







什么是ES?
Elasticsearch是一个分布式文档存储。Elasticsearch不会将信息存储为列数据的行,而是存储已序列化为JSON文档的复杂数据结构。当集群中有多个Elasticsearch节点时,存储的文档将分布在集群中,并且可以从任何节点立即访问。存储文档时,将在1秒钟内几乎实时地对其进行索引和完全搜索。Elasticsearch使用称为倒排索引的数据结构,该结构支持非常快速的全文本搜索。
特点:
1.分布式文档存储,数据都是序列化的JSON
2.近乎实时的对数据建立索引和全文搜素
3.支持类JSON的DSL查询语句
4.集群部署。集群中节点的添加和删除,对自动对分片进行分配,平衡集群。
5.使用倒排索引,可以快速的对全文进行检索。
什么是倒排索引?
文档会进行分词,建立从词语到文档的映射。当我们检索词语时可以快速的找到对应的文档。
分片是什么?
存储的数据,潜在的情况下可能会超过单个节点的硬件的存储限制,为了解决这个问题,elasticsearch便提供了分片的功能,它可以将索引划分为多个分片,每一个分片本身是一个全功能的完全独立的索引。
分片是ES中的最小存储单元。分片分为主分片和副分片,主分片用于修改类操作,副分片主查询。
文档路由到分片的过程?
文档被索引时,会根据文档的ID,使用一个简单的公式,来决定路由到哪个主分片中。
=Hash(id)/主分片数目。正因为基于这个公式,所以主分片数目在确定之后不可更改,副分片数目可以进行更改。
文档的写入过程
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- 协调节点,对document进行路由,将请求转发给主分片所在的node
- node上的主分片处理请求,然后将数据同步到副分片
- 协调节点,如果发现主分片和所有的副分片都搞定之后,就会返回请求到客户端
文档的读取过程?
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- 协调节点,对document进行路由,将请求转发给主分片所在的node,此时会使用round-robin随机轮训算法,在主分片以及所有的副分片中随机选择一个,让读请求负载均衡,
- 接受请求的node,返回document给协调节点
- 协调节点将内容返回给客户端
索引ES底层实现
ElasticSearch 写入文档过程
ElasticSearch 基于Lucene.。Lucene里面就核心的是Segment,Segment是一个数据集概念,每个Segment是一个倒排索引。
ElasticSearch 的Index 是由多个Segment和Commit point提交点组成。
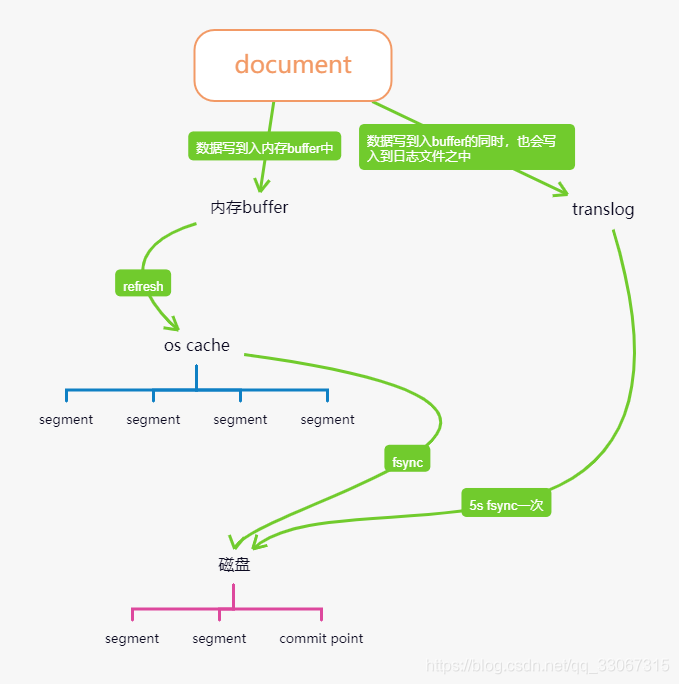
以下是ES写入顺序:
1.文档首先会写到内存之中,同时写入到translog。
2.每隔1s(默认)会进行一个refresh操作,将内存数据写入到os cache中,生成一个segment,此时数据可以被检索到。从请求到可以被搜索,用时1s中,所以ES被称之为准实时。
3.每隔30分钟,或者translog文件太大,都会执行flush操作,将cache中的数据持久化到磁盘,并记录一个commit point。
4.translog中的数据,会每隔5s,持久化磁盘之中。
ES 更改或者删除:
document 有删除时,会在生成commit point时候,生成一个.del文件。更新时,除了生成.del文件,还会有新的segment生成。查询时,会通过.del进行过滤查询。
此为逻辑删除 。
ES segment 合并:
在 ES 后台会有一个线程进行 segment 合并
1.合并进程选择一小部分大小相似的 segment,并且在后台将它们合并到更大的 segment 中,此合并进程,并不会中断索引和搜索。
2.新的 segment 被刷新(flush)到了磁盘,同时生成一个新的commit point(记录了新的segment和要被排除的segment是哪些)
3.老的 segment 被删除。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









