






为什么需要内网穿透功能?
我们在公司本地搭建了自己公司的内部系统,但是由于公司组网的方式特殊,无法实现所有人都能通过内网ip访问到项目,
又不能上线到云,于是就需要这个内网穿透功能,把这个本地主机给予公网访问的权限。
frp是什么?
简单地说,frp就是一个反向代理软件,它体积轻量但功能很强大,可以使处于内网或防火墙后的设备对外界提供服务,它支持HTTP、TCP、UDP等众多协议。
准备工作
- frp软件(这里用的是开源产品:github 选择frp_0.33.0_linux_arm64.tar.gz 和 frp_0.33.0_windows_amd64.zip)
- 一台服务器(演示型号为:centOS7)
- 运行有web项目的设备(windows或者linux,本次以自己的笔记本来演示,所以是windows)
服务器安装
上传到压缩包到服务器后,解压:
tar -zxfv frp_0.33.0_linux_arm64.tar.gz进入到解压目录, 然后配置 frps.ini 文件:
cd /home/frp_0.33.0_linux_arm64.tar.gz
vim frps.ini修改为如下配置
[common]
bind_port = 7000
dashboard_port = 7500
token = 12345678
dashboard_user = admin
dashboard_pwd = admin
vhost_http_port = 10080
vhost_https_port = 10443- “bind_port”表示用于客户端和服务端连接的端口,这个端口号我们之后在配置客户端的时候要用到。
- “dashboard_port”是服务端仪表板的端口,若使用7500端口,在配置完成服务启动后可以通过浏览器访问 x.x.x.x:7500 (其中x.x.x.x为VPS的IP)查看frp服务运行信息。
- “token”是用于客户端和服务端连接的口令,请自行设置并记录,稍后会用到。
- “dashboard_user”和“dashboard_pwd”表示打开仪表板页面登录的用户名和密码,自行设置即可。
- “vhost_http_port”和“vhost_https_port”用于反向代理HTTP主机时使用,本文不涉及HTTP协议,因而照抄或者删除这两条均可。
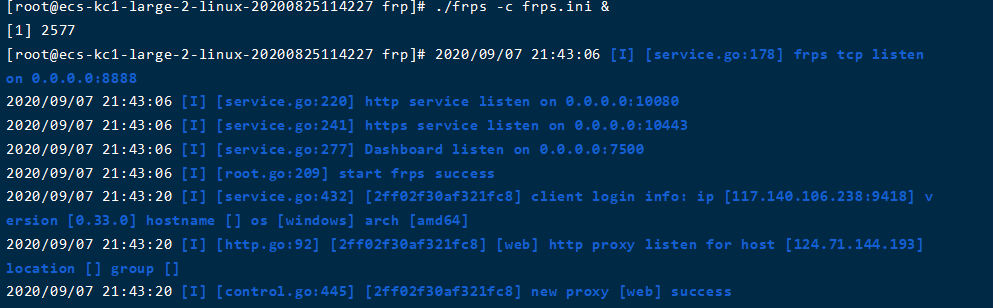
保存退出后,运行frps服务器端:
./frps -c frps.ini运行成功如图:
使用ip地址加端口,输入设置好的用户名密码,即可看到仪表盘面板:http://x.x.x.x:7500/
客户端配置(windows演示)
windows解压,就不说了。
解压完成后,配置frpc.ini:
[common]
server_addr = 服务器ip
token = 12345678
server_port = 8888
[web]
type = http
local_port = 8080
custom_domains = 服务器ip- “server_addr”为服务端IP地址,填入即可。
- “server_port”为服务器端口,填入你设置的端口号即可,如果未改变就是7000
- “token”是你在服务器上设置的连接口令,原样填入即可。
windows的 frpc 运行!
进入powershell:
windows快捷键: windows+x 按 a 进入powershell
执行:
./frpc -c frpc.ini成功如图:

访问
使用 ip加端口(http://服务器ip:10080)访问
如图:
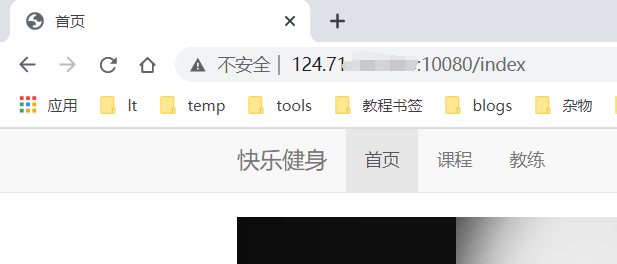
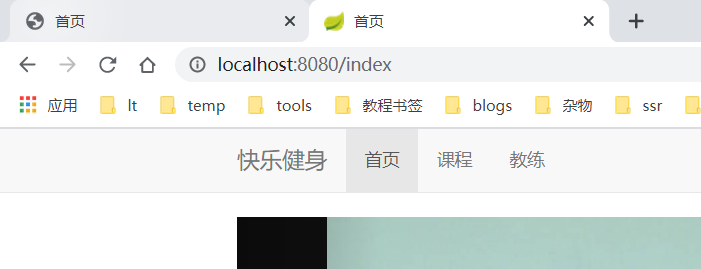
访问到我本机正在运行的springboot端口为8080的项目,则成功。
ps:务必确保一下三点
- 可以ping通公网ip
- 服务端已经开启 (jobs命令可以查看正在运行的任务)
- 服务端端口已经开放(防火墙)
firewall-cmd --state 查看防火墙状态
systemctl stop firewalld 关闭防火墙(centOS 7)
END


















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











