






关注 ▲对白▲ 和百万AI爱好者,一起向上生长

这是对白的第 88 期分享
作者 l 不是大叔 出品 l 对白的算法屋
大家好,我是对白。
今天给大家总结了ACL2021中关于对比学习的论文,一共8篇,每篇都通过一句话进行了核心思想的介绍,希望对大家有所帮助。
1. CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
- 用同/反义词构造正负例,三个损失:①MLM;②预测每个token是否被替换,0/1二分类;③对比损失,即正例拉近,反例远离。
2. Self-Guided Contrastive Learning for BERT Sentence Representations
- 两个bert构造正负例:①一个参数不参与优化的Bert,对所有层的transformer隐藏层做maxpooling,即(batch,len,768)->(batch,1,768),再取均值作为句子的输出表征;②一个参数优化的bert,直接用最后一层[CLS]作为句子表征;来自同一句话的①②表征构成正例,不同句子的①②表征作为负例。
3. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
- 搞了四种数据增强构造正例:①token_embedding随机加一些噪声;②token_embedding索引变换;③随机让token_embedding的一些token失活(整行置0)④整个token_embedding随机失活。
4. DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
- 同一篇文章两个句子是正例,不同文章两个句子是负例。
5. Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
- 同一类别的句子都放到一个词袋里面,从这个类别词袋里面挑些不重要的词对这个句子做插入/替换作为正例,其它类别词袋全体作为这句话负例。
6. SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
- 第一阶段直接生成文档,第二阶段用对比学习:拉近所有生成文档和原文距离,并且希望第二阶段的Loss能让所有候选文档按照第一阶段打的分进行排序;
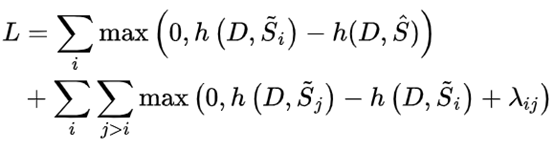
D是原文档,s_hat是标签,h是打分函数,具体操作就是拿标签和生成文档的[cls]计算相似度,si···sj都是生成文档,按得分依次降低排序,所以sj分数一定小于si,按照上面的loss最小化的话,i到j的排序也必须是从大大小,希望模型在没有参考文档的情况下为候选文档进行排序。
7. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
- 两个损失,①类别交叉熵损失预测句子类别;②对比学习损失——正例对来自同一个类别的数据 负例是不同类别的数据。
8. Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
- 同样一句话翻译成不同语言虽然表示不同,但是在人的意识里面实际的语义应该是相似的——用多语种来构建正负例。
补充前置知识:
SimCSE:本质上来说就是(自己,自己)作为正例、(自己,别人)作为负例来训练对比学习模型;(同一句话过两次encoder,经历过两次不同的随机dropout的输出作为正例)
损失函数:

其中:
① 因为是无监督,所以y_true为输入为None,代码块内的y_true是下面③人为构造的;
② 每个batch内,每一句话都重复了一次。句子a,b,c。编成一个batch就是:[a,a,b,b,c,c];
③ 若idxs_1是[[0,1,2,3,4,5]],则idxs_2是[[1],[0],[3],[2],[5],[4]],人为构造的y_true就是:

y_pred = K.l2_normalize(y_pred, axis=1)
# L2正则,降低奇异值影响
similarities = K.dot(y_pred, K.transpose(y_pred))
# batch内每句话和其他句子的内积相似度
similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12
# 自身的相似度置0
similarities = similarities * 20
# 将所有相似度乘以20,只是单纯扩大loss范围
loss = K.categorical_crossentropy(y_true, similarities, from_logits=True)
# 优化目标,普通的六分类问题
SimCSE有监督的话,正例是(正样本两次drop),负例包括:①(正样本drop,其它正样本drop)②(正样本drop,负样本drop)
**R-Drop:**用KL散度来计算两次drop值,期待不同drop输出的结果趋向于完全一致。
技术交流群邀请函
已建立CV/NLP/推荐系统/多模态/内推求职等交流群!想要进交流群学习的同学,可以直接扫下方二维码进群。
加的时候备注一下:昵称+学校/公司。群里聚集了很多学术界和工业界大佬,欢迎一起交流算法心得,日常还可以唠嗑~

往期精彩回顾
[

Google提出用对比学习解决推荐系统长尾问题
](http://mp.weixin.qq.com/s?__biz=Mzg3NzY2ODIzOA==&mid=2247512388&idx=1&sn=cba24383ddd1e4b04e12430a3328bbcc&chksm=cf1d83a5f86a0ab37283c25d007dd475f4a9c5a28fe8c1b951b7fcac191480376a6baa99409e&scene=21#wechat_redirect)
[

北京户口到手,日子却越发窘迫…
](http://mp.weixin.qq.com/s?__biz=Mzg3NzY2ODIzOA==&mid=2247512263&idx=1&sn=0a6e1c89393365c331217b3e1b3d137c&chksm=cf1d8226f86a0b30ddb40a44f6c840f8adcad191e9b465399c4d11c91cfe6c279bb7b93acff0&scene=21#wechat_redirect)
[

业界总结 | BERT的花式玩法
](http://mp.weixin.qq.com/s?__biz=Mzg3NzY2ODIzOA==&mid=2247512141&idx=1&sn=d2ffb0d712ab1a2c52a9989cf77723d4&chksm=cf1d82acf86a0bbae568ec764bbda503a9ac1b16bb2ed3ab3bdba04833aa2854c6ffac6734f9&scene=21#wechat_redirect)
关于我
你好,我是对白,清华计算机硕士毕业,现大厂算法工程师,拿过8家大厂算法岗SSP offer(含特殊计划),薪资40+W-80+W不等。
高中荣获全国数学和化学竞赛二等奖。
本科独立创业五年,两家公司创始人,拿过三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研清华后退居股东。
我每周至少更新三篇原创,分享人工智能前沿算法、创业心得和人生感悟。我正在努力实现人生中的第二个小目标,上方关注后可以加我微信交流。
期待你的关注,我们一起悄悄拔尖,惊艳所有



















 3728
3728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











