




 本文介绍了使用Pandas库进行数据挖掘的一些关键操作,包括读取txt和csv文件,设置转换函数,处理日期,更改千分位符,读取Excel文件时的参数设置,以及数据预处理操作如转换数据类型、处理缺失值、计算概率、处理相对时间、提取信息和删除列。
本文介绍了使用Pandas库进行数据挖掘的一些关键操作,包括读取txt和csv文件,设置转换函数,处理日期,更改千分位符,读取Excel文件时的参数设置,以及数据预处理操作如转换数据类型、处理缺失值、计算概率、处理相对时间、提取信息和删除列。
Pandas
索引方式:
ser = pd.Series([1,2,3,4])
ser[[0,1]]
读取txt,csv:
pd.read_table(filepath,sep,header,names,index_col,usecols,dtype,converters,skiprows,
skipfooter,nrows,na_values,skip_blank_lines,parse_dates,thousand,comment,encoding)
converters:字典格式,为某些字段设置转换函数
nrows:读取行数
prase_dates:若为列表,解析为日期;若为嵌套,合并为日期;若为字典,解析列,生成新名
thousand:改变千分位符
读取excel:
pd.read_excel(io,sheetname,header,skiprows,skipfooter,index_col,names,prase_col,prase_dates,
na_values,thousand,conver_float,converters)
conver_float:数值转换为浮点
pand.head() #读取前5行
pand.tail() #读取后5行
例:
cars.xlsx

读取数据
cars = pd.read_excel(r'cars.xlsx',converters={'Boarding':str})
cars.head()
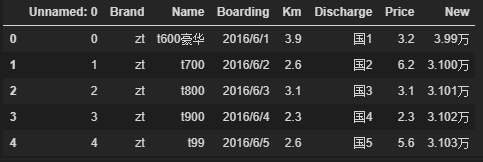
cars.shape
cars.dtype
日期转变,去万
cars.Boarding = pd.to_datetime(cars.Boarding,formate='%Y/%m/%d')
cars.New = cars.New.str[:-1].astype('float')
自动分析数据
cars.describe()
cars.describe(include=['object'])
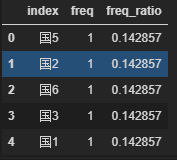
国1的概率
freq = cars.Discharge.value_counts()
freq_ratio = freq / cars.shape[0]
freq_df = pd.DataFrame({'freq':freq,'freq_ra':freq_ratio})
freq_df.reset_index(inplace=True)
freq_df.head()
name_incom.xlsx
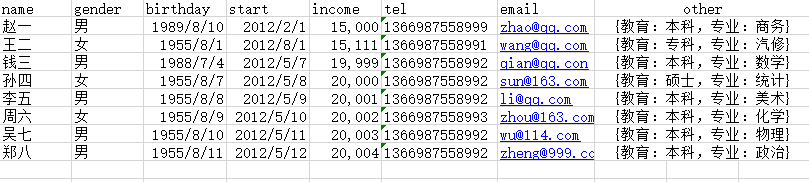
将float变为str,去掉NaN项
condi = pd.read_excel(r'name_incom.xlsx',converters={'tel':str})
condi.dropna(axis=1,how='all')
condi.birthday = pd.to_datetime(condi.birthday,format='%Y/%m/%d')
condi.start = pd.to_datetime(condi.start,format='%Y/%m/%d')
相对时间
condi['age'] = pd.datetime.today().year - condi.birthday.dt.year
condi['work'] = pd.datetime.today().year - condi.start.dt.year
加密
condi.tel = condi.tel.apply(func = lambda x:x.replace(x[3:7],'xxxx'))
邮箱域名
condi['email_domain'] = condi.email.apply(func = lambda x:x.split('@')[1])
提取专业
condi['profession'] = condi.other.str.findall('专业:(.*?)}')
删列
condi.drop(columns=['birthday','start','other'],inplace=True)

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









