







 本文深入探讨了性能测试的过程,包括负载测试、基准测试和并发用户数的概念。通过线程、进程和协程模拟并发用户,使用工具如JMeter、LoadRunner等进行测试。性能指标关注响应时间、TPS、QPS、HPS等,并通过压力性能曲线分析最佳并发用户数。此外,还讨论了资源利用率和吞吐量,强调了性能优化的重要性。
本文深入探讨了性能测试的过程,包括负载测试、基准测试和并发用户数的概念。通过线程、进程和协程模拟并发用户,使用工具如JMeter、LoadRunner等进行测试。性能指标关注响应时间、TPS、QPS、HPS等,并通过压力性能曲线分析最佳并发用户数。此外,还讨论了资源利用率和吞吐量,强调了性能优化的重要性。
- 【压测】
- 就是要我们先做负载测试,得到接口的最大可接受并发用户数
- 然后再用这个并发用户数,进行性能测试,得到性能指标数据,输出性能报告
- 性能测试:开始时,先做单接口的性能测试,然后再做多接口合并为业务的性能测试;
- 【基准测试】
- 基准:以前没有,现在要你得到第一版性能指标数据。然后后续版本时,就可以与这个数据进行比较,得到性能是否优化的结论。
- 【并发用户数】VS【线程数】
- 性能测试中 并发用户是原始驱动力,并发用户模拟我们真实的用户
- 性能测试是要用多用户并发的,单用户的测试,不是我们的性能测试
- 并发用户数:
- 性能测试工具,工具不一样,来模拟产生并发用户的方式是不一样的
- 造出这些并发用户的方式常见的有三种
- 线程:用线程来造人,并发用户数=线程数
- 进程:用进程来造人,并发用户数=进程数
- 协程:用协程来造人,并发用户数=携程数
- 性能测试工具
- jmeter:用线程来造人
- loadruner:可以用线程,也可以用进程
- ngrinder:用【进程*线程】的方式造人,=>并发用户数量=进程数*线程数
- locust:用协程造人
- 造出这些并发用户的方式常见的有三种
- 性能测试工具,工具不一样,来模拟产生并发用户的方式是不一样的
- 性能测试中 并发用户是原始驱动力,并发用户模拟我们真实的用户
-
#性能指标
- 【并发】VS【并行】
- 【并发用户数】VS 【在线用户数】VS【系统用户数】
- 并发用户数:一定是有并发请求的用户
- 在线用户:只要在访问系统,可以不用请求
- 行业经验:在线用户数的5%~10%当做并发用户数
- 系统用户:访问了系统,登录系统,在系统中留下了访问记录的人,都会被定义为系统用户
- 【响应时间:RT】&【平均响应时间AvgRT or aRT】
- 一个请求从发起点开始,经过网络传输,到达服务器。在服务器内容部处理,通过网络传输返回给发起方之间的时间差就是响应时间。
- 发起方-----网络传输-----服务器1-----服务器2----服务器3-----网络传输-----发起方
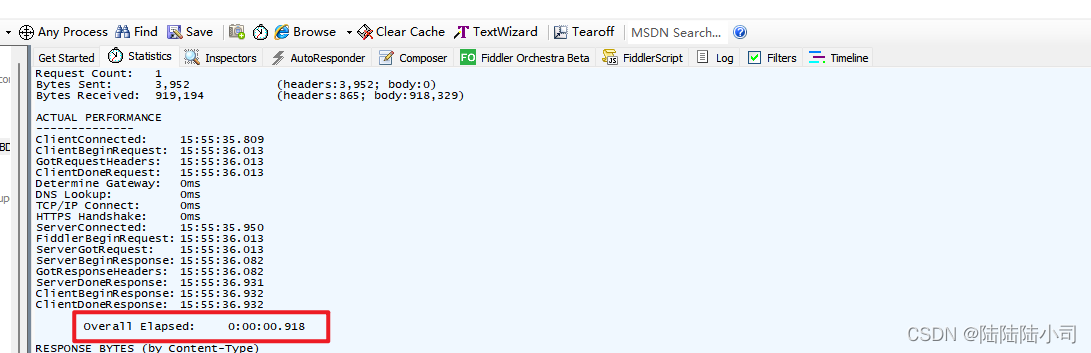
- 如何缩短响应时间
- 高带宽
- 尽可能使用有线网络
- 网络越简单越好---推荐使用局域网------性能测试时最好用独立网络
- 提高服务器的性能: 服务器性能 == 硬件 & os(操作系统) & 项目----综合调优(性能测试人员的价值)
- 行业标准:http/https协议,接口平均响应时间<=1.5s
- 平均响应时间:
- 50%响应时间,平均响应时间并不能完全显现性能的真实情况(就像你和马爸爸的平均财富)
- 90%响应时间 :总请求次数中,90%的响应时间是<=该时间的,更能反应真实的性能情况
- TPS & QPS & RPS & HPS
- 【TPS】“服务器”每秒能处理的事务数
- 是服务器能力的综合体现,是性能测试中最重要的指标(越大越好)
- 事务
- 一个事务,就是一个会话,
- 假如1个用户在1s时间内完成1笔事务,那么TPS=1;
- 一个事务,可以是多个完全的请求和响应
- 如果某笔业务的响应时间是1ms,那么每秒处理的事务所为1000,也就是说TPS=1000;
- 如果1个用户在1s只能完成1笔事务,要想达到TPS=1000,那么并发用户量就需1要是1000
-
不难得出这样的公式:
设并发数为c,响应时间为t(ms),那么TPS=(1000/t)*c
从公式可以看出,要想提高系统的TPS,有两种方式:增加并发量或者降低响应时间。
-
降低响应时间只能通过优化代码的方式实现。
-
提高并发用户数c,而并发用户数通常又和服务器程序的请求处理模型关系密切,如果一个线程处理一个请求,最大并发用户数则取决于服务器能处理的最大线程数;同理,如果是一个进程对应一个请求,那么最大的并发用户数取决于最大进程数。需要说明的是,随着并发用户数的增加,响应时间往往也会随之增大。因此,最大并发用户数要从实际得出才有意义
-
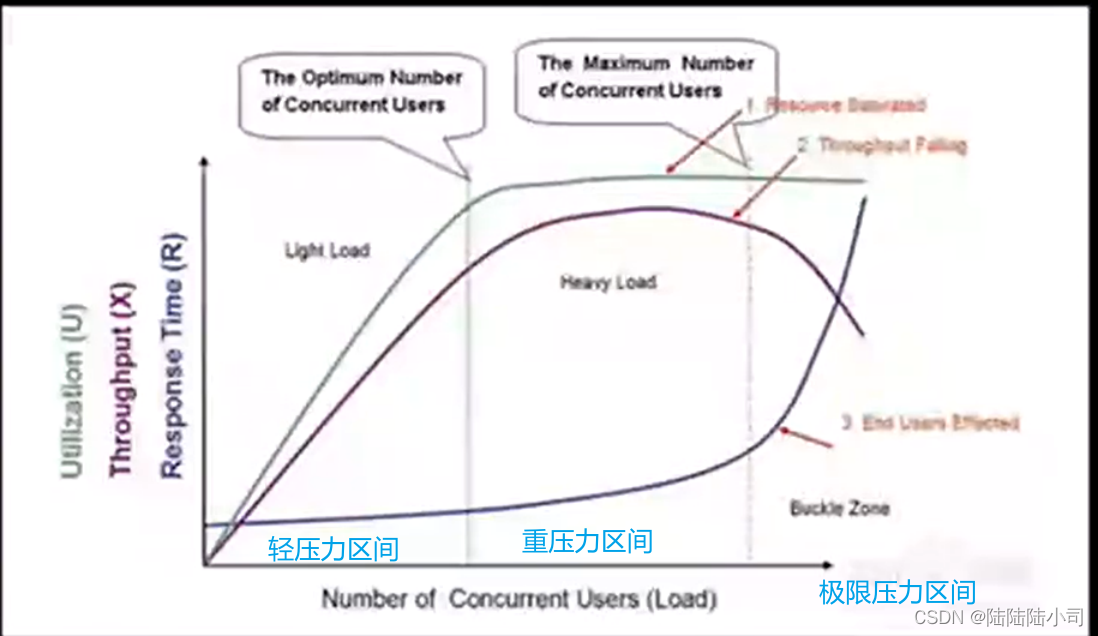
压力性能曲线分析图
X轴:并发用户
Y坐标:响应时间(respomse time),吞吐量(throughput),资源利用率(utilization)
- 先看响应时间:在轻压力区(Light Load),响应时间变化不大,曲线比较平稳;进入重压力区(Heavy Load )后,响应时间呈现上升趋势;而进入拐点区(极限压力区间Buckle Zone)后,响应时间增长率增大,响应时间急剧增加。
- 再看吞吐量:随着并发用户数的增加,吞吐量增加;进入重压力区后吞吐量逐步平稳,到达拐点后吞吐量急剧下降,说明系统已经到了处理极限,
- 再看资源利用率:随着并发数的增加,资源利用率逐步上升,到达拐点后,利用率急剧下降。
- 综合来看,随着并发数的增加,资源利用率和吞吐量在增加,说明系统正在积极的处理事务,此时,系统能够承受这些请求量,因此,响应时间是趋于平稳的。但是随着并发数的持续增加,压力逐步增大,吞吐量和利用率达到饱和。随后,吞吐量急剧下降,响应时间急剧上升,说明此时系统已经处于崩溃边缘了
-
The Optimum Number of Concurrent Users(最佳并发用户数):在Light Load和Heavy Load两个区域交界处的并发用户数;
-
The Maximum Number of Concurrent Users(最大并发用户数):在Heavy Load和Buckle Zone两个区域交界处的并发用户数;
- 一个事务,就是一个会话,
- 【QPS】“服务器”每秒查询率
- 查询:1.数据库查询,2.服务器资源申请(http/https请求,dubbo请求……)
- 一个事务请求,可能需要N多次查询
- TPS:QPS = 1:N ,
- 服务器的监控中显示的是QPS
- 性能测试看到的是TPS
-
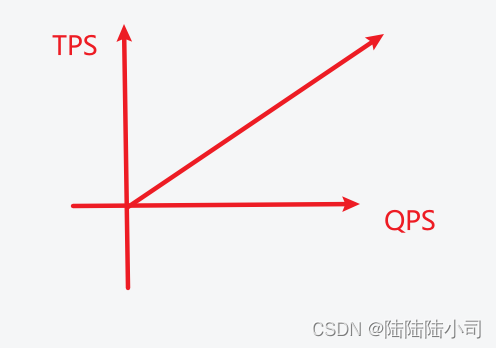
这里要说明一下QPS和TPS的区别:
-
QPS一般是指一台服务器每秒能够响应的查询次数,或者抽象理解成每秒能应对多少网络流量
-
TPS是指一个完整事务,一个事务可能包含一系列的请求过程。举个🌰,访问一个网页,这是一个TPS,但是访问一个网页可能会对多个服务器发起多次请求,包括文本、js、图片等,这些请求会当做多次QPS计算在内,因为它们都是流量
-
- 【HPS】HitPerSecond 每秒点击率
- 点击:这个点击发生在客户端(用户端)
- 点击一次,至少发生一次接口请求 也是1:N的关系
- 在web性能测试中,我们会把HPS当做TPS(但是我们要明白HPS是用户端的数据,TPS是服务端的数据)
- 对服务器端进行性能测试是,没有HPS这个概念
- 【RPS】RequestPerSecond:每秒请求率
- 请求也是用户端的指标
- 由界面发起请求,也可以是工服工具发起的请求
- 在用工具测试的时候,也会认为RPS = TPS
- 吞吐量 & 吞吐率
- 【吞吐量】:每秒钟“网络”传输多少事务
- 网络没有瓶颈的时候 吞吐量 = TPS
- 网络有瓶颈的时候,吞吐量!=服务器TPS数值,因为此时网络阻塞,事务传递不到服务器,服务器处理结果返回不到发起方,这个时候不能用吞吐量来等价TPS
- 【吞吐率】:每秒网络中传输的字节数 KB/S != Kb/s B=8b
- 带宽的单位 Mbps 1Mbps = 125KB/s
- 【吞吐量】:每秒钟“网络”传输多少事务
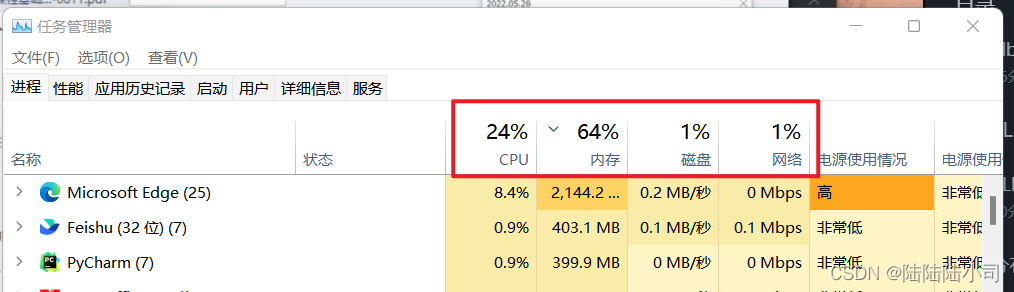
- 【资源利用率】 服务器各种软硬件资源的使用率
- CPU的使用率、内存使用率,磁盘使用率,IP使用率
- 行业中一般吧这些使用率的标准线划定为 80%
- 对于CPU来说,因为我们大多数都是多核CPU,这个cpu使用率,一般来说是所有核一起总的CPU使用率。增加CPU的数量,是有可能降低CPU的总使用率
- 性能测试指标使我们性能测试的时候,需要输出的东西,怎么输出呢
- 需要有监控
- 监控可以收集这些数据,用于性能分析
- 企业要开展性能测试,要具备什么条件
- 1.独立网络(有线网络,局域网)
- 独立服务器(硬件配置要与生产一致,服务器部署架构要生成一致,集群大小,可以缩略)
- 如果生产和测试的硬件配置不一致,则做完之后的性能指标完全没有意义
- 但是如果发现了性能的问题,进行性能分析调优,这个是可以通用的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









