







Fourier Contour Embedding for Arbitrary-Shaped Text Detection
文末有总结一些CVPR有关OCR领域的最新论文及代码地址
Contribution
- 提出一种任意形状文本检测的方法,再CTW1500和Total-Text数据集上达到SOTA。
- 提出一种傅里叶轮廓嵌入(FCE)方法来对任意形状文本轮廓进行拟合
- 构建具有主干、特征金字塔(FPN)网络和简单傅里叶变换(IFT)和非最大值抑制(NMS)后处理的FCENet网络模型
Fourier Contour Embedding
作者定义了一个复值函数
f
:
R
↦
C
f:\mathbb{R}\mapsto\mathbb{C}
f:R↦C 来表示一个封闭的文本轮廓,其中:
f
(
t
)
=
x
(
t
)
+
i
y
(
t
)
(1)
f(t)=x(t)+iy(t) \tag 1
f(t)=x(t)+iy(t)(1)
其中,
i
i
i表示虚数单位,
(
x
(
t
)
,
y
(
t
)
)
(x(t),y(t))
(x(t),y(t))定义为
t
t
t时刻的空间坐标。由于文本轮廓是封闭的因此函数
f
f
f满足
f
(
t
)
=
f
(
t
+
1
)
f(t)=f(t+1)
f(t)=f(t+1).
f
(
t
)
f(t)
f(t)可以通过傅里叶逆变换(IFT)重新表示为:
f
(
t
)
=
f
(
t
,
c
)
=
∑
k
=
−
∞
+
∞
c
k
e
2
π
i
k
t
(2)
f(t)=f(t,\textbf{c})=\sum_{k=-\infty}^{+\infty}{c_ke^{2\pi ikt}} \tag 2
f(t)=f(t,c)=k=−∞∑+∞cke2πikt(2)
其中,
k
∈
Z
k\in \mathbb{Z}
k∈Z表示频率,
c
k
c_k
ck是用来表征频率k的初始状态的复值傅里叶系数。公式中每个分量
c
k
e
2
π
i
k
t
c_ke^{2\pi ikt}
cke2πikt表示具有给定初始hand direction向量
c
k
c_k
ck的固定频率k的圆周运动。
所以轮廓可以被看作不同频率圆周运动的结合。如下图所示:

作者指出,低频分量负责文本轮廓,高频分量负责轮廓的细节信息。再实验中K=5便可以获得比较满意的近似文本轮廓。
文本轮廓函数通常并不能获取到解析解。作者再实际编码中对文本轮廓进行离散采样,将连续函数f离散为N个点,写作
f
(
n
N
)
f(\frac{n}{N})
f(Nn),其中
n
∈
[
1
,
…
,
N
]
n\in [1,\ldots ,N]
n∈[1,…,N]。此时,
c
k
c_k
ck可以根据离散傅里叶变换可以表示为:
c
k
=
1
N
∑
n
=
1
N
e
−
2
π
i
k
n
N
(3)
c_k=\frac{1}{N}\sum^N_{n=1}{e^{-2\pi ik\frac{n}{N}}} \tag 3
ck=N1n=1∑Ne−2πikNn(3)
其中,
c
k
=
u
k
+
i
v
k
c_k=u_k+iv_k
ck=uk+ivk,
u
k
u_k
uk是复数的实部,
v
k
v_k
vk是复数的虚部。当
k
=
0
k=0
k=0时,
c
0
=
u
0
+
i
v
0
=
1
N
∑
n
f
(
n
N
)
c_0=u_0+iv_0=\frac{1}{N}\sum_nf(\frac{n}{N})
c0=u0+iv0=N1∑nf(Nn)是轮廓的中心位置。对于任意文本轮廓f,文章提出的傅里叶轮廓嵌入(FCE)方法可以将轮廓在傅里叶域表示为一个紧致的
2
(
2
K
+
1
)
2(2K+1)
2(2K+1)维向量
[
u
−
K
,
v
−
K
,
…
,
u
0
,
v
0
,
…
,
u
K
,
v
K
]
[u_{-K},v_{-K},\ldots,u_0,v_0,\ldots,u_K,v_K]
[u−K,v−K,…,u0,v0,…,uK,vK]定义为傅里叶签名向量。
FCE方法包括两个阶段。
-
重采样阶段
-
在文本轮廓上等距地采样固定数目的N个点(实验中N=400),得到重采样点序列 { f ( 1 N ) , … , f ( 1 ) } \{f(\frac{1}{N}),\ldots,f(1)\} {f(N1),…,f(1)}.
-
由于不同的数据集具有不同数量的文本实例的地面真值点,并且它们相对较小,因此该重采样是必要的。
-
重采样策略使得FCE能够兼容所有具有相同设置的数据集。
-
不同的重采样序列可以导致不同的傅里叶签名向量。因此在重采样阶段对 f ( t ) f(t) f(t)函数起始点、采样方向和移动速度进行约束:
- Starting point:将起点 f ( 0 ) 或 f ( 1 ) f(0)或f(1) f(0)或f(1)设置为中心点 ( u 0 , v 0 ) (u_0,v_0) (u0,v0)的水平线与文本轮廓之间的最右交点。
- Sampling direction:沿着轮廓顺时针重新采样
- Uniform speed:均匀采样,相邻点之间距离保持不变,保证采样速度均匀
-
-
傅里叶变换阶段
- 傅里叶变换阶段,重采样点序列被变换成其对应的傅里叶特征向量。
FCENet
FCENet使用带DCN的ResNet50作为backbone,使用FPN作为颈部网络用来提取多尺度特征,并提出了傅里叶预测头部。文章提到模型使用FPN的P3,P4和P5特征图进行预测。
傅里叶预测头包含有两个分支,分别负责分类和回归。每个分支由3个 3 × 3 3\times3 3×3卷积层和一个 1 × 1 1\times1 1×1卷积层组成,每个卷积层后有一个ReLU非线性激活层。
-
分类分支
分类分支中,模型预测文本区域(TR)的每像素掩码和文本中心区域(TCR)的每像素掩码矩阵。实验发现TCR可以有效提高模型的预测性能,因为TCR可以有效过滤掉文本边界低质量的预测。
-
回归分支
文本傅里叶特征向量针对该文本中的每个像素被回归。为了针对不同规模的文本实例,P3,P4和P5特征图分别负责小、中和大文本实例。通过IFT和NMS来将检测结果从傅里叶域重建到空间域。

检测头由分类和回归两个分支组成,分类分支中,输出的结果通道数是4,前两个通道表示的是每个像素是否是文本区域(Text Region,TR)的概率,后两个通道表示的是每个像素是否是文本中心区域(Text Center Region)的概率,分类分支相当于是分割得到文本区域,然后求文本区域的轮廓中心。
回归分支的通道数 22 22 22,表示的是取傅里叶展开的自由度 k = 5 k=5 k=5,取前5个高频和低频及 k = 0 k=0 k=0共 11 11 11个复数傅里叶系数,复数使用$( u_k , v_k ) $来表示,因此总共 22 22 22个变量,通过使用傅里叶逆变换求得最后的检测结果。
————————————————
版权声明:本文为优快云博主「恒友成」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/lx_ros/article/details/129112928
基于PaddleOCR的FCENet代码解析
- 持续更新,建议收藏
paddleOCR代码结构
我们主要集中于场景文字检测和识别两个方面,主要关注的文件如下:
-
configs——主要是配置文件
-
ppocr——主要存放了模型相关的文件,是PaddleOCR框架的核心。包括有:
- 数据增强
- 损失函数
- 评价指标
- 模型定义
- 优化器
- 后处理
- 工具类
等等算法的实现。
-
tools——存放模型训练,推理等脚本
我们需要关注的文件就这些,接下来会先从config文件说起,了解PaddleOCR的配置文件。
configs文件
configs文件夹中保存有如下的7个文件,分别对应OCR中一些热门的任务:
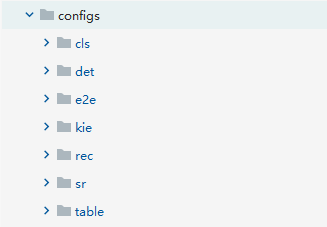
我们也重点关注det和rec两个文件夹,cls是ppocr中一个针对文本方向的文本分类器,如果有需要可以对检测出来的文字进行方向分类,然后做对应的处理。
我们以det任务中的dbnet为例,也就是det_res18_db_v2.0.yml文件为例,说明ppocr配置文件的结构。一般对配置文件的命名采用下面的方式 任务_ backbone _ 算法 _ 数据集
1. Global字段
Global:
use_gpu: true
epoch_num: 1200
log_smooth_window: 20
print_batch_step: 2
save_model_dir: ./output/ch_db_res18_icdar2015+project/
save_epoch_step: 1200
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy
checkpoints: #./output/ch_db_res18_icdar2015+project/best_accuracy
save_inference_dir:
use_visualdl: False
infer_img: ./data/icdar2015/text_localization/test/
save_res_path: ./output/det_db/predicts_db.txt
Global是对整个训练过程进行配置的字段,在Global下的配置项会对整个训练进行配置。
use_gpu: 是否使用gpu进行训练,值为true或false
epoch_num: epoch次数
log_smooth_window: log平滑窗口,每次打印输出队列里的中间值
print_batch_step: 多少次迭代打印一次log
save_model_dir: 训练模型保存地址
save_batch_step: 多少个epoch保存一次模型(这里文件中save_batch_step=epoch_num,在实际中只在第1200个epoch保存模型,但是在训练过程中会保存best_accuracy模型,这样会大大减小磁盘的占用)
eval_batch_step: 设置模型评估间隔,2000 或 [1000, 2000],2000 表示每2000次迭代评估一次,[1000, 2000]表示从1000次迭代开始,每2000次评估一次
cal_metric_during_train: 设置是否在训练过程中评估指标,此时评估的是模型在当前batch下的指标,也就是训练集的表现
pretrained_model: 预训练模型地址
checkpoints: 加载模型参数的路径,用于训练中断后恢复训练使用
save_inference_dir: 该字段是训练完成后将模型转换为推理模型的保存地址
use_visualdl: 是否使用visualdl对训练过程的log进行可视化
infer_img: 测试图像的地址,可以是文件也可以是文件夹
save_res_path: 对检测结果的保存地址
在识别任务中,还会有一些字段如下:
character_dict_path: 字典路径
max_text_length: 文本最大长度
use_space_char: 是否识别空格
2.Architecture字段
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: ResNet_vd
layers: 18
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
Architecture字段是定义网络模型的超参数。在PaddleOCR中,网络被划分为Transform,Backbone,Neck和Head四个阶段
model_type: 网络类型,一般是检测任务和识别任务
algorithm: 算法,表明模型使用的算法
Transform: 变换方式,ppocr文档指出目前仅针对rec任务支持
Backbone: 表明接下来是设置backbone网络的相关参数
name: backbone类名
layers:resnet层数
Neck: 颈部网络设置
name: neck类名
out_channels: 输出通道数
Head: 头部网络设置
name: head类名
k: DBHead中二值化的系数
3.Loss字段
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Loss字段是定义损失函数的一些超参数
name: 网络loss类名
balance_loss: DBLossloss中是否对正负样本数量进行均衡(使用OHEM)
main_loss_type: DBLossloss中shrink_map所采用的loss
alpha: DBLossloss中shrink_map_loss的系数
beta: DBLossloss中threshold_map_loss的系数
ohem_ratio: DBLossloss中的OHEM的负正样本比例
4.Optimizer字段
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 2
regularizer:
name: 'L2'
factor: 0
对优化器的一些定义
name: 优化器类名
beta1: 设置一阶矩估计的指数衰减率
beta2: 设置二阶矩估计的指数衰减率
lr: 设置学习率decay方式
name: 学习率decay类名
learning_rate: 基础学习率
regularizer: 设置网络正则化方式
name: 正则化类名
factor: 正则化系数
5.PostProcess字段
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
对后处理的一些定义
name: 后处理类名
thresh: DBPostProcess中分割图进行二值化的阈值
box_thresh: DBPostProcess中对输出框进行过滤的阈值,低于此阈值的框不会输出
max_candidates: DBPostProcess中输出的最大文本框数量
unclip_ratio: DBPostProcess中对文本框进行放大的比例
6.Metric字段
Metric:
name: DetMetric
main_indicator: hmean
定义评价方法
name: 指标评估方法名称
main_indicator: 主要指标,用于选取最优模型
7.data字段
Train:
dataset:
name: SimpleDataSet
data_dir: ./data/icdar2015/text_localization/
label_file_list:
- ./data/icdar2015/text_localization/train_icdar2015_label_merge.txt
ratio_list: [1.0]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [-10, 10] } }
- { 'type': Resize, 'args': { 'size': [0.5, 3] } }
- EastRandomCropData:
size: [960, 960]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
loader:
shuffle: True
drop_last: False
batch_size_per_card: 8
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir:
- ./data/icdar2015/text_localization/
label_file_list:
- ./data/icdar2015/text_localization/test_icdar2015_label_merge.txt
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
# image_shape: [736, 1280]
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1
num_workers: 2
定义数据集和训练时dataloader的一些超参数
dataset: 每次迭代返回一个样本
name: dataset类名
data_dir: 数据集图片存放路径
label_file_list: 数据标签路径
ratio_list: 数据集的比例,若label_file_list中有两个train_list,且ratio_list为[0.4,0.6],则从train_list1中采样40%,从train_list2中采样60%组合整个dataset
transforms: 对图片和标签进行变换的方法列表
loader: dataloader相关
shuffle: 每个epoch是否将数据集顺序打乱
batch_size_per_card: 训练时单卡batch size
drop_last: 是否丢弃因数据集样本数不能被 batch_size 整除而产生的最后一个不完整的mini-batch
num_workers: 用于加载数据的子进程个数,若为0即为不开启子进程,在主进程中进行数据加载
具体的config参考的ppocr文档中的解释,地址如下:
FCE Debug
首先,PaddleOCR的训练脚本再项目/tools/train.py中,再train.py中,我们重点关注main方法:
if __name__ == '__main__':
config, device, logger, vdl_writer = program.preprocess(is_train=True)
seed = config['Global']['seed'] if 'seed' in config['Global'] else 1024
set_seed(seed)
main(config, device, logger, vdl_writer)
再main方法中,先对训练环境初始化,并将解析读入的config文件传入对应组件的构造方法,这里注意的是,针对dataloader,model,postprocess,preprocess等等的训练组件,均在ppocr/组件名称/init.py中由build_组件名方法实现,以loss的构建方法为例:
在ppocr/losses/init.py文件中
# train.py中调用build_loss方法
loss_class = build_loss(config['Loss'])
# losses/init.py文件中对build_loss的实现
def build_loss(config):
support_dict = [
'DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', 'FCELoss', 'CTCLoss',
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss',
'TableMasterLoss', 'SPINAttentionLoss', 'VLLoss', 'StrokeFocusLoss',
'SLALoss', 'CTLoss', 'RFLLoss', 'DRRGLoss', 'CANLoss', 'TelescopeLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
assert module_name in support_dict, Exception('loss only support {}'.format(
support_dict))
module_class = eval(module_name)(**config)
return module_class
上面代码首先解析输入的config,从中拿到配置文件中loss的类名,并对类名进行验证,确保是支持的算法。
然后使用eval方法来实例化loss对象,这里实例化的类名与配置文件中的类名是对应的。
这样就构造了一个loss类,然后将它return。
paddleocr对其他所有组件的构造均是以上方式,可以在ppocr文件下的各个package的init.py文件中找到。
这里,实例化好所有组件的类之后,会调用下面代码开始训练:
# start train
program.train(config, train_dataloader, valid_dataloader, device, model,
loss_class, optimizer, lr_scheduler, post_process_class,
eval_class, pre_best_model_dict, logger, vdl_writer, scaler,
amp_level, amp_custom_black_list)
program类在tools/program.py文件中实现。
在program.train方法中,下面这个for循环实现整个训练过程:
for epoch in range(start_epoch, epoch_num + 1):
# 省略
for idx, batch in enumerate(train_dataloader):
# 省略
preds = model(images)
loss = loss_class(preds, batch)
avg_loss = loss['loss']
avg_loss.backward()
optimizer.step()
optimizer.clear_grad()
在训练的双重for循环中,batch进来的size为[4,3,800,800]
其中,4代表batch-size,3 表示channel,[800,800]表示经过图像增强后预处理的高宽。
batch中一共有4个list,batch[0]是待训练图片,batch[1-3]是不同尺度的mask图片。
之后会把images送入build好的model中进行预测

- Base_model
- backbone
- neck
- head
model返回的是head网络中经过整理的’levels’字段的数据他是一个长度为3的list,每个list中是一个长度为2的list分别是对应的cls分支特征图和reg分支的特征图。
Base_model
进入base_model类中的forward函数:

这里会根据配置文件中Architecture字段中配置的模型结构来对输入图像做前向传播。一般在检测任务中不会使用transform,因此x会输入近backbone中,该参数同样根据config文件指定的backbone类进行构造,在FCENet中使用的是ResNet_vd。我们只需要进入det_resnet_vd.py中查看结构。
backbone
FCENet使用的Backbone是ResNet50_vd。数据进入ResNet_vd类中的forward函数,shape为[4,3,800,800].
在forward函数中,数据首先经过三层conv1_x,这是ResNet_vd类属性,其类型为ConvBNLayer类。其初始化之后的结构如下:

ConvBNLayer类中,主要有三个layer结构,分别是
- AvgPool2D;
- 根据超参数选择的Conv2D或者DeformableConvV2
- 3.BatchNorm.
数据会根据配置中is_vd_mode来选择是否使用平均池化,并且在ConvBNLayer初始化时,会选择conv层。
在ResNet_vd类中先进入了conv1_1中。这里的例子是layer是Conv2D.
conv1_1中,会跳过平均池化,然后使用conv层,参数为out_channel=32, kernel_size=[3,3],stride=2,padding=1.因此执行之后数据shape变为[4,32,400,400].
conv1_2中,conv层的参数为out_channel=32,kernel_size=[3,3],stride=1,padding=1.因此经过conv1_2后数据shape仍为[4,32,400,400].
conv1_3中,conv层参数为out_channel=64,kernel_size=[3,3],stride=1,padding=1。只改变了通道数,特征图shape不变。
经过三层conv和bn层之后,会在过一层max_pool。max_pool的参数为kernel_size=3, stride=2, padding=1。输入backbone的数据shape会变成[4,64,200,200]。
这三层conv1_x和maxpool实现的是ResNet中block前的一些layer。可以见如下图:
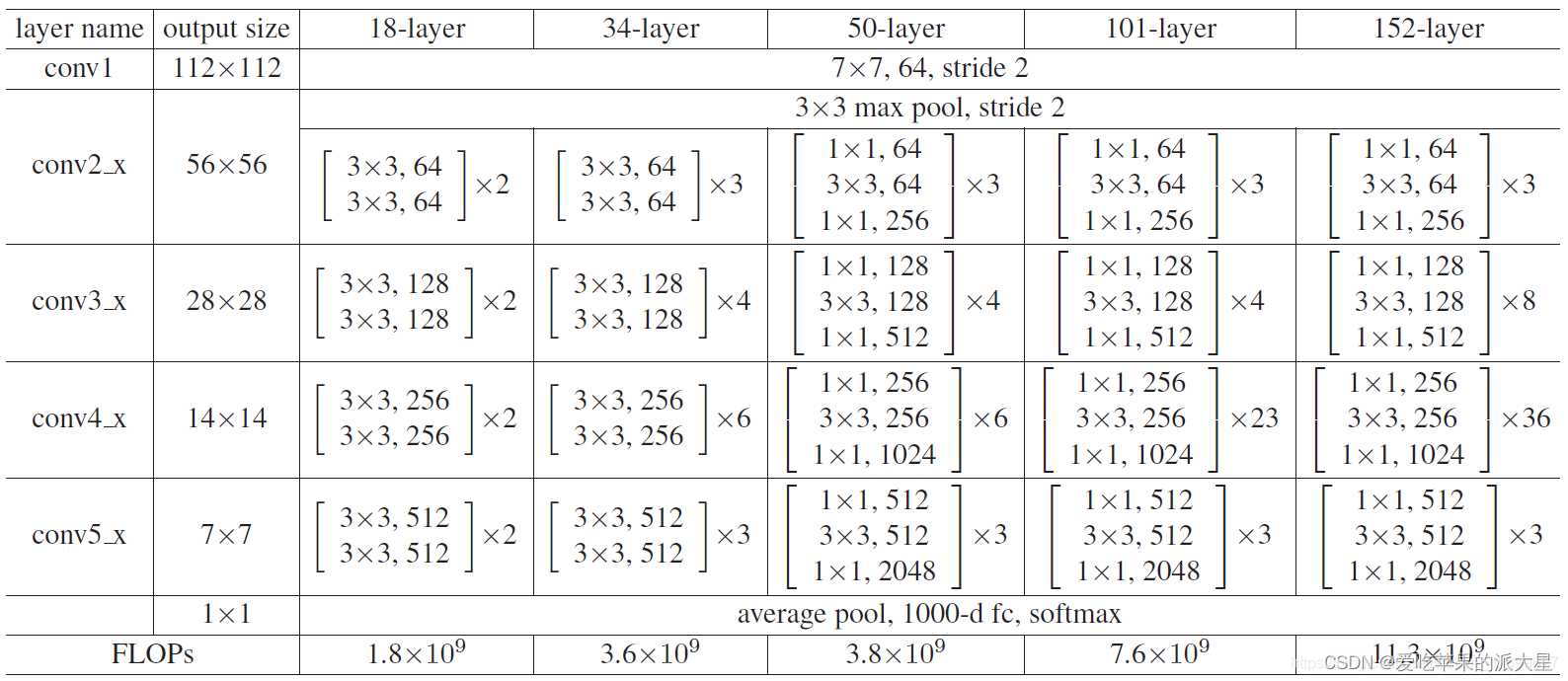
接下来一个for循环遍历block,完成ResNet的整体前向传播。会根据out_indices属性将不同尺度特征图进行输出。

block内具体的结构,参考ResNet_vd类的init方法。
stage结构:

4个block表示了上图中的conv2-conv5阶段。
经过backbone之后的图片,会分别下采样到8倍,16倍,32倍。因此self.backbone(x)的输出是一个len为3的list,其中:
- x[0]=[batch_size, 512, 100, 100]
- x[1]=[batch_size, 1024, 50, 50]
- x[2]=[batch_size, 2048, 25, 25]
通道数分别是512,1024,2048。
经过backbone后会对x的类型进行判断。
如果x是一个字典型,就将他更新到y中,如果不是,则y对应字段更新为x。
neck net
同样的方法会将backbone的输出送入neck中。
在fce_fpn中,先对输入body_feats的数据进行统计。确定level个数。
然后遍历每个level,分别将body_feats的对应level特征图送入对应 的lateral_convs中。见下图:

其中,lateral_convs是针对body_feats不同level特征图的一个1*1卷积,目的是为了统一特征图的channel数。

经过上边的for循环后,laterals列表中的元素如下:

它将不同尺度的特征图channel统一到了256.
接下来对特征图进行上采样,同过paddle.nn.functional中的interpolate函数。

首先倒序遍历特征图,然后对特征图进行上采样,最后将上采样特征图与浅层特征图进行特征融合。
因此在laterals中,只有laterals[0]、laterals[1]与深层特征图上采样结果进行了融合。
同时将laterals过一遍kernel_size=3*3, padding=1, stride=1的卷积,目的是平滑一下特征融合后的特征图。

通过解析可知,fce_fpn中,核心的是两个list,分别是lateral_convs和fpn_convs
head net
在det_fce_head中,FCEHead类的forward函数输入数据为feats。这里很玄学,使用了一个multi_apply函数完成了论文中对两个分支的前向传播,重点关注forward_single函数,以及forward函数后面针对训练和推理的不同分支走向。
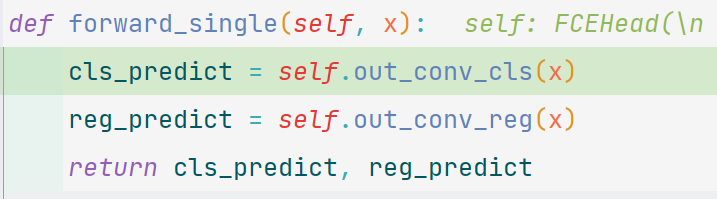
这个函数的作用就是将数据送入分类分支和回归分支。
Classsification Branch
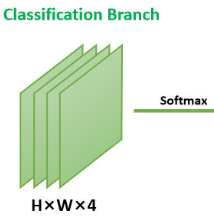
分类分支对应FCEHead类中的out_conv_cls属性,它是一个参数为inchannels=256,out_channels=4,kernel_size=3,stride=1,padding=1的卷积层。其输出是论文中的这个部分:
Regression Branch
回归分支对应FCEHead类中的out_conv_reg属性,它是一个参数为inchannels=256,out_channels=22(与配置文件中的fourier_degree字段有关,论文中指出傅里叶签名向量的长度为 v = 2 ∗ ( 2 ∗ K + 1 ) v=2*(2*K+1) v=2∗(2∗K+1)),kernel_size=3,stride=1,padding=1。其输出对应论文中的这个部分:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ULiHrVSt-1683620700184)(D:\研究生\论文\OCR\笔记\笔记图片暂存\regression_branch.png)]
下面是两个分支的输出结果:

在FCEHead类的forward函数中,经过分类分支和回归分支后,返回给model的数据结构如下:
out是一个字典,其中levels保存的是一个长度为3的list,列表的每个元素是一个长度为2的list,他存放对应尺度的分类特征图和回归特征图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J7hWLxq8-1683620700185)(D:\研究生\论文\OCR\笔记\笔记图片暂存\FCEHead返回数据结构.png)]
经过backbone、neck、head之后,得到的数据结构如下:

其中每个字段保存的是上述的输出结果。
FCE前处理阶段
- DecodeImage:
- DetLabelEncode:
- ColorJitter:
- RandomScaling:
- RandomCropFlip:
- RandomCropPolyInstances:
- RandomRotatePolyInstances:
- SquareResizePad:
- IaaAugment:
- CFPNetTargets:
- NormalizeImage:
- ToCHWImage:
- KeepKeys:
上面是config文件中配置的FCENet的前处理类,其中最重要的是CFPNetTargers(原项目中名字是FCENetTargets),他主要负责FCENet的ground truth target生成。具体步骤如下:
- 首先在generate_level_targets方法中,会计算每个文本实例的外接矩形,根据外接矩形的长宽比,将文本实例划分到不同的尺度下。
- 由于backbone中会选择不同的特征图,分别对应下采样8倍,16倍,32倍,generate_level_targets方法会根据文本实例的尺度大小,分别计算generate_text_region_mask文本区域mask,generate_center_region_mask文本中心区域mask,generate_effective_mask有效区域mask,generate_fourier_maps傅里叶map.
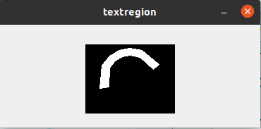
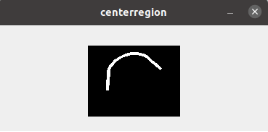
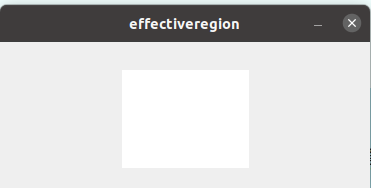
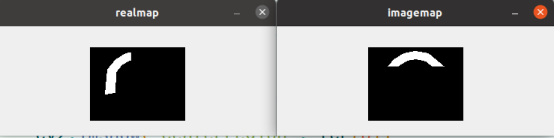
(傅里叶通道图有22个通道,这里只截取了其中一个通道)
在重采样阶段,原FCENet会根据文本实例框重采样,具体步骤是计算边框点之间的距离根据距离进行采样,默认采样400个点。
FCE后处理阶段
在执行推理的过程中,首先将输入图片转换成tensor,然后送进model类中得到模型推理后的特征图。

然后送入后处理类-fce_postprocess类中对得到的特征图进行傅里叶框的重建。
经过model推理得到包含3个尺度的预测特征图,每个尺度的特征图包含总共26个通道,分别对应网络结构中的4通道分类分支结果,22通道回归分支结果(这里傅里叶度取5,(2*5+1)*2=22)。

特征图大小对应输入图像下采样倍数。
进入后处理类后,首先对每个尺度特征图进行分类分支和回归分支的分离,然后调用类方法get_boundary生成文本框。
在get_boundary方法中,调用_get_boundary_single方法,最重要的是fcenet_decode方法,他将回归分支的结果解码为文本框的坐标。
在fcenet_decode方法中,先将所有特征图取出。

然后用文本区域图和文本中心图进行逐像素相乘,得到score_map,但是代码中只用了一个通道,将两个特征图的其他两个通道作废了。

得到score_pred后通过score_thr阈值来预测文本区域mask,tr_mask,然后使用opencv中的findContours找到文本区域的边框。
接下来遍历边框,将其绘制在deal_map上,然后deal_map与score_pred相乘,自我感觉这一步是获取文本边缘的得分。得到score_map,然后对score_map进行过滤得到score_mask。
使用numpy的argwhere函数,找到所有True值的索引,然后用索引的y值作为dxy的实部,用索引的x值作为dxy的虚部。[这里不是很明白颠倒xy顺序的原因]

由于用复数表示傅里叶系数时,实部表示余弦项系数,虚部表示正弦项系数,因此需要将 y 坐标放在实部,x 坐标放在虚部。
接着,从回归分支中取出xy的预测特征图,将其虚数化,组成c(即傅里叶系数)。
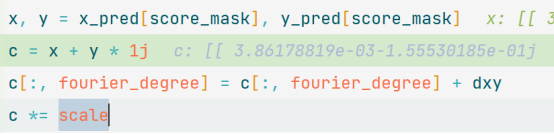
这里,x,y是根据score_mask取出的,即将文本区域tr计算得到的文本边缘的得分的mask矩阵,激活回归分支中傅里叶特征的向量。
Eg1,假如文本区域中得到了30个点的mask联通区域,那么会将这三十个点的联通区域对应的回归分支特征图上的特征向量取出,得到一个[30*11]矩阵,这里k傅里叶度取5,每行对应一个傅里叶特征,每一行相当于一个预测出的文本框。每列代表不同频率的傅里叶系数。[这里对加dxy不是很明白,同时也不清楚c *=scale的含义(可能是还原特征图尺度)]。
由于傅里叶级数拟合的过程中,只考虑了自然频率为非零的正弦和余弦波,因此无法表示多边形的平移。为了将多边形移动到正确的位置,需要在傅里叶系数中添加一个偏移量。因此,将 dxy 加到第 fourier_degree 个元素上,相当于将多边形的中心位置从原点移动到文本实例的中心位置。这里的 dxy 是一个包含像素点坐标的复数数组,每个元素的实部和虚部分别表示像素点在 x 轴和 y 轴上的偏移量。
然后将c和重建文本框点数num_reconstr_points(默认为50个点)传入fourier2poly方法,对傅里叶系数进行变换。
首先会创建出一个[len(傅里叶特征向量个数),num_reconstr_points]维度的a矩阵,这个矩阵是虚数形式的。
值得注意的是这里对a的赋值:

将傅里叶系数的5-11列赋值给a的0-5列,将傅里叶系数的0-4列赋值给a的45-49列,这里讨论的是固定参数下的赋值结果。
这样做是为了调整傅里叶系数的顺序,以便进行反傅里叶变换。 傅里叶级数展开的系数通常以复数形式表示,包括正频率和负频率的项。正频率对应于频谱中的正频率分量,负频率对应于频谱中的负频率分量。在实际计算中,为了方便处理,通常将傅里叶系数的正负频率部分分开存储。 在这个函数中,fourier_coeff 中的前半部分存储了负频率部分的系数,而后半部分存储了正频率部分的系数。通过将后半部分复制到数组 a 的前半部分,前半部分复制到数组 a 的后半部分,实际上是将正频率部分移动到了数组 a 的前半部分,将负频率部分移动到了数组 a 的后半部分。
接着,使用傅里叶反变换得到文本实例的预测结果。

乘以 num_reconstr_points 是为了校准坐标的范围。 在进行傅里叶变换时,频域上的信号通常会被归一化,即将信号的振幅范围缩放到一定范围内。反傅里叶变换则是将归一化的频域信号转换回时域信号。 通过乘以 num_reconstr_points,可以将反傅里叶变换得到的复数形式的多边形坐标进行放缩,使其适应实际的坐标范围。 保持反傅里叶变换后多边形坐标的比例和大小与原始数据一致。使得重建的多边形与原始多边形具有相似的形状和比例关系。
以Eg1为例,Poly_complex是一个30*50的虚数矩阵,每行代表一个文本框。

创建一个形状为 (n, num_reconstr_points, 2) 的全零数组 polygon,用于存储多边形的坐标。其中第一个维度表示候选文本实例的数量,第二个维度表示多边形点的数量,第三个维度表示坐标的维度(x 和 y)。
最后将文本实例形状调整形状为 (n, -1),-1是将剩余维度展平。得到的是30*100的向量,每行表示一个文本实例。
最重点的就结束了,剩下的就是使用nms来对得到的文本框进行过滤选择置信度或者得分最大的。这里的置信度就是score_map中激活位置在score_mask上的得分。
需要注意的是,后处理中,先是对每个实例进行nms过滤,然后在不同尺度上在对IOU重合度大的进行过滤。
近年CVPR关于OCR检测和识别的论文
2021
场景文本检测
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
FCENet
- Paper: https://arxiv.org/abs/2104.10442
场景文本识别
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
ABINet
-
Paper: https://arxiv.org/abs/2103.06495
-
Code: https://github.com/FangShancheng/ABINet
2022
端到端文本识别
SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition
- Paper: https://arxiv.org/abs/2203.10209
- Code: https://github.com/mxin262/SwinTextSpotter




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











