







 本文深入探讨Redis的底层数据结构,包括RedisObject、字典(dictEntry)的演变,以及String、Hash、List、Set和ZSet的编码实现。特别关注Redis 7.0引入的listpack如何优化Hash和ZSet的数据存储,同时分析跳表(skiplist)在Redis中的作用和优缺点。
本文深入探讨Redis的底层数据结构,包括RedisObject、字典(dictEntry)的演变,以及String、Hash、List、Set和ZSet的编码实现。特别关注Redis 7.0引入的listpack如何优化Hash和ZSet的数据存储,同时分析跳表(skiplist)在Redis中的作用和优缺点。
🌹 以下分享 Redis 源码分析,如有问题请指教。
🌹🌹 如你对技术也感兴趣,欢迎交流。
🌹🌹🌹 如有对阁下帮助,请👍点赞💖收藏🐱🏍分享😀面试题
- Redis 跳表了解吗?这个数据结构有啥缺点?
- Redis 项目中如何使用?Redis数据结构里哦阿姐哪些?布隆过滤器怎么用?
- Redis 多路IO复用如何理解?为啥单线程可以抗高QPS?
- Redis ZSET底层数据结构实现?
- Redis 跳表解决哪些问题?时间复杂度和空间复杂度如何?
Redis 底层数据结构
| SDS 动态字符串 | 双向链表 | 压缩列表(ziplist) | 哈希表(hashtable) | 跳表(skiplist) | 整数集合(intset) | 快速列表(quicklist) | 紧凑列表(listpack) |
| sds,c | ziplist.c | intset.c | quicklist.c | listpack.c |
核心文件
- db.c
- dict.c
- object.c
图解Redis 键值对数据库
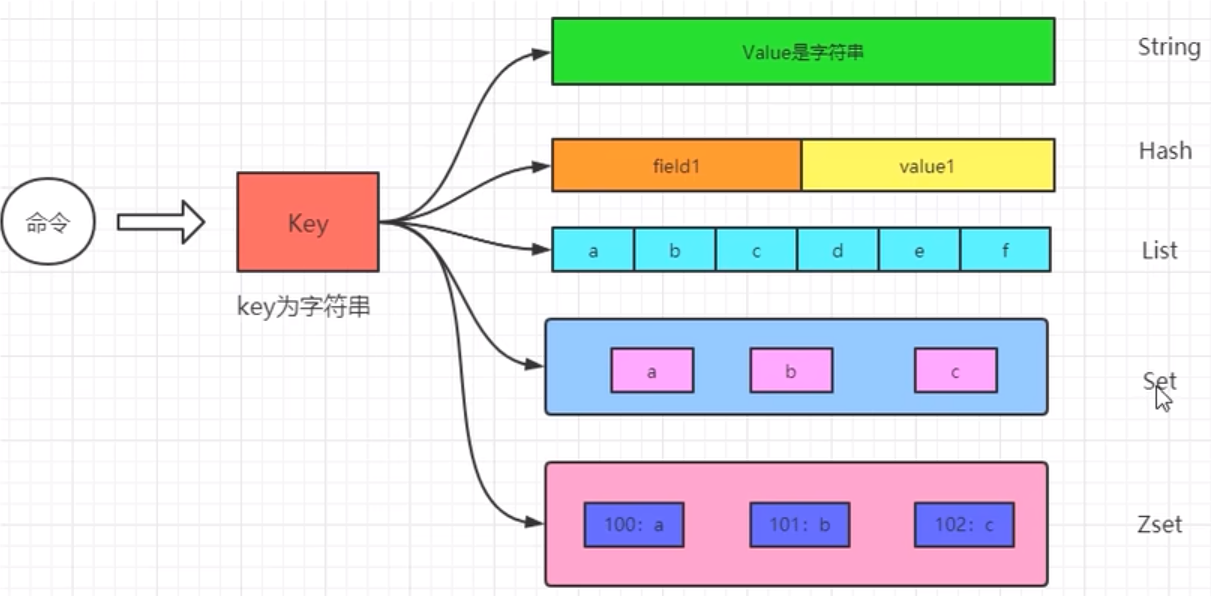
Redis 业务流程
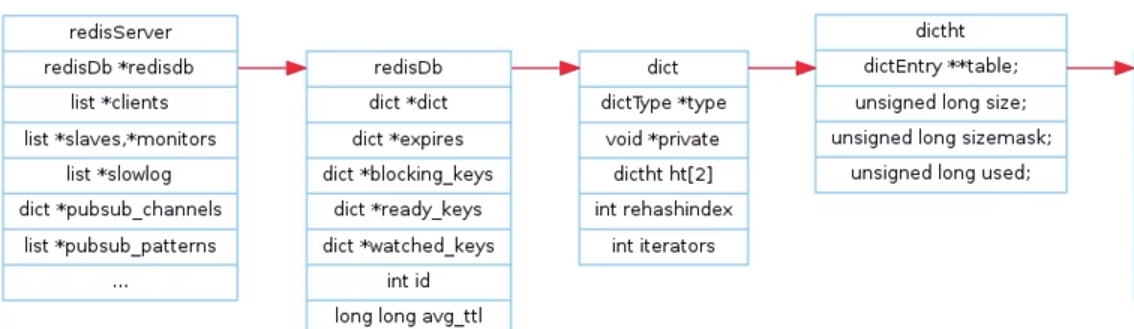
字典(K-V)
Redis 定义了RedisObject 结构体来表示string、hash、list、set、zset等数据类型。
每个键值对都会有一个dictEntry(dich.h,dict.c)

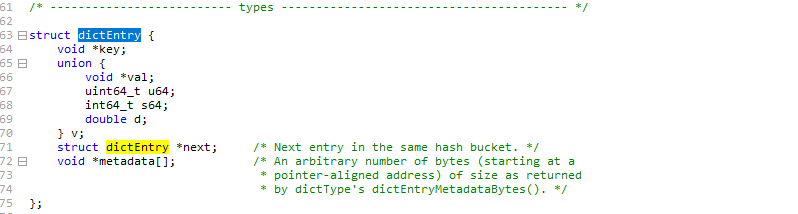
dictEntry 表示哈希表节点的结构。存放void *key和 void *val 指针。
*key 指向String 对象
*val 既能指向String 对象,也能指向集合类型的对象(比如List+Hash+Set+ZSet对象)
注意:
· void *key 和void *val 指针指向的时内部抽象的Redis 对象,Redis 中的每个对象都是由RedisObject构成。
从dictEntry 到RedisObject(server.h)
底层读取,时间复杂度O(1), *ptr 指向底层数据类型

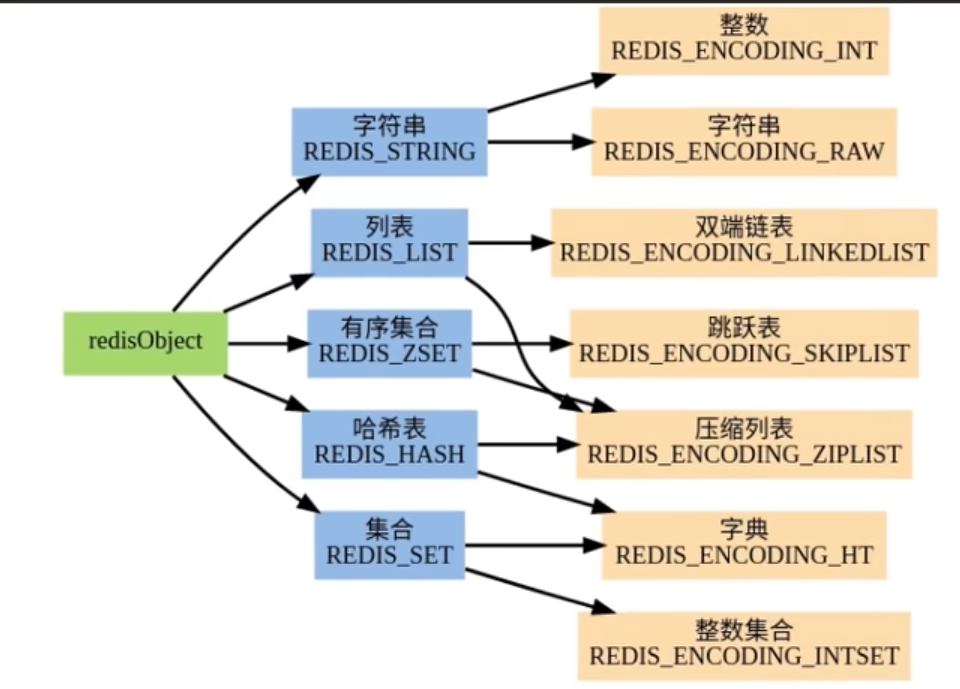
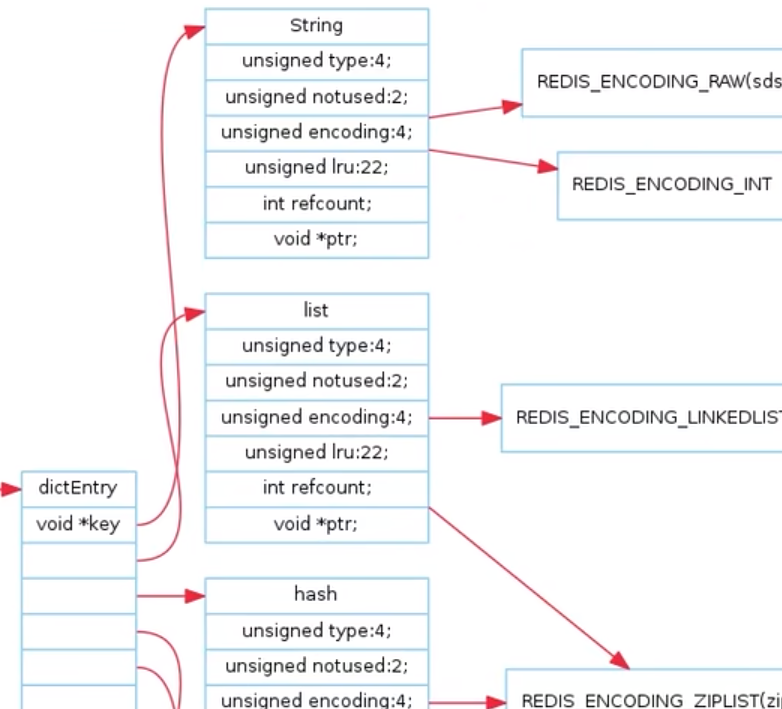
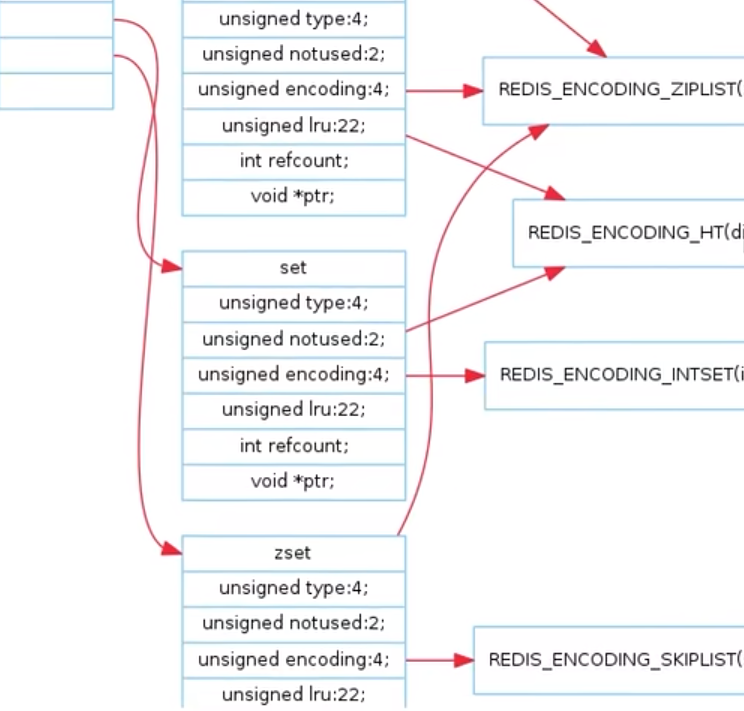
五大结构底层
Redis 数据类型于数据结构总纲图
| SDS 动态字符串 | 双向链表 | 压缩列表 (ziplist) | 哈希表 (hashtable) | 跳表 (skiplist) | 整数集合 (intset) | 快速列表 (quicklist) | 紧凑列表 (listpack) |
Redis 底层模型和结构

| Redis 结构 | Redis 6 | Redis7 |
| String | SDS | SDS |
| Set | Intset+Hashtable | Intset + Hashtable |
| Zset | SkipList+ZipList | SkipList+Listpack |
| list | QuickList+ZipList | QuickList |
| Hash | Hashtable+ZipList | Hashtable+Listpack(紧凑列表) |

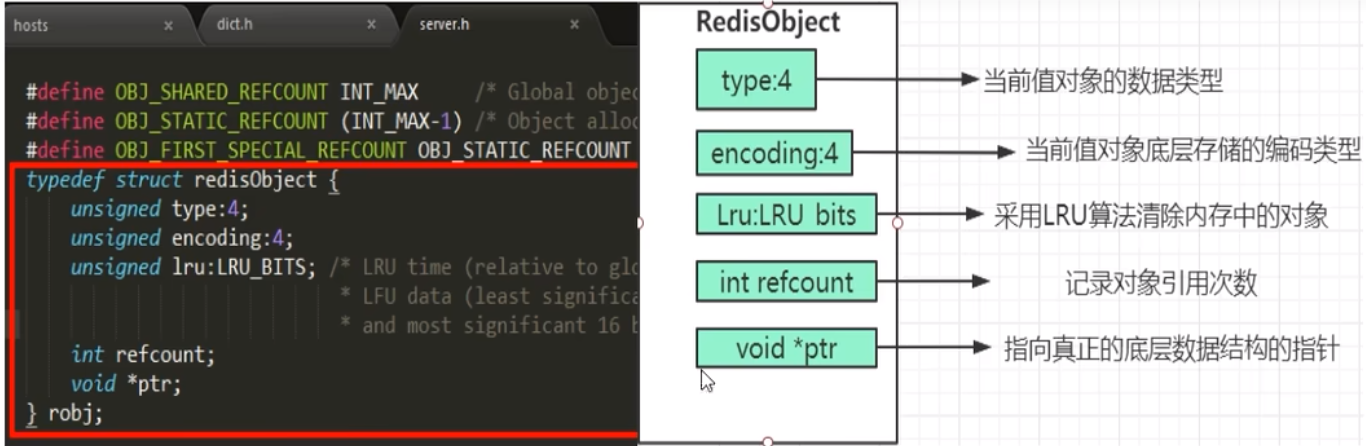
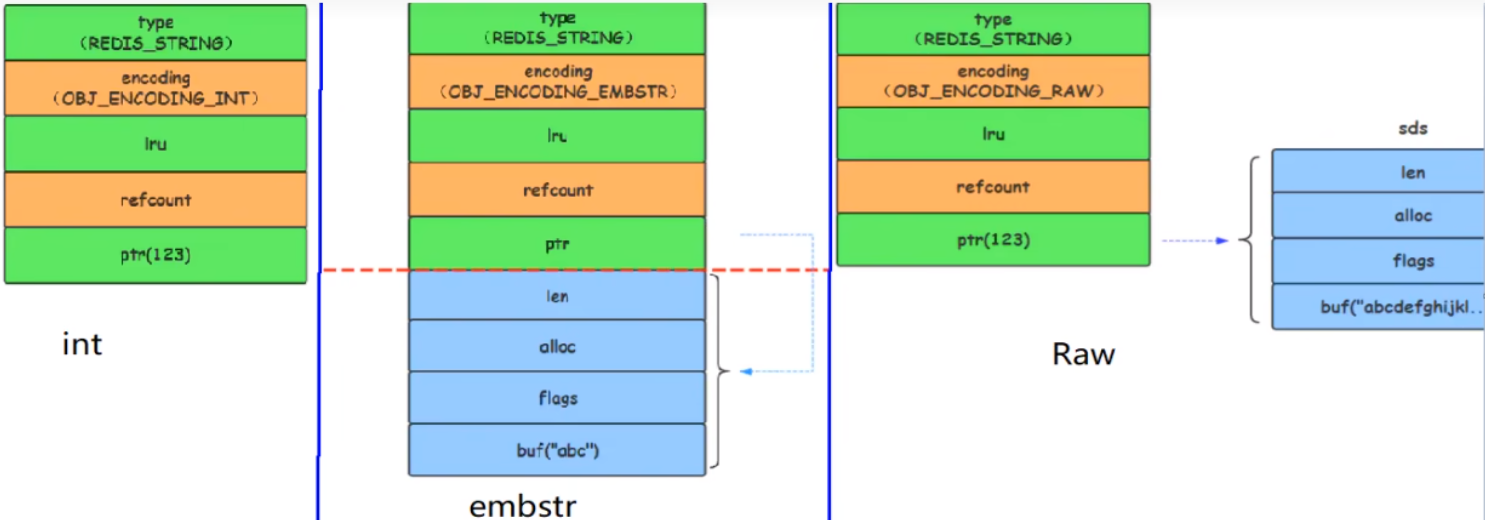
RedisObject 字段
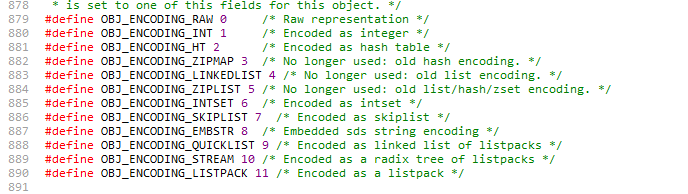
encoding 分类

开启客户端调试


| Value at | 内存地址 |
| refcount | 应用次数 |
| encoding | 物理编码类型 |
| serializedlength | 序列化后的长度 |
| lru | 记录最近使用时间戳 |
| lru_seconds_idle | 空闲时间 |
String 数据结构
编码
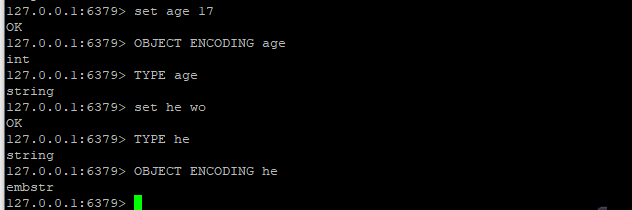
int
保存long型的64位有符号整数(-2^63-1~2^63-1 ),默认0L
只有整数才会使用int,如果时浮点数,Redis 内部先键浮点数转换位字符串,然后保存
embstr
代表embstr格式的SDS(simple Dynamic String 简单动态字符串),保存长度小于44字节的字符串
raw
保存长度大于44字节的字符串
案例
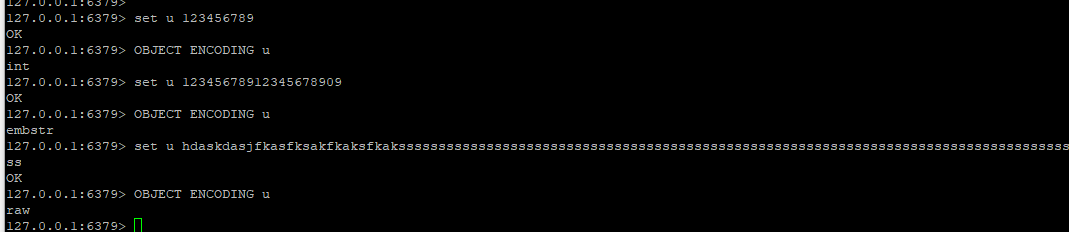
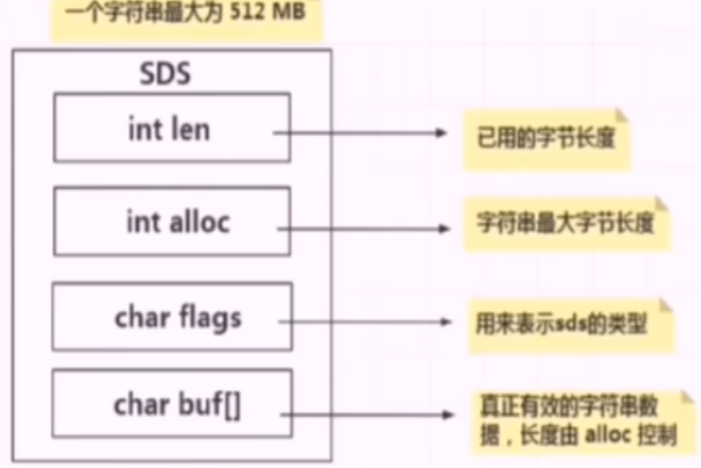
SDS (simple Dynamic String 简单动态字符串)

sdshdr5 2^5=32 byte(内部测试,一般不用)
sdshdr8 2^8=256 byte
sdshdr16 2^16=65536 byte =64k
sdshdr32 2^32=32 byte 4G
sdshdr64 2^64=17179869184G 存储不同长度的字符串
为啥单独设计SDS
| C语言 | SDS | |
| 字符串长度处理 | 需要从头开始遍历,直到遇到“0'为止,时间复杂度O(N) | 记录当前字符串的长度,直接读取即可,时间复杂度 O(1) |
| 内存重新分配 | 分配内存空间超过后,会导致数组下标越级或者内存分配溢出 | 空间预分配 SDS 修改后,len 长度小于 1M,将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,将分配1M的使用空间。 惰性空间释放 有空间分配对应的就有空间释放。SDS 缩短时不会回收多余的内存空间,而是使用 free 字段记录多出来的空间。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。 |
| 二进制安全 | 二进制数据并不是规则的字符串格式,可能会包含些特殊的字符,比如'\o'等。C中字符串遇到'\o'会结束,那'\o'之后的数据无法读取 | 根据 len 长度来判断字符串结束的,不存在二进制安全的问题 |
总结
| int | Long类型整数时,Redisobiect中的ptr指针直接赋值为整数数据,不再额外的指针再指向整数,节省指针的空间开销 |
| embstr | 当保存的是字符串数据且字符串小于等于44字节时,embstr类型将会调用内存分配函数,只分配一块连续的内存空间,空间依次包含 redisobiect 与 sdshdr 两个数据结构,让元数据、指针和SDS是一块连续的内存区域,避免内存碎片 |
| raw | 当字符串大于44字节时,SDS的数据量变多,SDS和Redisobiect布局分开,会给SDS分配多的空间并用指针指向SDS结构,raw 类型将会调用两次内存分配函数,分配两块内存空间,一块用于redisObject结构,而另一块用于包含sdshdr 结构 |
Hash 数据结构
Redis 6 Hashtable +Ziplist
Hash类型键的字段个数 小于 hash-max-ziplist-entries 并且每个字名和字段值的长度 小于 hash-max-ziplist-value 时,Redis才会使用 OBJ_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会转换为 OBJ_ENCODING_HT的编码方式
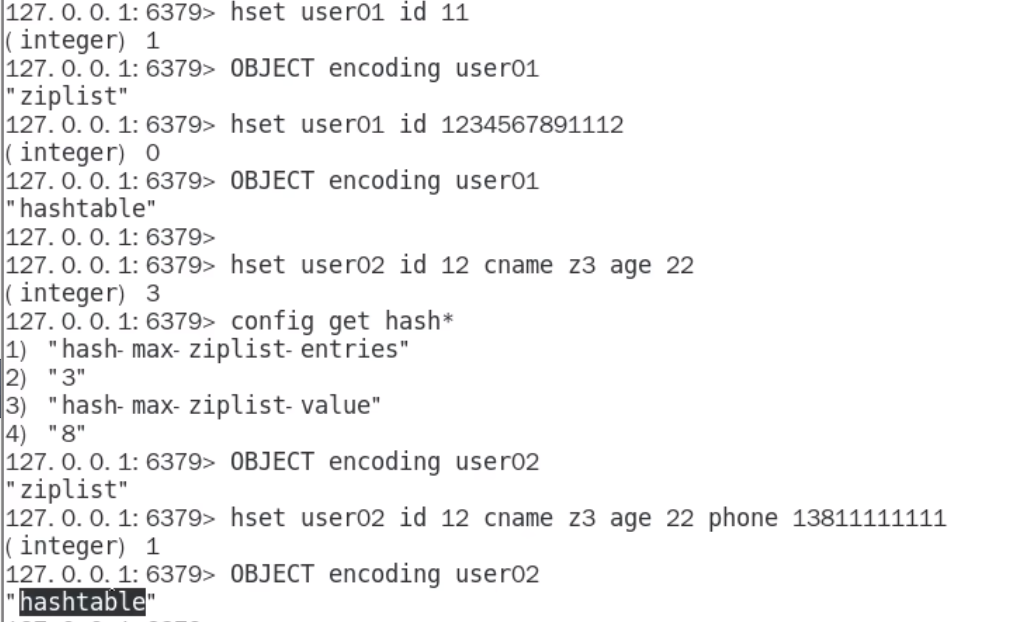
结论
哈希对象保存的键值对数量小于 512个;
所有的键值对的健和值的字符串长度都小于等于64字节(一个英文字母一个字节) 时用字符串,反之用Hashtable
ziplist 升级到hashtable 无法降级到ziplist
Redis 7 Hashtable +listpack
| Redis 6 | Redis 7 | |
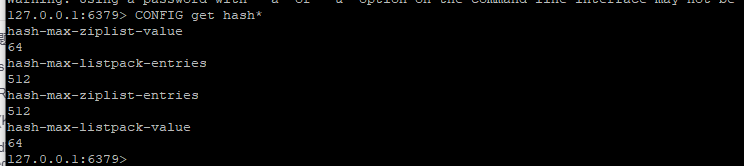
| hash-max-ziplist-value 使用斥缩列表保存时哈希集合中单个元素的最大长度。 | 64 | 64 |
| hash-max-ziplist-entries 使用压缩列表保存时哈希集合中的最大元素个数 | 512 | 512 |
| hash-max-listpack-entries 使用紧凑列表保存时哈希集合中的最大元素个数。 | 无 | 512 |
| hash-max-listpack-value 使用紧凑列表保存时哈希集合中单个元素的最大长度 | 无 | 64 |
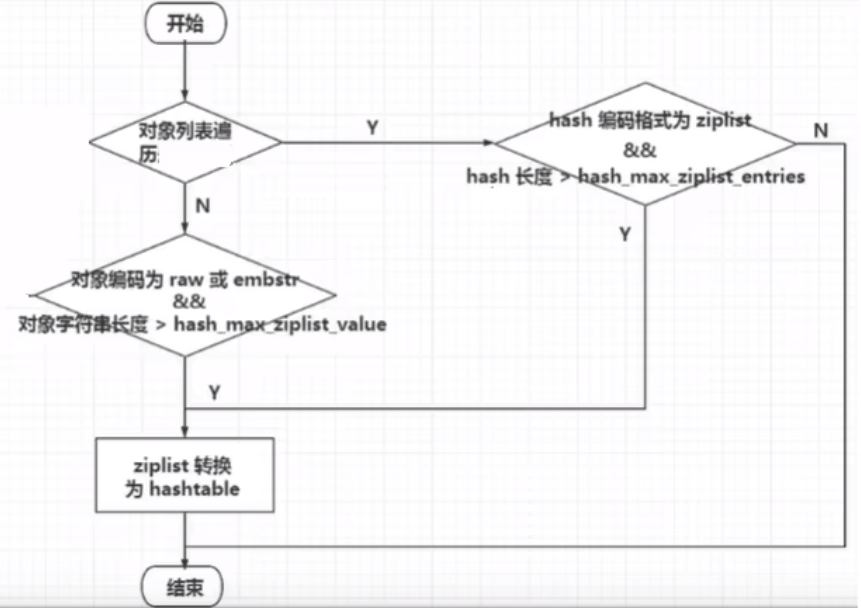
有ziplist了,为什么出来一个listpack紧凑列表?
ziplist 新增或更新元素可能会出现连锁更新现象(致命缺点导致被listpack替换)
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配元素的 prevlen 占用空间都发生变化,从而引起连锁更新问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
listpack 是 Redis 设计用来取代掉 iplist 的数据结构,它通过每个节点记录自己的长度且放在节点的尾部,来彻底解决掉了 ziplist存在的连锁更新的问题
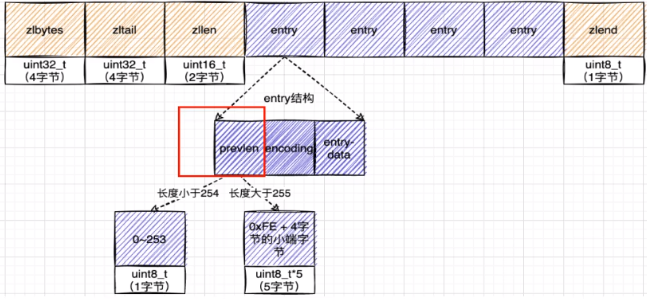
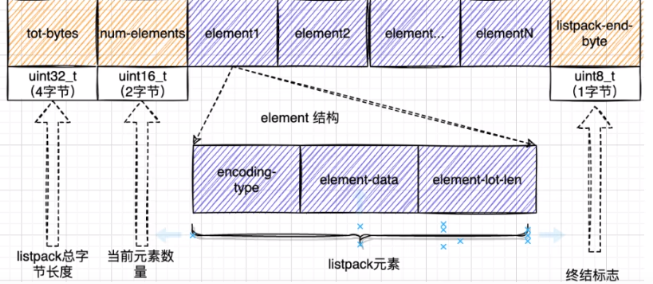
listpack(listpack.h)


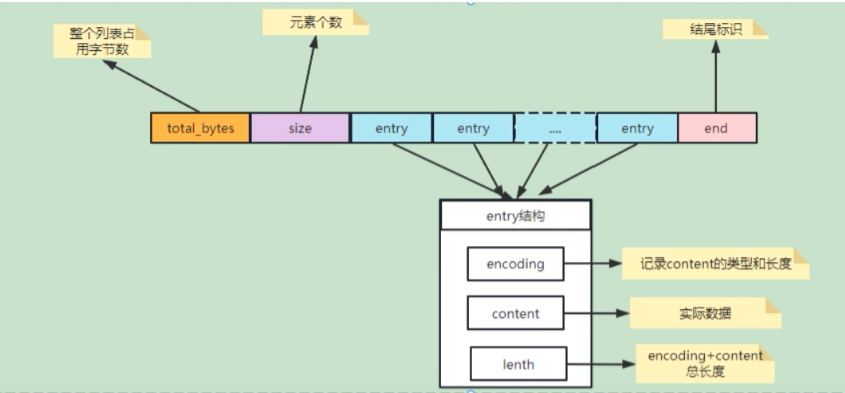
ziplist vs listpack
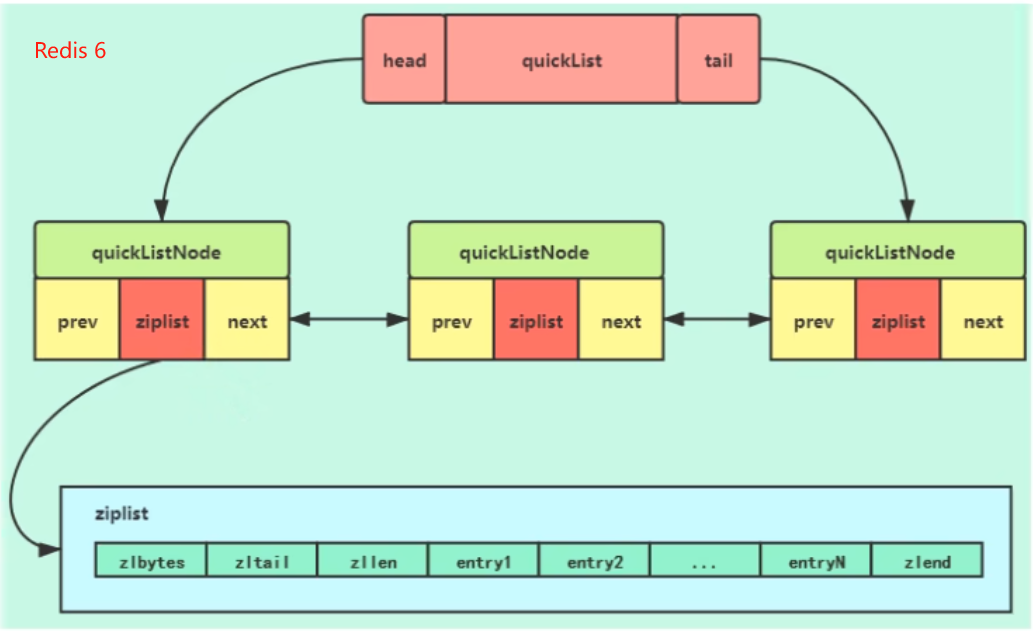
List 数据结构 (quicklist.h)
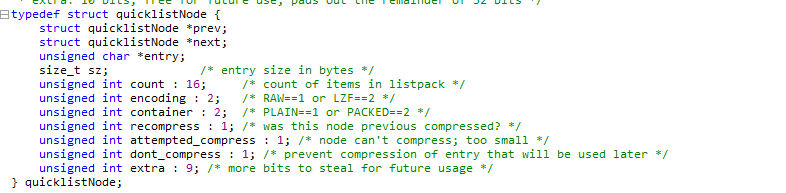
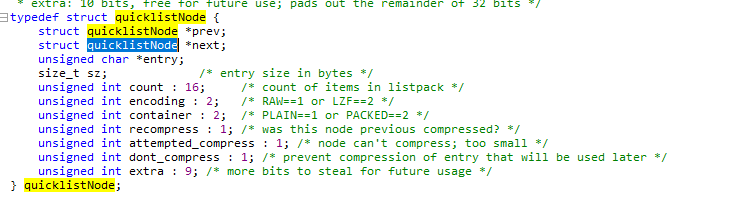
双端链表结构,quicklist
Redis6 中quicklist 封装的是ziplist
Redis7 中quicklist 封装的是listpack

list-compress-depth 0
表示一个quicklist两端不被压缩的节点个数。这里的节点是指quicklist双向链表的节点,而不是指ziplist里面的数据项个数0: 是个特殊值,表示都不压缩。这是Redis的默认值。
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩
list-max-ziplist-size -2
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。它只能取-1到-5这五个值,
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。 (注: 1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(默认)-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
list-max-listpack-size 取代 list-max-ziplist-size
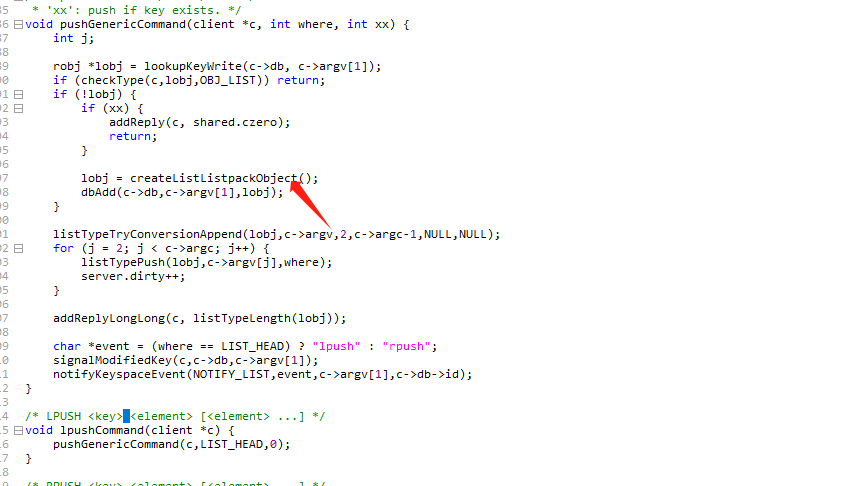 Set 数据结构
Set 数据结构
intset+hashtable
案例
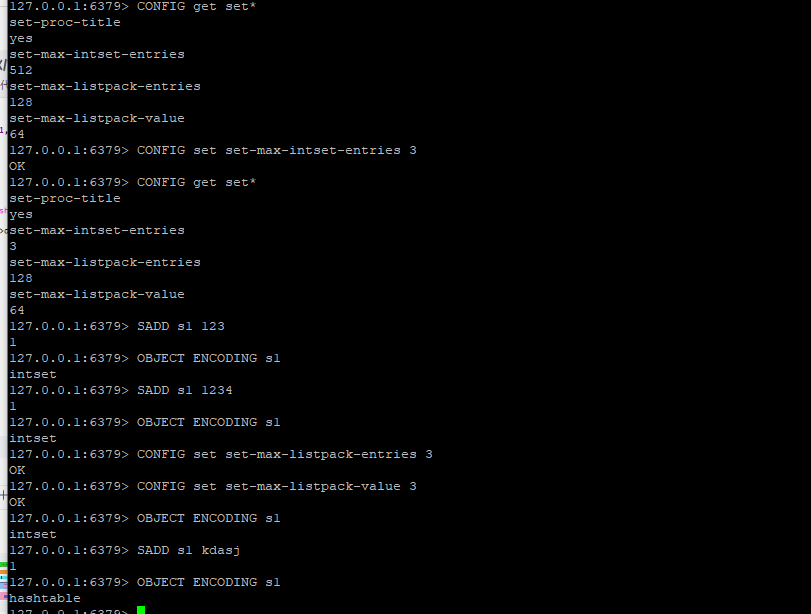
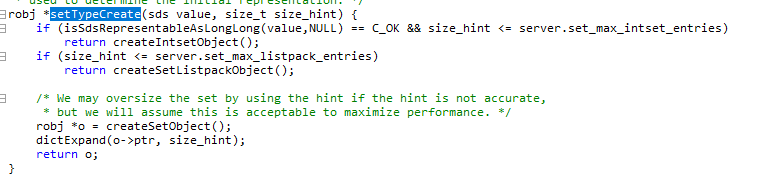
验证 set-max-intset-entries +set-max-listpack-entries+set-max-listpack-value,创建intset->listpack->hashtable
ZSet 数据结构
Redis6 ziplist +skiplist
Redis7 listpack +skiplist

案例
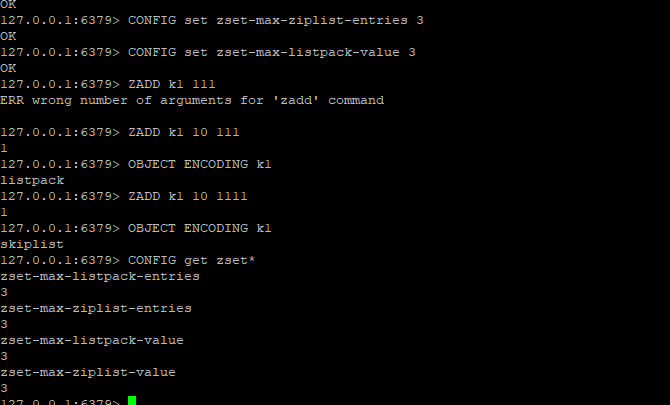
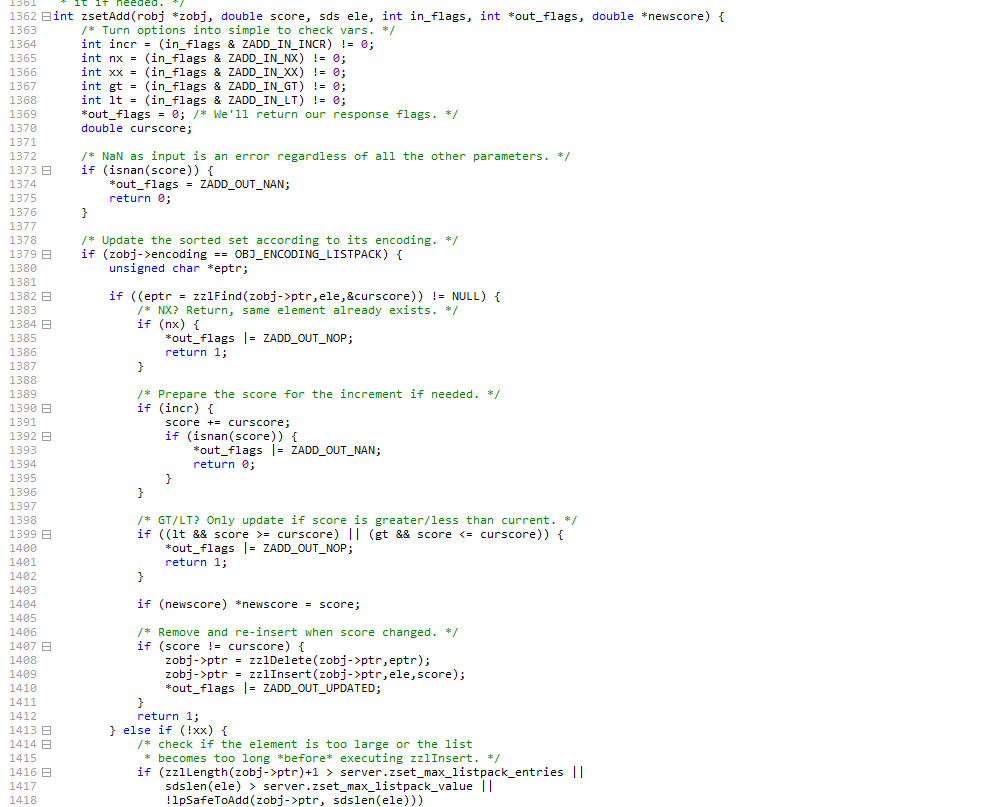
底层数据结构
| 字符串(string) | int: 8个字节的长整型 raw: 大于44个字节的字符串。 |
| 哈希(hash) | zipist 乐缩列表): 当哈希类型元素个hash-max-ziplist-entries 配认512)、同时所有值都hash-max-zidlist-vaue置默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧的 结构实现多个元素的连续存,所以在节省内存方面比hashtable更加优秀。 hashtable(l哈希表): 当哈希类型无法满足ziplist的条件时,Redis会使 用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。 |
| 列表(list) | ziplist(压缩列表): 当列表的元素个数小于list-max-ziplist-entries置默认512),同时列表中每元素的值都小ist-max-zidist-value配置时默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。 linkedlist(链表): 当列表类型无法满足ziplist的条件时,Redis会使用 linkedlist作为列表的内部实现。quicklist ziplist和linkedlist的结合以ziplist为节点的链表linkedlist) |
| 集合(set) | intset(整数集合): 当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512)时,Redis会用intset来作为集合的内部实现,从而减少内存的使用。 hashtable(哈希表): 当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现 |
| 有序集合(zset) | ziplist(压缩列表): 当有序集合的元素个数小于zset-max-ziplist entries置(默认128),同时每素的值都于set-max-ziplist-value配 置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。 skiplist(张跃表): 当ziplist条件不满足时,有序集合会使用skiplist作为内部实现因为此时ziplist的读写效率会下降 |
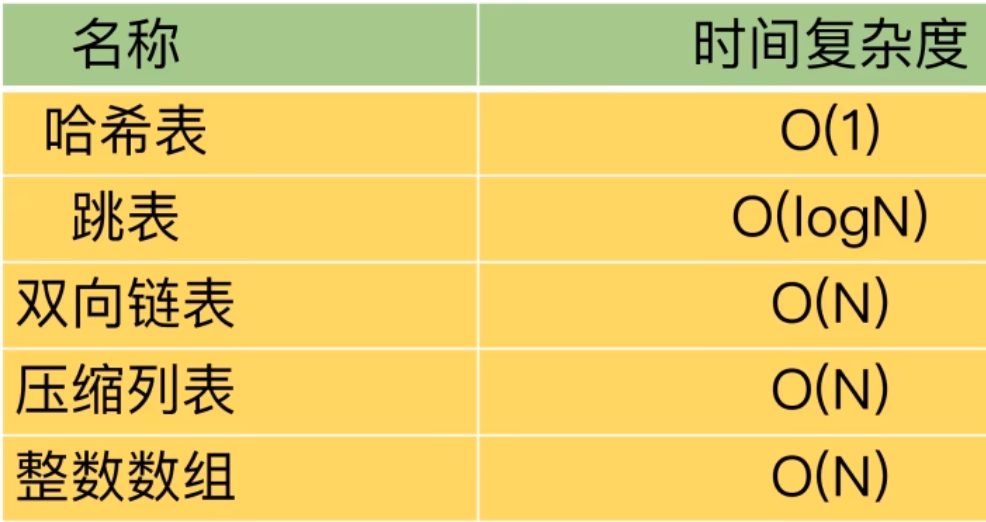 | |
***skiplist 跳表
实现二分查找分有序列表,是一种以空间换时间的结构。总结就是跳表=链表+多级索引
为什么会出现跳表?
单链表的时间复杂度位O(n),当数据过大时,遍历数据变慢。因此引出如下思考....
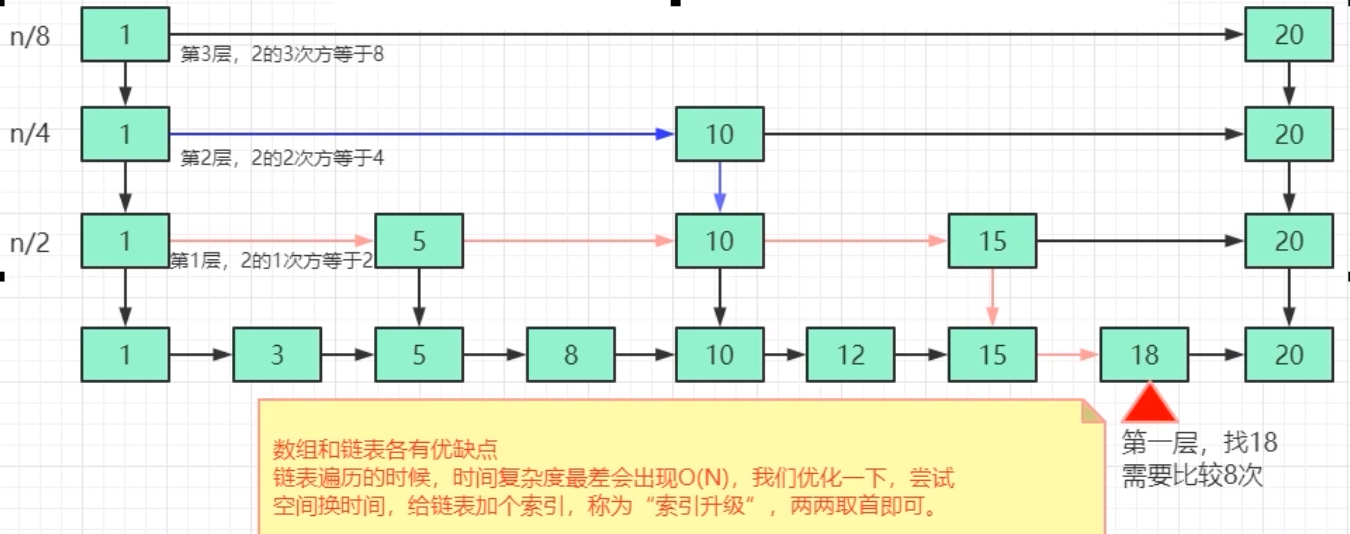
时间复杂度计算 : n/2 ->n/4->n/8->n/16 ......->n/2^k
空间复杂度 O(n)
优缺点
| 优点 | 缺点 |
| 跳表是一个最典型的空问换时向解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的用范围应该还是比较有限的 | 维护成本相对要高,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1) 新增或者删除时需把所有索引都更新一遍,为了保证原始链表中数据的有序性,需要先找到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n) |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











