









 本文深入探讨了平衡二叉搜索树(BBST)的各种类型,包括AVL树、伸展树、B树及红黑树的原理与实现。通过Java代码示例,详细讲解了这些数据结构的创建、插入、查找和删除操作,以及如何保持树的平衡。
本文深入探讨了平衡二叉搜索树(BBST)的各种类型,包括AVL树、伸展树、B树及红黑树的原理与实现。通过Java代码示例,详细讲解了这些数据结构的创建、插入、查找和删除操作,以及如何保持树的平衡。
邓俊辉老师的数据结构课讲的很好,大多数数据结构都讲的十分清晰透彻,其中BBST就是第七章到第八章的内容,BBST在计算机科学中是十分重要的数据结构,使用在各个领域。然而由于它的变种多种多样,实现复杂,使人望而生怯。在邓老师的课中,就很清楚明白的讲了BBST的应用,特性,以及其变化的目的。并且举出了常见的四种BBST,分别是AVL树,伸展树,B-树以及红黑树。
本博客记录我使用Java理解这四种BBST的过程与经验,若由不得当之处,希望有人指出。
一、二叉树以及其节点
在编写BBST之前,我打算先从写BT和BST作为父类。BT也就是Binary Tree,该结构的特征是:该结构由树节点组成,每个节点最少包含数据域,和左右子链域。左右子链分别连接另外的树节点或者空。最顶部的节点叫做根节点。
所以很清楚,该类需要一个"树节点"的类:
先分析一下该类的数据域还可能需要什么,以及应该提供些什么样的方法。以及该类应该拥有什么样的性质:
- 首先该类作为树的伴生类,所以完全可以作为树的静态内部类。当然,独立作为一个类是可以的。
- 作为二叉树节点,最基础的便是要有左右节点链,以及数据。
- 考虑到后期需要作为BBST的树节点,所以需要提供父亲指针以及高度等信息。
- 考虑到每个节点可以作为一个子树,所以对节点进行操作的方法都可以放在树节点类中。
所以暂定初步形态如下:
public class BinNode<E>{
BinNode<E> left;
BinNode<E> right;
BinNode<E> parent;
E data;
int height;
BinNode();
BinNode(E data);
BinNode(E data,BinNode<E> parent);
int size();
int getHeight()
BinNode<E> insertAsLC(final E data)
BinNode<E> insertAsRC(final E data)
boolean isRchild()
boolean isLchild()
BinNode<E> tallerChild()
boolean isLefa()
private BinNode<E> maxNode(BinNode<E> r)
private BinNode<E> minNode(BinNode<E> r)
public String toString()
}
二、二叉查找树(BST):
作为一个最基本的二叉查找树,树中的每一个节点都符合左孩子权值 < 本身权值 < 右孩子权值的条件,所以它的查找效率是O(log(h))的。它的插入效率也需要查找该节点的位置,找到后直接插入。所以效率也是O(log(h))的。删除也需要查找找到目标节点,然后改变局部节点的连接状态,效率也可以算是O(log(h))的。这里再以图形化的方式,展示查找/插入/删除操作的实现:
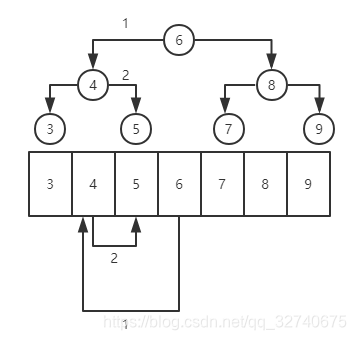
上图是对一颗二叉查找树中的节点 5 的查找过程。可以看出,对于一颗二叉查找树的查找,可类比为有序序列的二分查找,效率挺高,实现也容易。仅需要通过比较后成功或转入子链。
这里给出递归的实现方式:
public BinNode<E> search(final E data){
_hot = null; // _hot变量用于之后的插入和删除
return searchIn(root, data);
}
private BinNode<E> searchIn(BinNode<E> v,E e){
if(v == null || e.equals(v.data))
return v;
_hot = v;
return searchIn((e.compareTo(v.data) < 0 ? v.left:v.right), e);
}
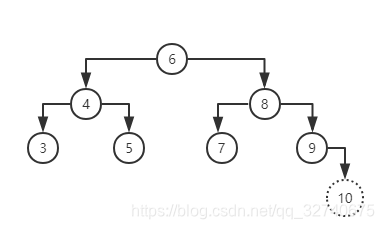
上图是在二叉查找树中对节点 10 的插入过程。对于插入节点的方式同样需要查找来找到插入元素所应在的位置。先调用查找方法,查找节点10。查找方法必然会停止于节点9的原右孩子,也就是空节点。它会返回空,并且把_hot设置为9。通过比较可以知道应该将10插入到9的右孩子处。当然,这只是实现的一种,达成了代码的复用罢了。以下是具体实现:
public BinNode<E> add(final E data){
// 查找插入节点
BinNode<E> f = search(data);
//如果没有找到该节点,且该树有根
if(f == null && f!=root){
if(_hot.data.compareTo(data) > 0)
f = _hot.insertAsLC(data);
else
f = _hot.insertAsRC(data);
updateHeightAbove(f); //更新f以及其父亲的高度hight
size++;
//如果没有找到该节点,且该树无根
}else if( f==null && f==root){
f = root = new BinNode<E>(data, null);
size++;
}
//返回插入的节点或者null
return f;
}
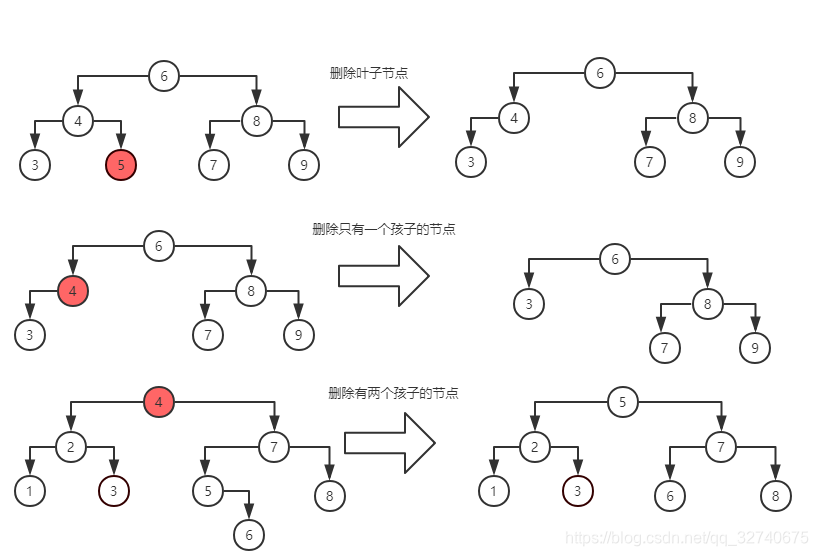
上图演示了二叉查找树的删除过程,对于删除一个节点,因为需要考虑局部节点的结构变化引起二叉查找树的破坏,所以为了保证查找树的结构,删除节点时需要根据是否有左右子树来进行分支操作:
- 删除的节点没有孩子: 直接摘除
- 删除的节点有且只有一个孩子:将左/右孩子替代该节点
- 删除的节点有两个孩子:将该节点与其中序序列下的直接后继相交换,使其变成以上已有的两种状态再进行摘除或替换。
前两种是非常直观且很容易实现的,第三种情况复杂一点点,只要不忘初心,删除后的调整是为了保持树的中序有序性,多列举几次情况三,就能发现:同时拥有两个孩子的情况不过三种情形。代码如下:
public boolean remove(final E data){
BinNode<E> f = search(data);
if(f == null)
return false;
removeAt(f);
size--;
updateHeightAbove(_hot);
return true;
}
private BinNode<E> removeAt(BinNode<E> x){
BinNode<E> w = x;
BinNode<E> succ = null;
if(x.left == null) //删除节点没有左孩子
succ = x.right;
else if(x.right == null) //删除节点没有右孩子
succ = x.left;
else{ //删除节点有左右孩子
w = w.succ();
x.data = w.data; //将需要删除节点的数据使用w覆盖,需要删除的节点变成 w
if(w.right == null){ //若需要删除的节点没有孩子 则直接摘除
if(w.isLchild())
w.parent.left = null;
else
w.parent.right = null;
}
else{ //有孩子则将孩子与父亲相连
if(w.parent == x)
w.parent.right = w.right;
else
w.parent.left = w.right;
}
}
_hot = w.parent; //被删除节点的父亲
if(succ != null){ //有孩子情况的替代
if(w.isLchild())
_hot.left = succ;
else if(w.isRchild())
_hot.right = succ;
succ.parent = _hot;
}
w.data = null; //摘除需要删除的节点
if(w.isLchild()){
w.parent.left = null;
}else if(w.isRchild()){
w.parent.right = null;
}
return succ; //返回替代删除节点的节点,没有则返回null
}
这样一来,拥有插入/查找/删除的最基本的二叉查找树就实现了,它拥有保持中序序列有序的性质。但是他也有一些缺点,那就是无法控制它的高度,在最坏情况下,他将会退化为链表。使效率下降为O(n)。只有在该树为真/满二叉树时才能高效率地使用该数据结构。所以,为了使其结构发生变化时能最好地控制其高度,二叉查找树的变种:AVL树,伸展树,B-树,红黑树等各显神通。
三、AVL树:
AVL树对比查找树多了个平衡因子的概念,平衡因子的定义是:
平衡因子 = 左孩子高度-右孩子高度
在保证该树为查找树的前提下,还需要额外保证每个节点的平衡因子的绝对值小于2,也就是说平衡因子的值域为[-1,1]。因为查找树只有在插入或删除时才会改变树结构,所以仅需要重载插入和删除方法,插入/删除后检查必要的节点并进行调整即可。
示例如下:
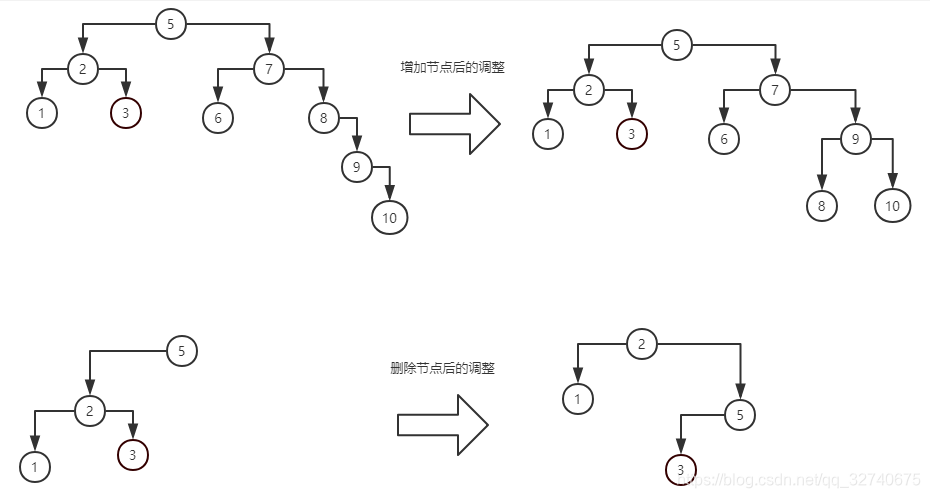
我们知道,对于同一个中序序列可以对应多个不同结构的二叉查找树,对于以上的结构调整也是如此,可以有多个不同的调整策略来调整树的高度。但实际上,查找树的高度调整并不复杂,无乎于左旋(zag),右旋(zig)两种操作方式。四种操作情况:zag,zig,zag-zig,zig-zag。图示如下:
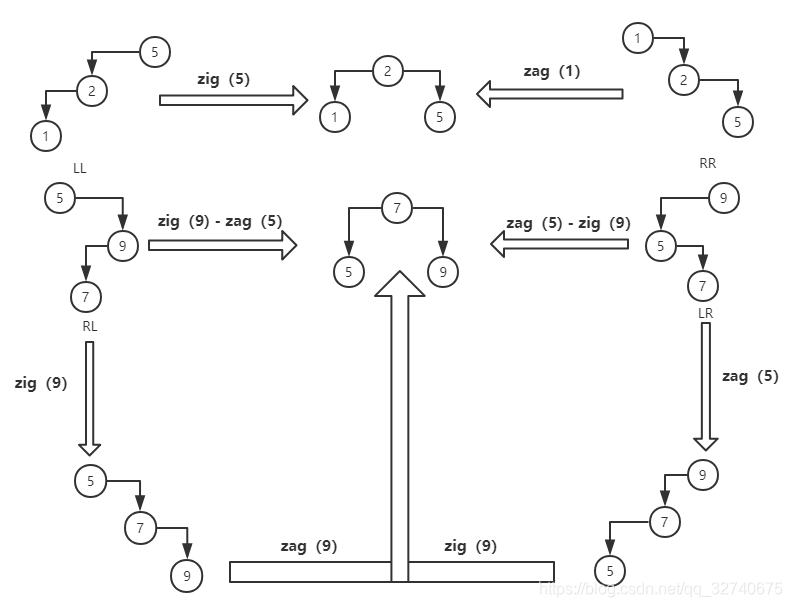
可以看出该图是十分对称的,所谓左旋/右旋,只不过是将某个节点和其孩子节点进行了类似旋转的操作,也就是父子的等价交换,进行等价交换后此树仍然保持查找树条件。上图分别演示了失衡时节点排列为:LL,RR,LR,RL 时四种情况都旋转操作。
如果觉得旋转操作绕口,操作比较复杂的话,请不要慌。还有3+4法可以进行等价且更加简单的重构。所谓3+4,指的是以大小排序为 T1,V,T2,P,T3,G,T4的局部子树进行操作的方法。如图:
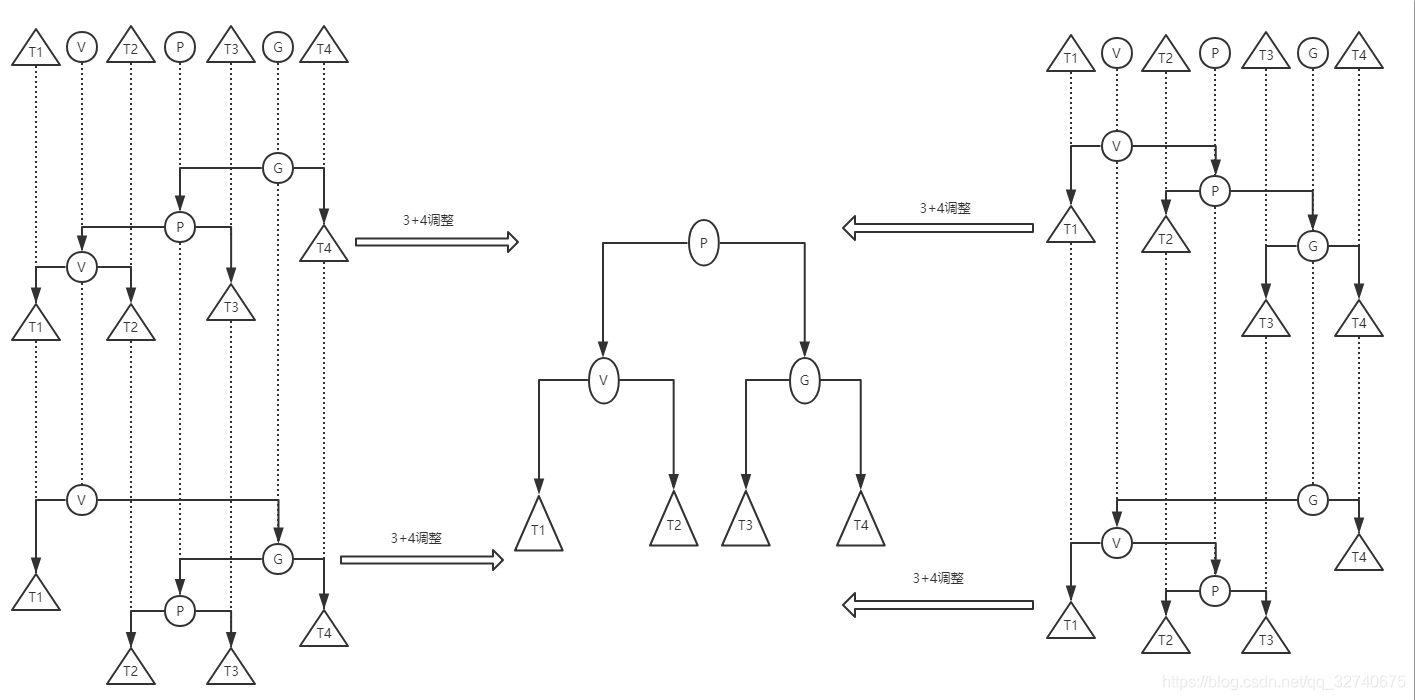
需要注意的是,这里的V,P,G是以LL结构为参考的,实际上他们并没有固定联系。这样一来,仅需要通过插入节点的父亲开始辨别局部结构,就可以传参给3+4调整方法进行统一调整了。
参考代码:
protected BinNode<E> rotateAt(BinNode<E> v){
BinNode<E> p = v.parent,g = p.parent; // 参考局部特征的节点
if(p.isLchild()) //zig
if(v.isLchild()){ //zig-zig
p.parent = g.parent;
return connect34(v, p, g, v.left, v.right, p.right, g.right);
}else{ // zig-zag
v.parent = g.parent;
return connect34(p, v, g, p.left, v.left, v.right, g.right);
}
else{ //zag
if(v.isRchild()){ // zag-zag
p.parent = g.parent;
return connect34(g, p, v, g.left, p.left, v.left, v.right);
}else{ // zag-zig
v.parent = g.parent;
return connect34(g, v, p, g.left, v.left, v.right, p.right);
}
}
}
protected BinNode<E> connect34(
BinNode<E> v,BinNode<E> p,BinNode<E> g,
BinNode<E> t1,BinNode<E> t2,BinNode<E> t3,BinNode<E> t4){
v.left = t1;
if(t1 != null) t1.parent = v;
v.right = t2;
if(t2 != null) t2.parent = v;
updateHeightAbove(v);
g.left = t3;
if(t3 != null) t3.parent = g;
g.right = t4;
if(t4 != null) t4.parent = g;
updateHeightAbove(g);
p.left = v;
v.parent = p;
p.right = g;
g.parent = p;
updateHeightAbove(p);
return p;
}
之前说过了在AVL树因为只有插入/删除才会改变树的结构,改变了结构就需要对必要的局部结构进行调整,使其符合查找树的特征。从上我们已经知道了等价变换调整的方法。所以,我们还需要知道在哪些情况需要调整,又需要调整哪些地方。
首先参考添加情况:
添加节点时,肯定只有在较深的子树下添加节点时才会发生失衡的情况。这时应该将失衡节点孙祖三代进行等价变换,使其保持平衡。需要注意的是,失衡节点是增加节点的祖上节点中的任意一个,所以需要向上遍历检查。进行等价变换的操作必定会使父节点高度减小。不难证明,添加节点发生失衡时,仅需要一次等价变换即可使整棵树重新回到平衡状态。
删除情况:
删除节点时,肯定只有在较浅的子树下删除节点才会发生失衡情况。这时同样需要对失衡节点孙祖三代进行等价变化,使其保持平衡。这里需要注意的一点是,失衡节点可能是删除节点的祖上节点上的任意一个。因为保持平衡并不会加深其高度,反而会减小其高度。所以做一次等价变换操作后仍需要向父亲节点检查是否平衡,直至空。
代码如下:
@Override
public BinNode<E> add(final E data){
BinNode<E> ret = super.add(data);
for(BinNode<E> r = ret.parent; r!=null; r = r.parent){
if(balaFactor(r))
updateHeight(r);
else{
if(r==root)
root = rotateAt(r.tallerChild().tallerChild());
else{
if(r.isLchild())
r.parent.left = rotateAt(r.tallerChild().tallerChild());
else if(r.isRchild())
r.parent.right = rotateAt(r.tallerChild().tallerChild());
}
updateHeight(r);
break;
}
}
return ret;
}
@Override
public boolean remove(final E data){
if(!super.remove(data))
return false;
for(BinNode<E> r = _hot; r!=null; r = r.parent){
if(balaFactor(r)){
updateHeight(r);
}else{
if(r==root)
root = rotateAt(r.tallerChild().tallerChild());
else{
if(r.isLchild())
r.parent.left = rotateAt(r.tallerChild().tallerChild());
else if(r.isRchild())
r.parent.right = rotateAt(r.tallerChild().tallerChild());
}
updateHeight(r);
}
}
return true;
}
AVL树的基本操作就到此为止了,总体上来说还是比较简单。在二叉平衡树的基础上仅需要增加少量代码便可实现平衡功能。
四、伸展树
伸展树也是一颗平衡树,它通过”伸展”来保证树的平衡。它的设计哲学是:80%的操作都只针对20%的数据。所以对于元素重复访问密集的场景,以及大部分访问都只针对少量数据的场景伸展树的效率是极高的。它没有引入任何诸如平衡因子的概念,也不需要检查节点的特殊状态。仅需要将上次访问的节点通过等价变换移到根节点即可。在之前我们已经尝试过了等价变换的技巧:左旋,右旋,3+4重构等。
因为查找会改变树的结构,所以伸展树的查找/添加/删除方法都需要进行重载。查找元素后,被查找的元素伸展至根,添加元素后,被添加的元素伸展至根,删除元素后,被删除元素的父节点伸展至根。所以,所谓的重载,也仅仅需要多实现一个“伸展”方法罢了。
但"伸展"的方法是需要研究的,不同的伸展策略会拥有不同的效率。以算法中常用的计量方式,使用大O来计量最坏的情况。对于一颗二叉查找树依次添加元素1,2,3,4,5,6,7,8。然后每次访问坏节点(最深的节点)来模拟伸展策略。
如果按照单层伸展策略,情况将会是:
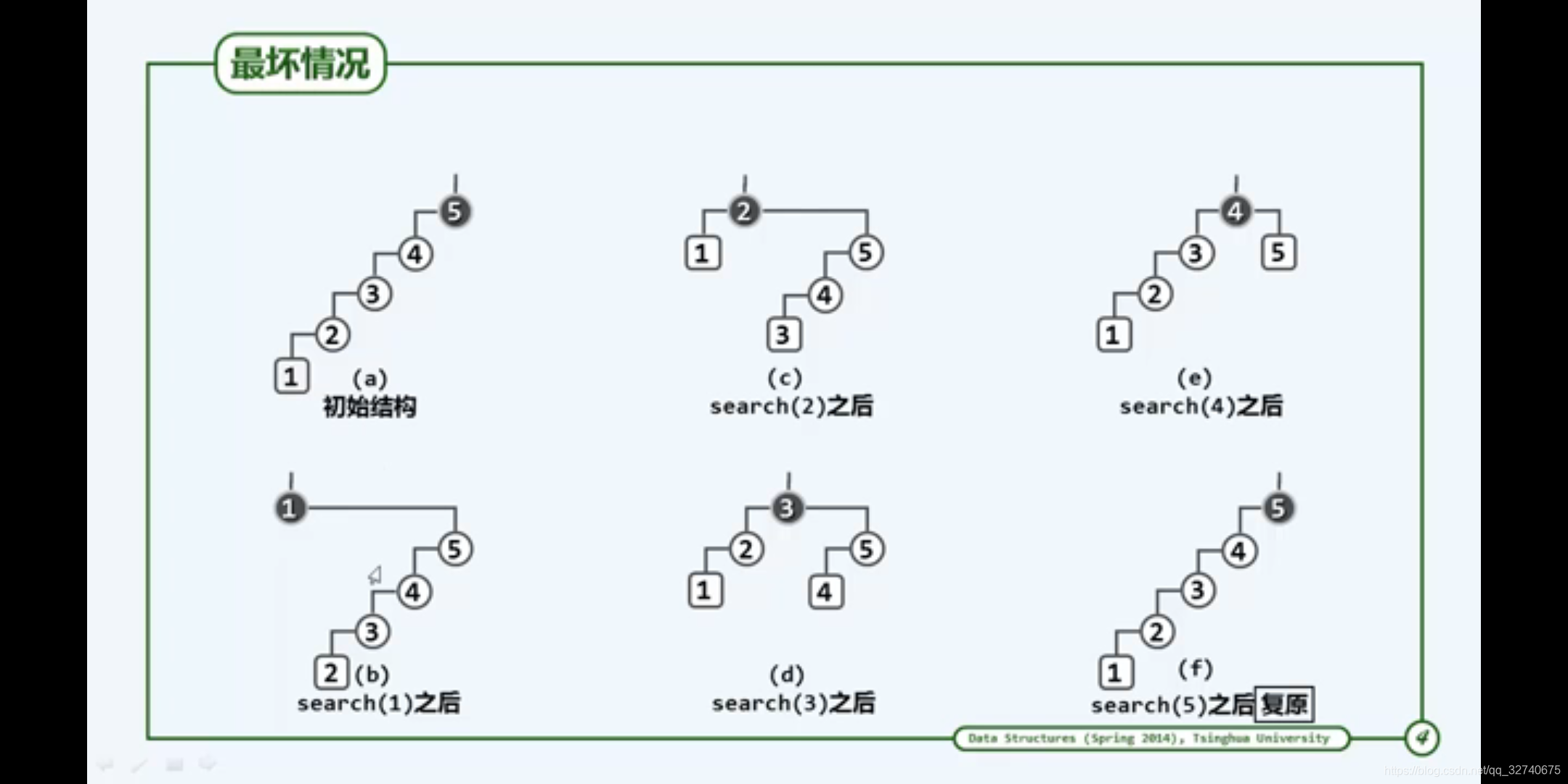
从该访问周期来看,访问节点1,2,3,4,5的访问成本分别为n,n-1,n-2…1。所以整个周期类,累积的访问成本应该为Ω(n²),分摊下来时间复杂度为Ω(n)。没有满足其期望。所幸的是双层伸展能解决这个问题,使单趟伸展操作分摊为O(logn)。效果表现在:每次访问坏节点,将会把对应路径长度进行折半。最坏情况不致持续发生。
双层伸展分为自底向上和自顶向下两种方式,自底向上方式为先按常规二叉查找树方式操作,然后使用等价变换将_hot(存在则是指向本身,不存在则指向父亲)节点移到root位置。有了该特性,增加和删除将变得非常简单。因为需要操作的节点经过伸展后都会变成头节点。
那么,双层伸展的魔力在那里呢?为什么它能产生路径折叠的效果呢?
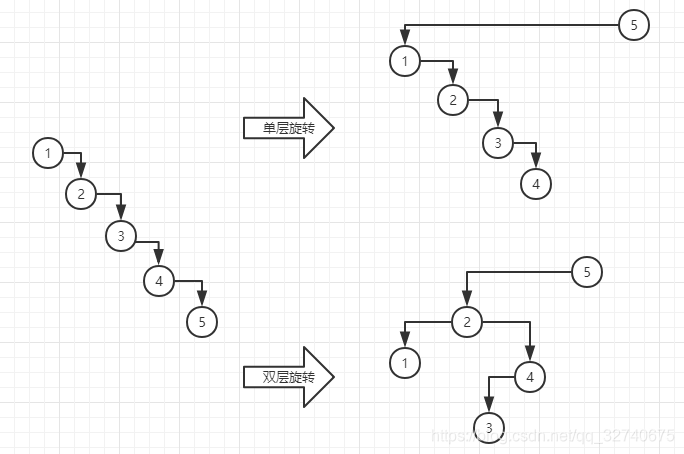
可以看出,双层伸展和单层伸展都是通过一步步等价变换使被访问节点移至根节点。但双层伸展在一字型情况时,通过先旋转被访问节点父亲再旋转被访问节点能改变局部拓扑结构。这种局部的细节的变化,将会引起整体的变化。最终将会达成这样一个效果。
那么自顶向下和自底向上又有什么区别呢?我想说,除了节省常数级时间以外,没什么特别大的区别。就像文法的自底向上和自顶向下解析一样,只不过是实现同一目标的两种途径罢了。自底向上的伸展过程之前已经描述过了。自顶向下则是从根节点开始比较,以及旋转。需要注意的是,因为需要双层旋转,所以需要比较两代节点和被访问节点的大小。然后决定具体的旋转过程。
以下是我的实现,可以作为参考:
public BinNode<E> search(final E data){
if(root == null)
return null;
boolean hasdata = true; //节点是否存在
BinNode<E> LRheader = new BinNode<>(data); //临时节点,作为左右树的头
BinNode<E> M = root; //中间树从root开始
BinNode<E> leftTreeMax = LRheader,rightTreeMin = LRheader; //左右树的尾
// header.left 和 header.right 分别引用R和L树,为了后面的链走向的一致性
while(true){
if(data.compareTo(M.data) < 0){ // zag...
if(M.left == null){
hasdata = false;
break;
}
else if(data.compareTo(M.left.data) < 0)
M = rightRotate(M);
if(M.left == null){
hasdata = false;
break;
}
rightTreeMin.left = M;
rightTreeMin = M;
M = M.left;
}else if(data.compareTo(M.data) > 0){ // zig...
if(M.right == null){
hasdata = false;
break;
}
else if(data.compareTo(M.right.data) > 0)
M = leftRotate(M);
if(M.right == null){
hasdata = false;
break;
}
leftTreeMax.right = M;
leftTreeMax = M;
M = M.right;
}else
break;
}
leftTreeMax.right = M.left;
rightTreeMin.left = M.right;
M.left = LRheader.right;
if(LRheader.right != null)
LRheader.right.parent = M;
M.right = LRheader.left;
if(LRheader.left != null)
LRheader.left.parent = M;
_hot = root = M;
root.parent = null;
return hasdata == true ? root : null;
}
该实现方式来自计算机科学丛书中的《数据结构与算法分析Java实现》,方法比较巧妙。它灵活的使用了指针技巧减少了很多不必要的操作。我认为这应该是最灵巧的实现了吧。因为我没有按它那样使用逻辑上的nullNode,并且还有维护另外的变量,所以看起来复杂了一点。但精华思想还是和书中无异的。
从以上实现以及我个人的实践中得知,伸展树并不是最优的平衡二叉查找树,它只能保证均衡意义上的O(logn),如果只需要访问少量节点或者经常访问同一个节点,那么它的自调整策略是非常不错的。因为它的平衡条件比较宽松,所以最坏情况下还是会出现O(n)的情况。
五、B树
B树的设计和动机是为了弥合不同存储级别之间在访问速度上的巨大差异,也就是实现高效的IO。通常用于数据库和文件系统等。
先放个B树图,建立一个主观印象:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7UsAf1g3-1616056321469)(http://img3.imgtn.bdimg.com/it/u=1549130698,2260968914&fm=214&gp=0.jpg)]
B树并不是二叉树,它拥有以下新概念:
内部节点:如上图能看见的所有节点被称之为内部节点。
外部节点:上图中没有画出外部节点,叶子节点数值为空其实并不存在的孩子称为外部节点。
阶次:阶次是指B树内部节点中最多的数据量,能反映出B树的矮胖程度。一个m阶次的树可以被称为(⌈m/2⌉,m)-树。比如最简单的B树就是2-3树或和红黑树关系颇深的2-4树。
键:如上图中C G M就是一个节点中的键,他们以顺序有序的形式进行存储。
对于一个m阶B树,定义如下:
- 每个节点最多有m个孩子。
- 每个非叶子节点(除了根)具有至少⌈m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
- 所有叶子都出现在同一水平。也就是说B树必然是颗满多叉树。
所以,在维护一颗B树时,最主要的便是维持它的定义了。每次增加键时,如果键数量超过了m-1,我们便将这种情况称之为上溢。每次删除键时,如果是非叶子节点,并且少于⌈m/2⌉-1个键,那么将这种情况称之为下溢(除了根)。
发生上溢时,我们通常会将节点分裂为[0~m/2] m/2 [m/2+1 ~ m-1]三个部分,将中间节点移到父亲中,并将左右两部分作为新节点的儿子。如图:
发生下溢时,我们通常会将节点…如图:

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









