







 本文详细介绍了如何通过解压安装包、配置环境变量、复制模板文件、远程拷贝安装目录到集群节点,以及使用特定命令启动Spark集群的过程。
本文详细介绍了如何通过解压安装包、配置环境变量、复制模板文件、远程拷贝安装目录到集群节点,以及使用特定命令启动Spark集群的过程。
- 解压安装包
tar -xvf spark-2.0.1-bin-hadoop2.7.tgz
- 在spark的conf目录下,复制
spark-env.sh.template为spark-env.sh
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
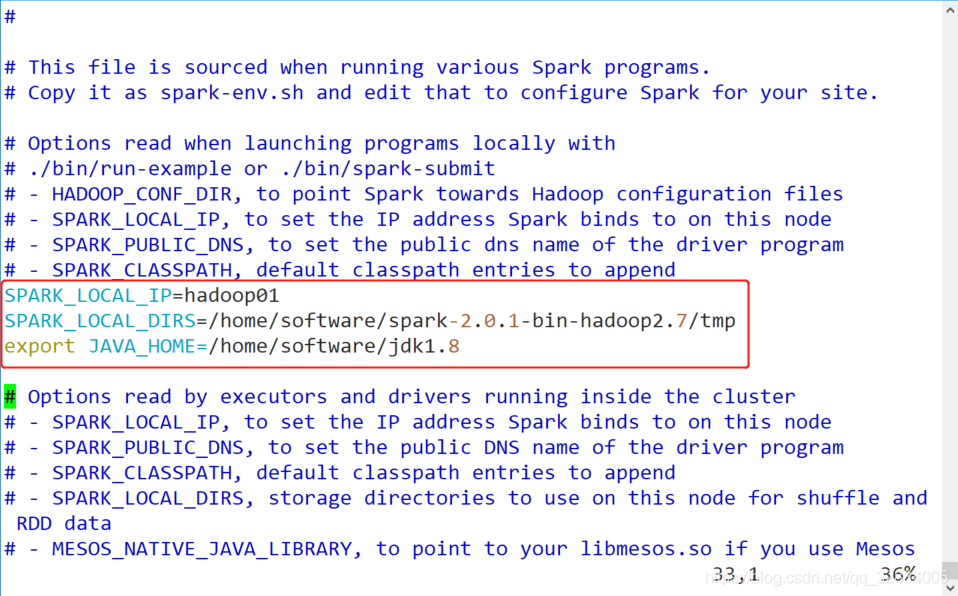
- 在spark的conf目录下,复制
slaves.template为slaves
cp slaves.template slaves
vim slaves
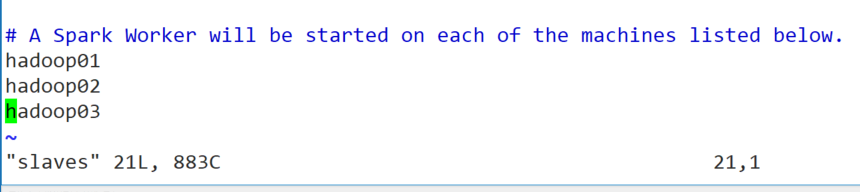
- 将spark安装目录远程拷贝到另外两个节点
scp -r spark-2.0.1-bin-hadoop2.7 hadoop02:/home/software/
scp -r spark-2.0.1-bin-hadoop2.7 hadoop03:/home/software/
启动spark集群
- 进入spark的sbin目录,启动spark集群
sh start-all.sh
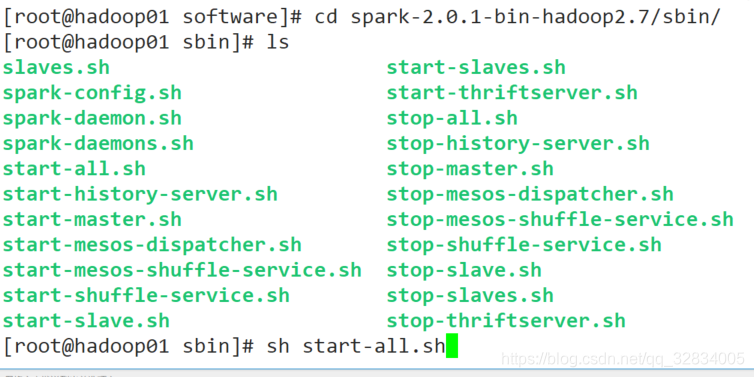
- 在spark的bin目录下,进入spark客户端
sh spark-shell --master spark://hadoop01:7077
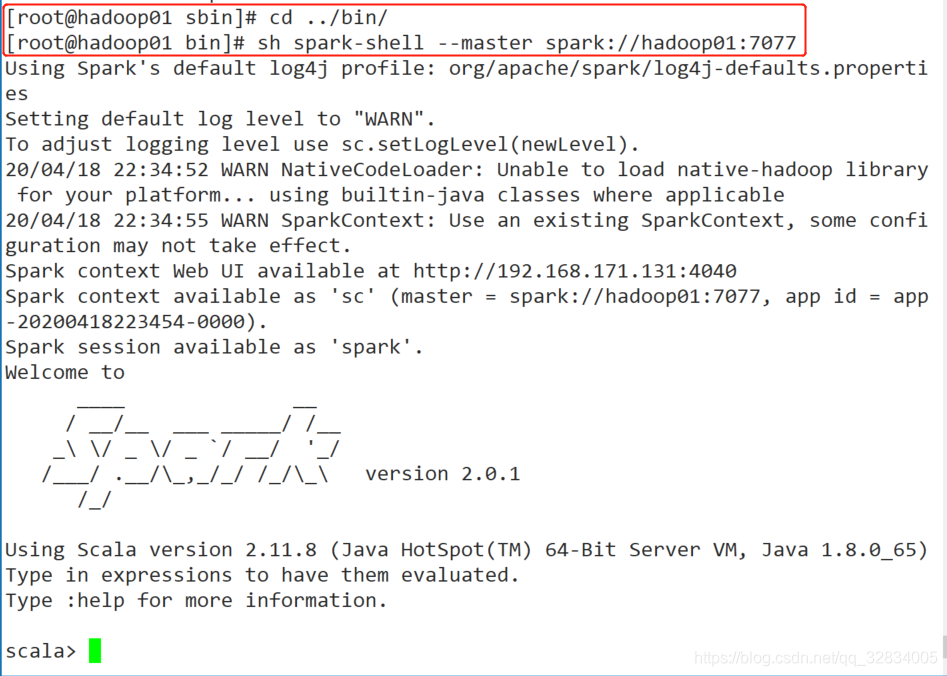

















 5022
5022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









