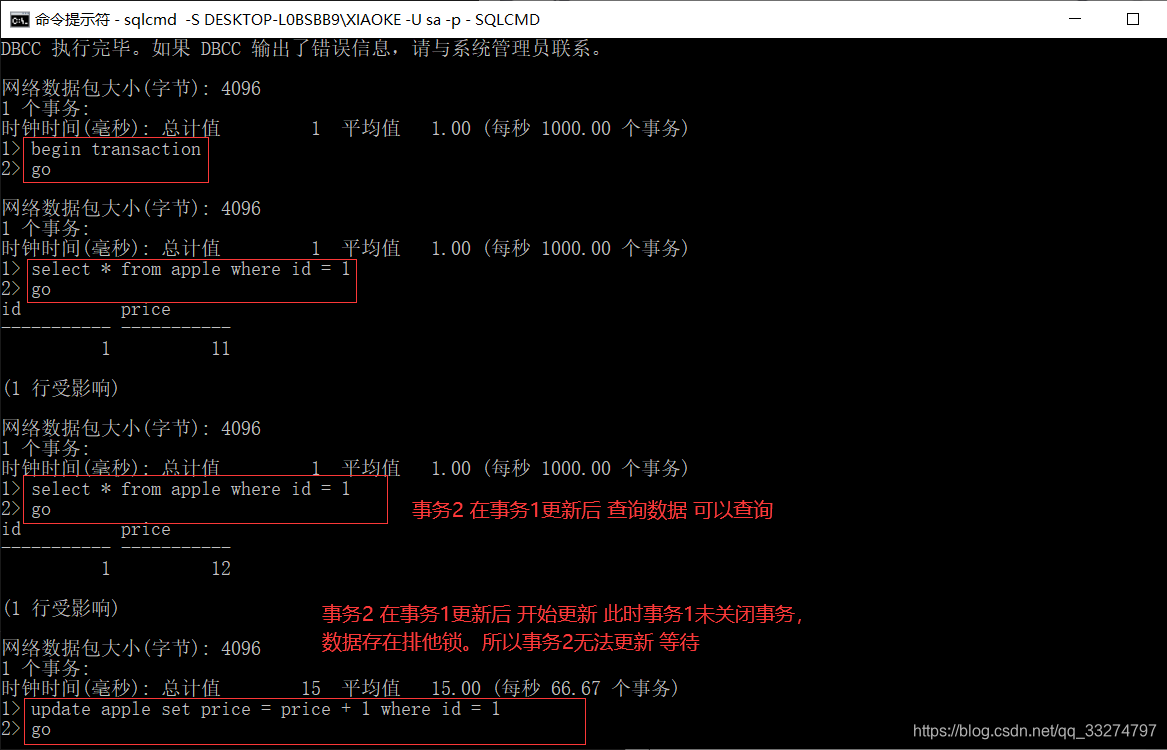
READ UNCOMMITTED:读操作不申请锁,运行读取未提交的修改,也就是允许读脏数据,读操作不会影响写操作请
求排他锁.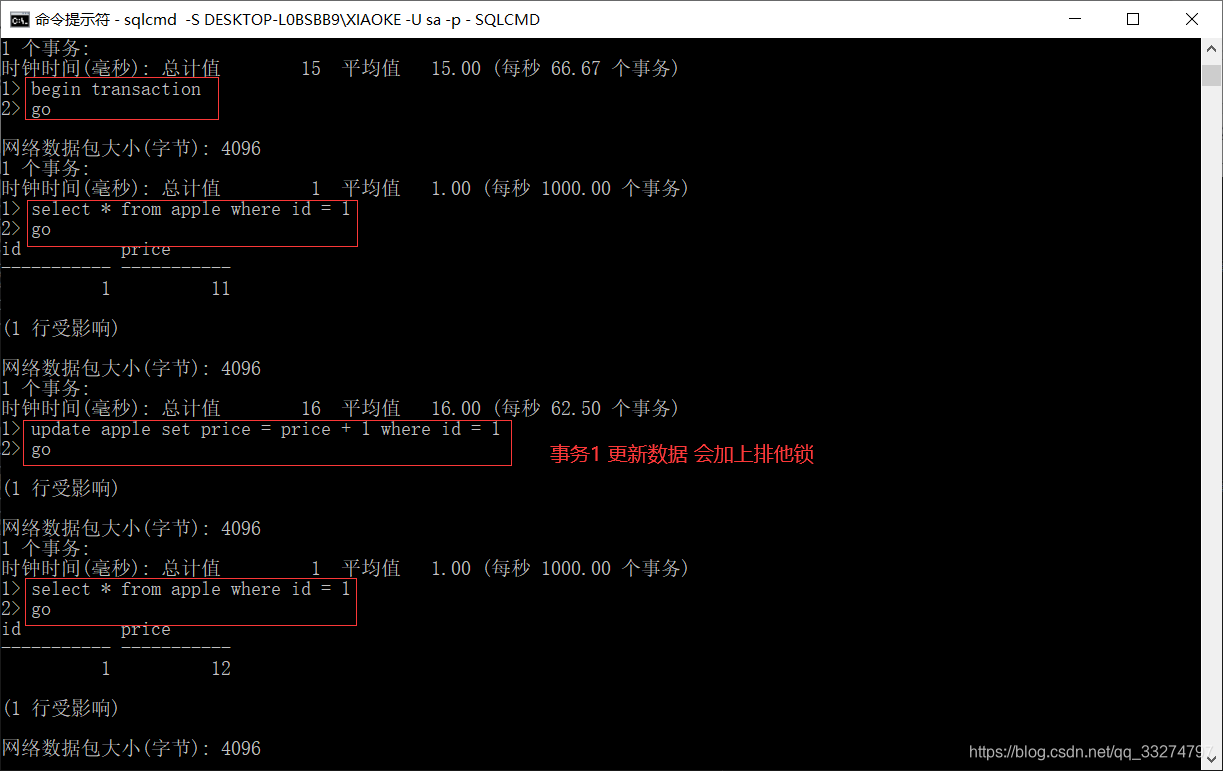

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









