







 本文详细介绍了如何使用Scrapy模块创建并执行一个针对百度的爬虫项目,包括环境配置、项目搭建、代码编写及运行过程中的常见问题解决。
本文详细介绍了如何使用Scrapy模块创建并执行一个针对百度的爬虫项目,包括环境配置、项目搭建、代码编写及运行过程中的常见问题解决。
前提:安装好scrapy模块
使用pip install scrapy
步骤一:创建项目
在你的程序主目录执行下面命令
scrapy startproject baidu

然后根据步骤继续执行
cd baidu
scrapy genspider baidu baidu.com
注意:在这里可能会出现scrapy没有此命令的错误,请检查环境变量是否配置
步骤二:idea打开项目
我们现在请打开idea,看目录结构
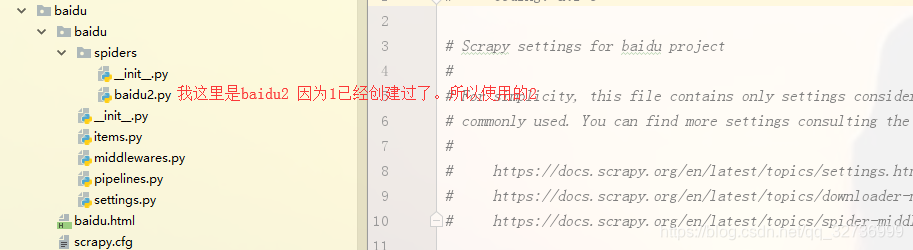
步骤三:编写代码
我们打开baidu.py文件
我们可以在重写的parse方法里面实现我们的业务,使用正则,xpath,等等对response相应回来的数据进行解析。这里小编只是单纯的保存了一下.
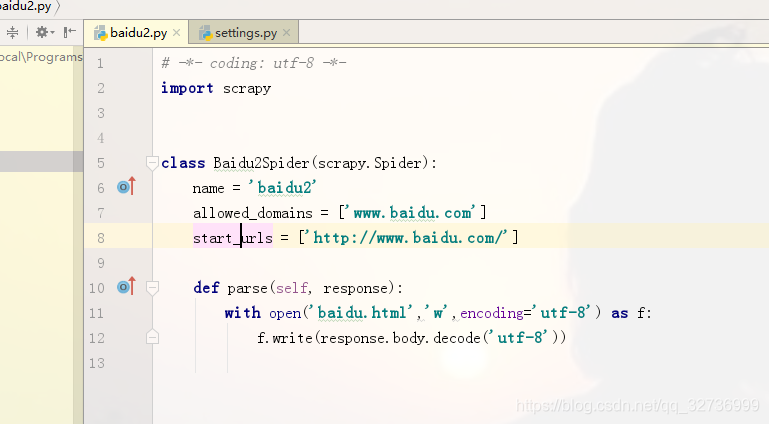
写一个保存的功能
步骤四:执行
scrapy crawl baidu
然后请当前目录查看文件,发现没有baidu.html我们保存的文件
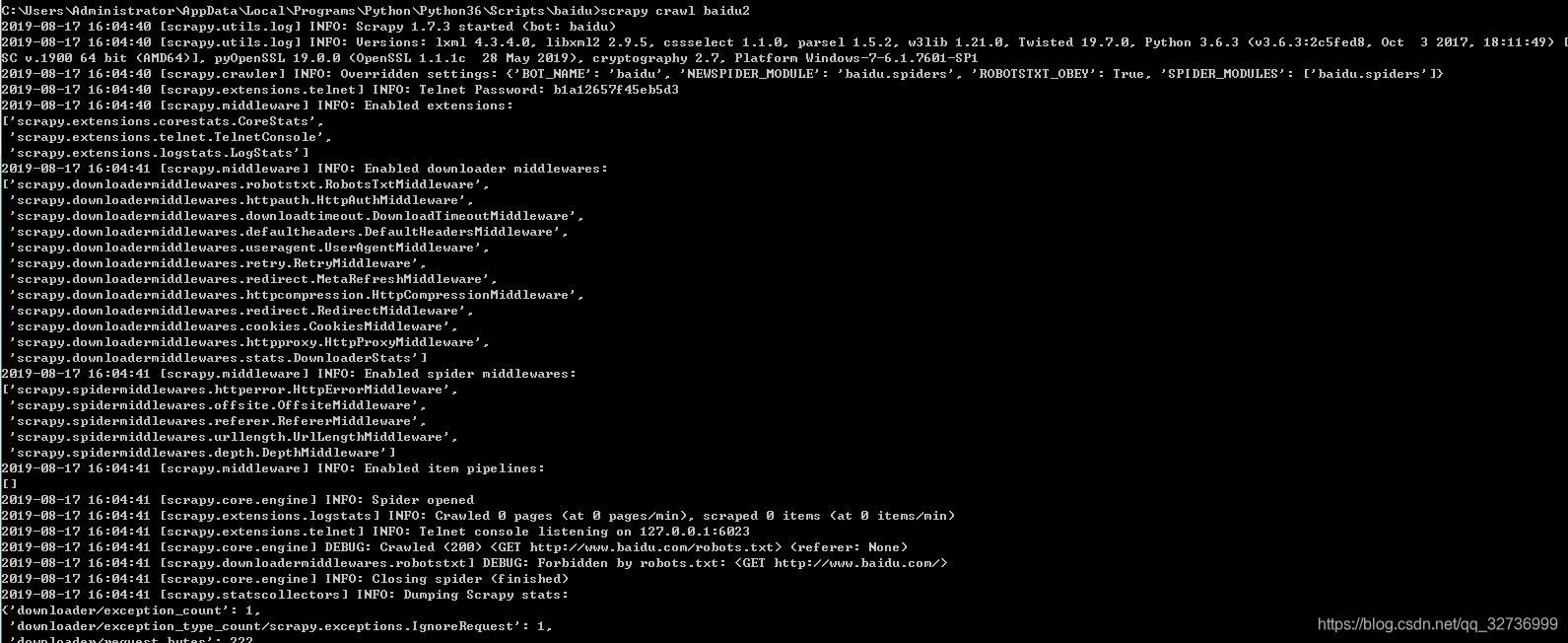
原因:
百度服务器应对爬虫协议:
https://www.baidu.com/robots.txt
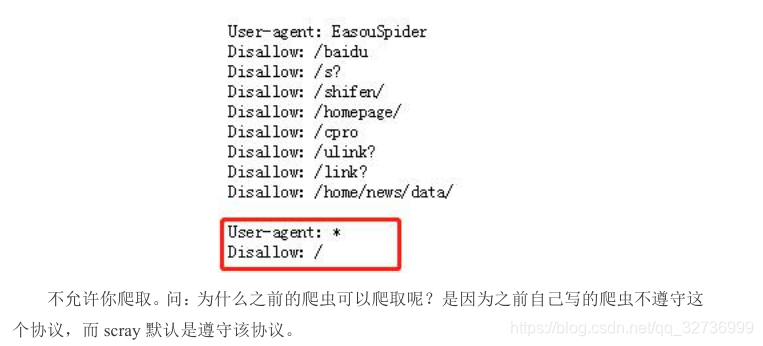
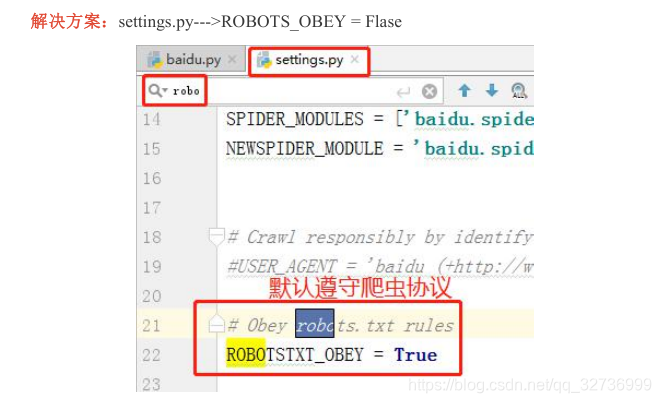
再次执行命令。成功保存。

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









